
配置文件及参数重写
本小节介绍 Kylin 的配置文件和如何进行配置重写。
Kylin 配置文件
Kylin 会自动从环境中读取 Hadoop 配置(core-site.xml),Hive 配置(hive-site.xml)和 HBase 配置(hbase-site.xml),另外,Kylin 的配置文件在 $KYLIN_HOME/conf/ 目录下,如下:
kylin_hive_conf.xml:该文件包含了 Hive 任务的配置项。kylin_job_conf.xml&kylin_job_conf_inmem.xml:该文件包含了 MapReduce 任务的配置项。当执行 In-mem Cubing 任务时,需要在kylin_job_conf_inmem.xml中为 mapper 申请更多的内存kylin-kafka-consumer.xml:该文件包含了 Kafka 任务的配置项。kylin-server-log4j.properties:该文件包含了 Kylin 服务器的日志配置项。kylin-tools-log4j.properties:该文件包含了 Kylin 命令行的日志配置项。setenv.sh:该文件是用于设置环境变量的 shell 脚本,可以通过KYLIN_JVM_SETTINGS调整 Kylin JVM 栈的大小,且可以设置KAFKA_HOME等其他环境变量。kylin.properties:该文件是 Kylin 使用的全局配置文件。
配置重写
$KYLIN_HOME/conf/ 中有部分配置项可以在 Web UI 界面进行重写,配置重写分为项目级别配置重写和 Cube 级别配置重写。配置重写的优先级关系为:Cube 级别配置重写 > 项目级别配置重写 > 全局配置文件。
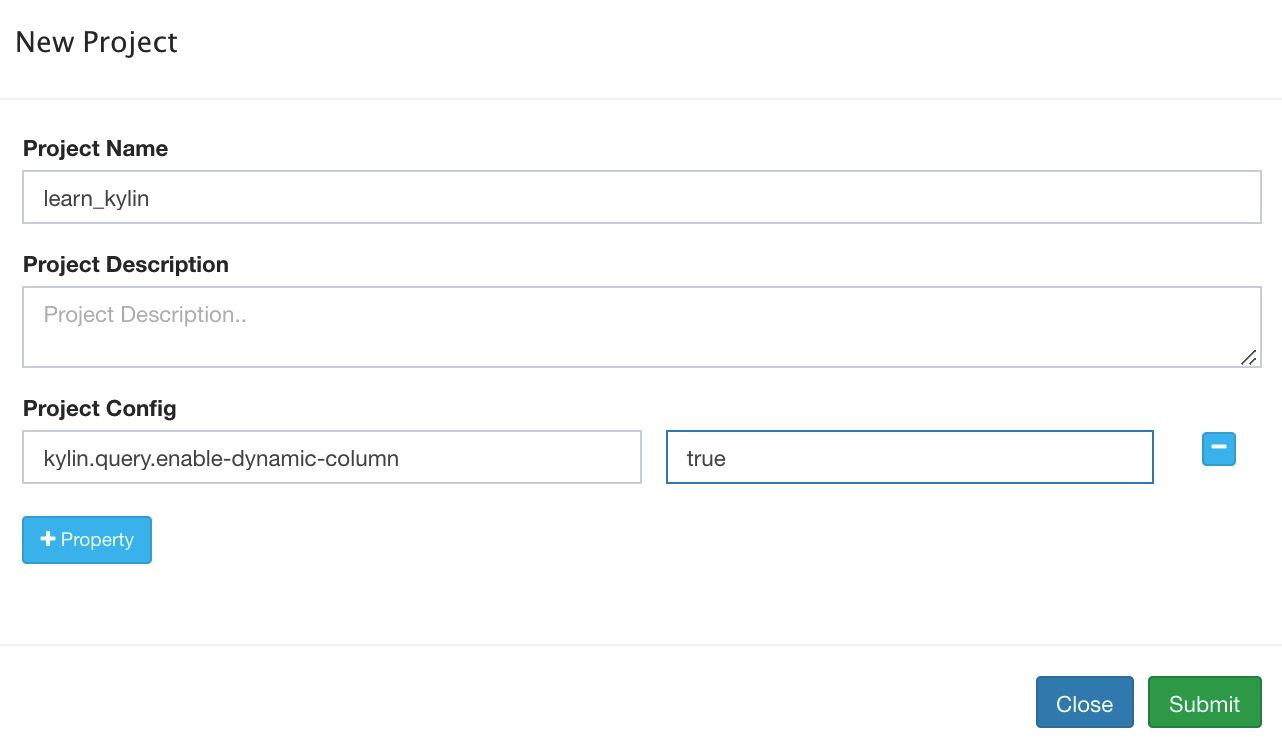
项目级别配置重写
在 Web UI 界面点击 Manage Project ,选中某个项目,点击 Edit -> Project Config -> + Property,进行项目级别的配置重写,如下图所示:
Cube 级别配置重写
在设计 Cube (Cube Designer)的 Configuration Overwrites 步骤可以添加配置项,进行 Cube 级别的配置重写,如下图所示:

以下参数可以在 Cube 级别重写:
kylin.cube.size-estimate*kylin.cube.algorithm*kylin.cube.aggrgroup*kylin.metadata.dimension-encoding-max-lengthkylin.cube.max-building-segmentskylin.cube.is-automerge-enabledkylin.job.allow-empty-segmentkylin.job.sampling-percentagekylin.source.hive.redistribute-flat-tablekylin.engine.spark*kylin.query.skip-empty-segments
MapReduce 任务配置重写
Kylin 支持在项目和 Cube 级别重写 kylin_job_conf.xml 和 kylin_job_conf_inmem.xml 中参数,以键值对的性质,按照如下格式替换:
kylin.engine.mr.config-override.<key> = <value>
* 如果用户希望任务从 Yarn 获得更多内存,可以这样设置:
kylin.engine.mr.config-override.mapreduce.map.java.opts=-Xmx7g 和 kylin.engine.mr.config-override.mapreduce.map.memory.mb=8192
* 如果用户希望 Cube 的构建任务使用不同的 YARN resource queue,可以设置:
kylin.engine.mr.config-override.mapreduce.job.queuename={queueName}
Hive 任务配置重写
Kylin 支持在项目和 Cube 级别重写 kylin_hive_conf.xml 中参数,以键值对的性质,按照如下格式替换:
kylin.source.hive.config-override.<key> = <value>
如果用户希望 Hive 使用不同的 YARN resource queue,可以设置:
kylin.source.hive.config-override.mapreduce.job.queuename={queueName}
Spark 任务配置重写
Kylin 支持在项目和 Cube 级别重写 kylin.properties 中的 Spark 参数,以键值对的性质,按照如下格式替换:
kylin.engine.spark-conf.<key> = <value>
如果用户希望 Spark 使用不同的 YARN resource queue,可以设置:
kylin.engine.spark-conf.spark.yarn.queue={queueName}
部署配置
本小节介绍部署 Kylin 相关的配置。
部署 Kylin
kylin.env.hdfs-working-dir:指定 Kylin 服务所用的 HDFS 路径,默认值为/kylin,请确保启动 Kylin 实例的用户有读写该目录的权限kylin.env:指定 Kylin 部署的用途,参数值可选DEV,QA,PROD,默认值为DEV,在 DEV 模式下一些开发者功能将被启用kylin.env.zookeeper-base-path:指定 Kylin 服务所用的 ZooKeeper 路径,默认值为/kylinkylin.env.zookeeper-connect-string:指定 ZooKeeper 连接字符串,如果为空,使用 HBase 的 ZooKeeperkylin.env.hadoop-conf-dir:指定 Hadoop 配置文件目录,如果不指定的话,获取环境中的HADOOP_CONF_DIRkylin.server.mode:指定 Kylin 实例的运行模式,参数值可选all,job,query,默认值为all,job 模式代表该服务仅用于任务调度,不用于查询;query 模式代表该服务仅用于查询,不用于构建任务的调度;all 模式代表该服务同时用于任务调度和 SQL 查询。kylin.server.cluster-name:指定集群名称
分配更多内存给 Kylin 实例
在 $KYLIN_HOME/conf/setenv.sh 中存在对 KYLIN_JVM_SETTINGS 的两种示例配置。
默认配置使用的内存较少,用户可以根据自己的实际情况,注释掉默认配置并取消另一配置前的注释符号以启用另一配置,从而为 Kylin 实例分配更多的内存资源,该项配置的默认值如下:
export KYLIN_JVM_SETTINGS="-Xms1024M -Xmx4096M -Xss1024K -XX`MaxPermSize=512M -verbose`gc -XX`+PrintGCDetails -XX`+PrintGCDateStamps -Xloggc`$KYLIN_HOME/logs/kylin.gc.$$ -XX`+UseGCLogFileRotation -XX`NumberOfGCLogFiles=10 -XX`GCLogFileSize=64M"
# export KYLIN_JVM_SETTINGS="-Xms16g -Xmx16g -XX`MaxPermSize=512m -XX`NewSize=3g -XX`MaxNewSize=3g -XX`SurvivorRatio=4 -XX`+CMSClassUnloadingEnabled -XX`+CMSParallelRemarkEnabled -XX`+UseConcMarkSweepGC -XX`+CMSIncrementalMode -XX`CMSInitiatingOccupancyFraction=70 -XX`+UseCMSInitiatingOccupancyOnly -XX`+DisableExplicitGC -XX`+HeapDumpOnOutOfMemoryError -verbose`gc -XX`+PrintGCDetails -XX`+PrintGCDateStamps -Xloggc`$KYLIN_HOME/logs/kylin.gc.$$ -XX`+UseGCLogFileRotation -XX`NumberOfGCLogFiles=10 -XX`GCLogFileSize=64M"
任务引擎高可用
kylin.job.scheduler.default=2:启用分布式任务调度器kylin.job.lock=org.apache.kylin.storage.hbase.util.ZookeeperJobLock:开启分布式任务锁
提示:更多信息请参考 集群模式部署 中的任务引擎高可用部分。
任务引擎安全模式
安全模式仅在默认调度器中生效
kylin.job.scheduler.safemode=TRUE: 启用安全模式,新提交的任务不会被执行。kylin.job.scheduler.safemode.runable-projects=project1,project2: 安全模式下仍然可以执行的项目列表,支持设置多个。
读写分离配置
kylin.storage.hbase.cluster-fs:指明 HBase 集群的 HDFS 文件系统kylin.storage.hbase.cluster-hdfs-config-file:指向 HBase 集群的 HDFS 配置文件
提示:更多信息请参考 Deploy Apache Kylin with Standalone HBase Cluster
RESTful Webservice
kylin.web.timezone:指定 Kylin 的 REST 服务所使用的时区,默认值为 GMT+8kylin.web.cross-domain-enabled:是否支持跨域访问,默认值为 TRUEkylin.web.export-allow-admin:是否支持管理员用户导出信息,默认值为 TRUEkylin.web.export-allow-other:是否支持其他用户导出信息,默认值为 TRUEkylin.web.dashboard-enabled:是否启用 Dashboard,默认值为 FALSE
Metastore 配置
本小节介绍 Kylin Metastore 相关的配置。
元数据相关
kylin.metadata.url:指定元数据库路径,默认值为 kylin_metadata@hbasekylin.metadata.sync-retries:指定元数据同步重试次数,默认值为 3kylin.metadata.sync-error-handler:默认值为DefaultSyncErrorHandlerkylin.metadata.check-copy-on-write:清除元数据缓存,默认值为FALSEkylin.metadata.hbase-client-scanner-timeout-period:表示 HBase 客户端发起一次 scan 操作的 RPC 调用至得到响应之间总的超时时间,默认值为 10000(ms)kylin.metadata.hbase-rpc-timeout:指定 HBase 执行 RPC 操作的超时时间,默认值为 5000(ms)kylin.metadata.hbase-client-retries-number:指定 HBase 重试次数,默认值为 1(次)kylin.metadata.resource-store-provider.jdbc:指定 JDBC 使用的类,默认值为org.apache.kylin.common.persistence.JDBCResourceStore
基于 MySQL 的 Metastore
kylin.metadata.url:指定元数据路径kylin.metadata.jdbc.dialect:指定 JDBC 方言kylin.metadata.jdbc.json-always-small-cell:默认值为 TRUEkylin.metadata.jdbc.small-cell-meta-size-warning-threshold:默认值为 100(MB)kylin.metadata.jdbc.small-cell-meta-size-error-threshold:默认值为 1(GB)kylin.metadata.jdbc.max-cell-size:默认值为 1(MB)kylin.metadata.resource-store-provider.jdbc:指定 JDBC 使用的类,默认值为 org.apache.kylin.common.persistence.JDBCResourceStore
提示:更多信息请参考基于 MySQL 的 Metastore 配置
构建配置
本小节介绍 Kylin 数据建模及构建相关的配置。
Hive 客户端 & SparkSQL
kylin.source.hive.client:指定 Hive 命令行类型,参数值可选 cli 或 beeline,默认值为 clikylin.source.hive.beeline-shell:指定 Beeline shell 的绝对路径,默认值为 beelinekylin.source.hive.beeline-params:当使用 Beeline 做为 Hive 的 Client 工具时,需要配置此参数,以提供更多信息给 Beelinekylin.source.hive.enable-sparksql-for-table-ops:默认值为 FALSE,当使用 SparkSQL 时需要设置为 TRUEkylin.source.hive.sparksql-beeline-shell:当使用 SparkSQL Beeline 做为 Hive 的 Client 工具时,需要配置此参数为 /path/to/spark-client/bin/beelinekylin.source.hive.sparksql-beeline-params:当使用 SparkSQL Beeline 做为 Hive 的 Client 工具时,需要配置此参数
配置 JDBC 数据源
kylin.source.default:JDBC 使用的数据源种类kylin.source.jdbc.connection-url:JDBC 连接字符串kylin.source.jdbc.driver:JDBC 驱动类名kylin.source.jdbc.dialect:JDBC方言,默认值为 defaultkylin.source.jdbc.user:JDBC 连接用户名kylin.source.jdbc.pass:JDBC 连接密码kylin.source.jdbc.sqoop-home:Sqoop 安装路径kylin.source.jdbc.sqoop-mapper-num:指定应该分为多少个切片,Sqoop 将为每一个切片运行一个 mapper,默认值为 4kylin.source.jdbc.field-delimiter:指定字段分隔符, 默认值为 \
提示:更多信息请参考建立 JDBC 数据源。
数据类型精度
kylin.source.hive.default-varchar-precision:指定 varchar 字段的最大长度,默认值为256kylin.source.hive.default-char-precision:指定 char 字段的最大长度,默认值为 255kylin.source.hive.default-decimal-precision:指定 decimal 字段的精度,默认值为 19kylin.source.hive.default-decimal-scale:指定 decimal 字段的范围,默认值为 4
Cube 设计
kylin.cube.ignore-signature-inconsistency:Cube desc 中的 signature 信息能保证 Cube 不被更改为损坏状态,默认值为 FALSEkylin.cube.aggrgroup.max-combination:指定一个 Cube 的聚合组 Cuboid 上限,默认值为 32768kylin.cube.aggrgroup.is-mandatory-only-valid:是否允许 Cube 只包含 Base Cuboid,默认值为 FALSE,当使用 Spark Cubing 时需设置为 TRUEkylin.cube.rowkey.max-size:指定可以设置为 Rowkeys 的最大列数,默认值为 63,且最大不能超过 63kylin.cube.allow-appear-in-multiple-projects:是否允许一个 Cube 出现在多个项目中kylin.cube.gtscanrequest-serialization-level:默认值为 1kylin.metadata.dimension-encoding-max-length:指定维度作为 Rowkeys 时使用 fix_length 编码时的最大长度,默认值为 256kylin.web.hide-measures: 隐藏一些可能不需要的度量,默认值是RAW
Cube 大小估计
Kylin 和 HBase 都在写入磁盘时使用压缩,因此,Kylin 将在其原来的大小上乘以比率来估计 Cube 大小。
kylin.cube.size-estimate-ratio:普通的 Cube,默认值为 0.25kylin.cube.size-estimate-memhungry-ratio:已废弃,默认值为 0.05kylin.cube.size-estimate-countdistinct-ratio:包含精确去重度量的 Cube 大小估计,默认值为 0.5kylin.cube.size-estimate-topn-ratio:包含 TopN 度量的 Cube 大小估计,默认值为 0.5
Cube 构建算法
kylin.cube.algorithm:指定 Cube 构建的算法,参数值可选auto,layer和inmem, 默认值为 auto,即 Kylin 会通过采集数据动态地选择一个算法 (layer or inmem),如果用户很了解 Kylin 和自身的数据、集群,可以直接设置喜欢的算法kylin.cube.algorithm.layer-or-inmem-threshold:默认值为 7kylin.cube.algorithm.inmem-split-limit:默认值为 500kylin.cube.algorithm.inmem-concurrent-threads:默认值为 1kylin.job.sampling-percentage:指定数据采样百分比,默认值为 100
自动合并
kylin.cube.is-automerge-enabled:是否启用自动合并,默认值为 TRUE,将该参数设置为 FALSE 时,自动合并功能会被关闭,即使 Cube 设置中开启了自动合并、设置了自动合并阈值,也不会触发合并任务。
维表快照
kylin.snapshot.max-mb:允许维表的快照大小的上限,默认值为 300(M)kylin.snapshot.max-cache-entry:缓存中最多可以存储的 snapshot 数量,默认值为 500kylin.snapshot.ext.shard-mb:设置存储维表快照的 HBase 分片大小,默认值为 500(M)kylin.snapshot.ext.local.cache.path:本地缓存路径,默认值为 lookup_cachekylin.snapshot.ext.local.cache.max-size-gb:本地维表快照缓存大小,默认值为 200(M)
Cube 构建
kylin.storage.default:指定默认的构建引擎,默认值为 2,即 HBasekylin.source.hive.keep-flat-table:是否在构建完成后保留 Hive 中间表,默认值为 FALSEkylin.source.hive.database-for-flat-table:指定存放 Hive 中间表的 Hive 数据库名字,默认值为 default,请确保启动 Kylin 实例的用户有操作该数据库的权限kylin.source.hive.flat-table-storage-format:指定 Hive 中间表的存储格式,默认值为 SEQUENCEFILEkylin.source.hive.flat-table-field-delimiter:指定 Hive 中间表的分隔符,默认值为 \u001Fkylin.source.hive.intermediate-table-prefix:指定 Hive 中间表的表名前缀,默认值为 kylin_intermediate_kylin.source.hive.redistribute-flat-table:是否重分配 Hive 平表,默认值为 TRUEkylin.source.hive.redistribute-column-count:重分配列的数量,默认值为 3kylin.source.hive.table-dir-create-first:默认值为 FALSEkylin.storage.partition.aggr-spill-enabled:默认值为 TRUEkylin.engine.mr.lib-dir:指定 MapReduce 任务所使用的 jar 包的路径kylin.engine.mr.reduce-input-mb:MapReduce 任务启动前会依据输入预估 Reducer 接收数据的总量,再除以该参数得出 Reducer 的数目,默认值为 500(MB)kylin.engine.mr.reduce-count-ratio:用于估算 Reducer 数目,默认值为 1.0kylin.engine.mr.min-reducer-number:MapReduce 任务中 Reducer 数目的最小值,默认值为 1kylin.engine.mr.max-reducer-number:MapReduce 任务中 Reducer 数目的最大值,默认值为 500kylin.engine.mr.mapper-input-rows:每个 Mapper 可以处理的行数,默认值为 1000000,如果将这个值调小,会起更多的 Mapperkylin.engine.mr.max-cuboid-stats-calculator-number:用于计算 Cube 统计数据的线程数量,默认值为 1kylin.engine.mr.build-dict-in-reducer:是否在构建任务 Extract Fact Table Distinct Columns 的 Reduce 阶段构建字典,默认值为 TRUEkylin.engine.mr.yarn-check-interval-seconds:构建引擎间隔多久检查 Hadoop 任务的状态,默认值为 10(s)kylin.engine.mr.use-local-classpath: 是否使用本地 mapreduce 应用的 classpath。默认值为 TRUE
字典相关
kylin.dictionary.use-forest-trie:默认值为 TRUEkylin.dictionary.forest-trie-max-mb:默认值为 500kylin.dictionary.max-cache-entry:默认值为 3000kylin.dictionary.growing-enabled:默认值为 FALSEkylin.dictionary.append-entry-size:默认值为 10000000kylin.dictionary.append-max-versions:默认值为 3kylin.dictionary.append-version-ttl:默认值为 259200000kylin.dictionary.resuable:是否重用字典,默认值为 FALSEkylin.dictionary.shrunken-from-global-enabled:是否缩小全局字典,默认值为 TRUE
超高基维度的处理
Cube 构建默认在 Extract Fact Table Distinct Column 这一步为每一列分配一个 Reducer,对于超高基维度,可以通过以下参数增加 Reducer 个数
kylin.engine.mr.build-uhc-dict-in-additional-step:默认值为 FALSE,设置为 TRUEkylin.engine.mr.uhc-reducer-count:默认值为 1,可以设置为 5,即为每个超高基的列分配 5 个 Reducer。
Spark 构建引擎
kylin.engine.spark-conf.spark.master:指定 Spark 运行模式,默认值为 yarnkylin.engine.spark-conf.spark.submit.deployMode:指定 Spark on YARN 的部署模式,默认值为 clusterkylin.engine.spark-conf.spark.yarn.queue:指定 Spark 资源队列,默认值为 defaultkylin.engine.spark-conf.spark.driver.memory:指定 Spark Driver 内存大小,默认值为 2Gkylin.engine.spark-conf.spark.executor.memory:指定 Spark Executor 内存大小,默认值为 4Gkylin.engine.spark-conf.spark.yarn.executor.memoryOverhead:指定 Spark Executor 堆外内存大小,默认值为 1024(MB)kylin.engine.spark-conf.spark.executor.cores:指定单个 Spark Executor可用核心数,默认值为 1kylin.engine.spark-conf.spark.network.timeout:指定 Spark 网络超时时间,600kylin.engine.spark-conf.spark.executor.instances:指定一个 Application 拥有的 Spark Executor 数量,默认值为 1kylin.engine.spark-conf.spark.eventLog.enabled:是否记录 Spark 时间,默认值为 TRUEkylin.engine.spark-conf.spark.hadoop.dfs.replication:HDFS 的副本数,默认值为 2kylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress:是否压缩输出,默认值为 TRUEkylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress.codec:输出所用压缩,默认值为 org.apache.hadoop.io.compress.DefaultCodeckylin.engine.spark.rdd-partition-cut-mb:Kylin 用该参数的大小来分割 partition,默认值为 10(MB),可以在 Cube 级别重写这个参数,调整至更大,来减少分区数kylin.engine.spark.min-partition:最小分区数,默认值为 1kylin.engine.spark.max-partition:最大分区数,默认值为 5000kylin.engine.spark.storage-level:RDD 分区数据缓存级别,默认值为 MEMORY_AND_DISK_SERkylin.engine.spark-conf-mergedict.spark.executor.memory:为合并字典申请更多的内存,默认值为 6Gkylin.engine.spark-conf-mergedict.spark.memory.fraction:给系统预留的内存百分比,默认值为 0.2
提示:更多信息请参考 用 Spark 构建 Cube。
通过 Livy 提交 Spark 任务
kylin.engine.livy-conf.livy-enabled:是否开启 Livy 进行 Spark 任务的提交。默认值为 FALSEkylin.engine.livy-conf.livy-url:指定了 Livy 的 URL。例如 http://127.0.0.1:8998kylin.engine.livy-conf.livy-key.*:指定了 Livy 的 name-key 配置。例如 kylin.engine.livy-conf.livy-key.name=kylin-livy-1kylin.engine.livy-conf.livy-arr.*:指定了 Livy 数组类型的配置。以逗号分隔。例如 kylin.engine.livy-conf.livy-arr.jars=hdfs://your_self_path/hbase-common-1.4.8.jar,hdfs://your_self_path/hbase-server-1.4.8.jar,hdfs://your_self_path/hbase-client-1.4.8.jarkylin.engine.livy-conf.livy-map.*:指定了 Spark 配置。例如 kylin.engine.livy-conf.livy-map.spark.executor.instances=10
提示:更多信息请参考 Apache Livy Rest API。
Spark 资源动态分配
kylin.engine.spark-conf.spark.shuffle.service.enabled:是否开启 shuffle servicekylin.engine.spark-conf.spark.dynamicAllocation.enabled:是否启用 Spark 资源动态分配kylin.engine.spark-conf.spark.dynamicAllocation.initialExecutors:如果所有的 Executor 都移除了,重新请求启动时初始 Executor 数量kylin.engine.spark-conf.spark.dynamicAllocation.minExecutors:最少保留的 Executor 数量kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors:最多申请的 Executor 数量kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout:Executor 空闲时间超过设置的值后,除非有缓存数据,不然会被移除,默认值为 60(s)
提示:更多信息请参考 Dynamic Resource Allocation。
任务相关
kylin.job.log-dir:默认值为 /tmp/kylin/logskylin.job.allow-empty-segment:是否容忍数据源为空,默认值为 TRUEkylin.job.max-concurrent-jobs:最大构建并发数,默认值为 10kylin.job.retry:构建任务失败后的重试次数,默认值为 0kylin.job.retry-interval: 每次重试的间隔毫秒数。默认值为 30000kylin.job.scheduler.priority-considered:是否考虑任务优先级,默认值为 FALSEkylin.job.scheduler.priority-bar-fetch-from-queue:指定从优先级队列中获取任务的时间间隔,默认值为 20(s)kylin.job.scheduler.poll-interval-second:从队列中获取任务的时间间隔,默认值为 30(s)kylin.job.error-record-threshold:指定任务抛出错误信息的阈值,默认值为 0kylin.job.cube-auto-ready-enabled:是否在构建完成后自动启用 Cube,默认值为 TRUEkylin.cube.max-building-segments:指定对同一个 Cube 的最大构建数量,默认值为 10
启用邮件通知
kylin.job.notification-enabled:是否在任务成功或者失败时进行邮件通知,默认值为 FALSEkylin.job.notification-mail-enable-starttls:# 是否启用 starttls,默认值为 FALSEkylin.job.notification-mail-host:指定邮件的 SMTP 服务器地址kylin.job.notification-mail-port:指定邮件的 SMTP 服务器端口,默认值为 25kylin.job.notification-mail-username:指定邮件的登录用户名kylin.job.notification-mail-password:指定邮件的用户名密码kylin.job.notification-mail-sender:指定邮件的发送邮箱地址kylin.job.notification-admin-emails:指定邮件通知的管理员邮箱
启用 Cube Planner
kylin.cube.cubeplanner.enabled:默认值为 TRUEkylin.server.query-metrics2-enabled:默认值为 TRUEkylin.metrics.reporter-query-enabled:默认值为 TRUEkylin.metrics.reporter-job-enabled:默认值为 TRUEkylin.metrics.monitor-enabled:默认值为 TRUEkylin.cube.cubeplanner.enabled:是否启用 Cube Planner,默认值为 TRUEkylin.cube.cubeplanner.enabled-for-existing-cube:是否对已有的 Cube 启用 Cube Planner,默认值为 TRUEkylin.cube.cubeplanner.algorithm-threshold-greedy:默认值为 8kylin.cube.cubeplanner.expansion-threshold:默认值为 15.0kylin.cube.cubeplanner.recommend-cache-max-size:默认值为 200kylin.cube.cubeplanner.query-uncertainty-ratio:默认值为 0.1kylin.cube.cubeplanner.bpus-min-benefit-ratio:默认值为 0.01kylin.cube.cubeplanner.algorithm-threshold-genetic:默认值为 23
提示:更多信息请参考 使用 Cube Planner。
HBase 存储
kylin.storage.hbase.table-name-prefix:默认值为 KYLIN_kylin.storage.hbase.namespace:指定 HBase 存储默认的 namespace,默认值为 defaultkylin.storage.hbase.coprocessor-local-jar:指向 HBase 协处理器有关 jar 包kylin.storage.hbase.coprocessor-mem-gb:设置 HBase 协处理器内存大小,默认值为 3.0(GB)kylin.storage.hbase.run-local-coprocessor:是否运行本地 HBase 协处理器,默认值为 FALSEkylin.storage.hbase.coprocessor-timeout-seconds:设置超时时间,默认值为 0kylin.storage.hbase.region-cut-gb:单个 Region 的大小,默认值为 5.0kylin.storage.hbase.min-region-count:指定最小 Region 个数,默认值为 1kylin.storage.hbase.max-region-count:指定最大 Region 个数,默认值为 500kylin.storage.hbase.hfile-size-gb:指定 HFile 大小,默认值为 2.0(GB)kylin.storage.hbase.max-scan-result-bytes:指定扫描返回结果的最大值,默认值为 5242880(byte),即 5(MB)kylin.storage.hbase.compression-codec:是否压缩,默认值为 none,即不开启压缩kylin.storage.hbase.rowkey-encoding:指定 Rowkey 的编码方式,默认值为 FAST_DIFFkylin.storage.hbase.block-size-bytes:默认值为 1048576kylin.storage.hbase.small-family-block-size-bytes:指定 Block 大小,默认值为 65536(byte),即 64(KB)kylin.storage.hbase.owner-tag:指定 Kylin 平台的所属人,默认值为 whoami@kylin.apache.orgkylin.storage.hbase.endpoint-compress-result:是否返回压缩结果,默认值为 TRUEkylin.storage.hbase.max-hconnection-threads:指定连接线程数量的最大值,默认值为 2048kylin.storage.hbase.core-hconnection-threads:指定核心连接线程的数量,默认值为 2048kylin.storage.hbase.hconnection-threads-alive-seconds:指定线程存活时间,默认值为 60kylin.storage.hbase.replication-scope:指定集群复制范围,默认值为 0kylin.storage.hbase.scan-cache-rows:指定扫描缓存行数,默认值为 1024
备用 Hbase 存储
Kylin支持用户配置备用Hbase,这样在集群迁移时,Kylin仍然可以从旧集群中查询到构建好的Cube数据。
kylin.secondary.storage.url: 指定备用Hbase的集群地址以及metadata url,zookeeper信息. 例如 kylin.secondary.storage.url=hostname:kylin_metadata@hbase,hbase.zookeeper.quorum=hostname:11000,zookeeper.znode.parent=/hbase/.如果还有其他的配置项,可以以= 的形式添加在后面.
提示:更多信息请参考 KYLIN-4175。
任务输出
为了避免job output的内容太多,用户可以设置output的最大长度。
kylin.job.execute-output.max-size: Job output的最大长度. 默认值为10484760.kylin.engine.spark.output.max-size: Spark job output的最大长度. 默认值为10484760.
启用压缩
Kylin 在默认状态下不会启用压缩,不支持的压缩算法会阻碍 Kylin 的构建任务,但是一个合适的压缩算法可以减少存储开销和网络开销,提高整体系统运行效率。
Kylin 可以使用三种类型的压缩,分别是 HBase 表压缩,Hive 输出压缩 和 MapReduce 任务输出压缩。
注意:压缩设置只有在重启 Kylin 实例后才会生效。
- HBase 表压缩
该项压缩通过 kyiln.properties 中的 kylin.storage.hbase.compression-codec 进行配置,参数值可选 none,snappy, lzo, gzip, lz4),默认值为 none,即不压缩数据。
注意:在修改压缩算法前,请确保用户的 HBase 集群支持所选压缩算法。
- Hive 输出压缩
该项压缩通过 kylin_hive_conf.xml 进行配置,默认配置为空,即直接使用了 Hive 的默认配置。如果想重写配置,请在 kylin_hive_conf.xml 中添加 (或替换) 下列属性。以 SNAPPY 压缩为例:
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description></description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description></description>
</property>
- MapReduce 任务输出压缩
该项压缩通过 kylin_job_conf.xml 和 kylin_job_conf_inmem.xml 进行配置。默认值为空,即使用 MapReduce 的默认配置。如果想重写配置,请在 kylin_job_conf.xml 和 kylin_job_conf_inmem.xml 中添加 (或替换) 下列属性。以 SNAPPY 压缩为例:
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description></description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description></description>
</property>
实时 OLAP
全局设置
kylin.stream.job.dfs.block.size: 指定了流式构建 Cuboid 任务所需 HDFS 块的大小。默认值为 16M。kylin.stream.index.path: 指定了存储segment cache file的本地路径(包括本地fragment file和checkpoint file)。支持相对路径和绝对路径,默认值是 stream_index,也就是写到$KYLIN_HOME/stream_index,如果数据量很大的话将会占用大量磁盘空间,您也可以根据您的需求写成绝对路径以将数据放到数据盘。kylin.stream.node: 指定了 receiver/coordinator的地址。格式应该为hostname:port或者port。如果设置成port,Kylin将会自动补全hostname;如果不设置该属性,将会使用默认的端口(Coordinator:7070,Receiver:9090)。当进程启动时,会将自身注册到Metadata。kylin.stream.metadata.store.type: 指定了Realtime集群信息的元数据存储。默认值是 zk。kylin.stream.receiver.use-threads-per-query: 指定了每个查询使用的线程资源数量。默认值是8。
Cube 级别设置
kylin.stream.index.maxrows: 指定了缓存在堆内的聚合后的事件最大行数。默认值是50000。这个参数会影响Fragment File的数量,可以根据需求适当调高。kylin.stream.cube-num-of-consumer-tasks: 指定了一个topic的全部消息的摄入将由哪多少Replica Set来负责。如果您的消息速率较大,需要适当提升这个数值。默认值是3。kylin.stream.segment.retention.policy: 当Segment状态变为IMMUTABLE,该配置指定了Receiver如何处理本地Segment Cache。可选值包含purge和fullBuild。设置为purge后,Receiver会等待一定时间后删除本地数据;设置为fullBuild后,数据会上传到HDFS并等待构建。默认值是fullBuild。kylin.stream.build.additional.cuboids: 默认情况下Receiver只构建base cuboid来回答查询,可以在Receiver端是否构建额外的cuboid,如果你希望优化某些查询的响应时间。具体哪些额外的Cuboid需要被构建由高级配置页面的强制Cuboid指定。kylin.stream.cube.window: 指定了Streaming Segment的长度。默认值是3600。详情参阅deep-dive-real-time-olap。kylin.stream.cube.duration: 指定了Streaming Segment会等待迟到的消息多久,默认值是 7200(秒)。 详情参阅deep-dive-real-time-olap。kylin.stream.cube.duration.max: 指定了Streaming Segment保持Active的最长时间。默认值是 43200。详情参阅deep-dive-real-time-olap。kylin.stream.checkpoint.file.max.num: 指定了Receiver为每一个Cube保留的checkpoint文件数量。默认值是 5。kylin.stream.index.checkpoint.intervals: 指定了Receiver进行checkpoint的间隔。默认值是 300。kylin.stream.immutable.segments.max.num: 指定了在Receiver端,一个Cube最多可以保持多少个IMMUTABLEsegment,因为Receiver端的性能和Fragment File的数量呈负相关。默认值是 100。kylin.stream.consume.offsets.latest:指定了Receiver从什么位置开始消费,设置成true则从最新的offset开始消费,false则从最老的位置消费。默认值是 true。
高级设置
kylin.stream.assigner: 值是一个类的名字,这个类应该是org.apache.kylin.stream.coordinator.assign.Assigner的实现类,用于指定如何将Kafka Topic 下的各个Partition分配给各个Replica Set。默认值是 DefaultAssigner,其策略会努力将工作负载分配给负责partition数量少的Replica Set,以使得各个Replica Set工作负载相对均衡。kylin.stream.coordinator.client.timeout.millsecond: 指定和Coordinator HTTP连接的Timeout,默认值是 5000。kylin.stream.receiver.client.timeout.millsecond:指定和Receiver HTTP连接的Timeout,默认值是 5000。kylin.stream.receiver.http.max.threads: 指定了Receiver端的Http连接最大线程数。默认值为 200。kylin.stream.receiver.http.min.threads: 指定了Receiver端的Http连接最小线程数。默认值为 10。kylin.stream.receiver.query-core-threads: 指定了Receiver用于scan的线程数量,默认值是50。kylin.stream.receiver.query-max-threads: 指定了Receiver用于scan的线程最大数量,默认值是200。kylin.stream.segment-max-fragments: Receiver端每次MemoryStore大小达到阈值(kylin.stream.index.maxrows),会落盘形成一个Fragment File,Receiver会尝试尽可能合并这些Fragment File来减少数据冗余。这个配置项会指定触发merge的阈值,默认值是50。kylin.stream.segment-min-fragments: Receiver端的每次merge后不会使文件数量少于这个阈值,默认值是 15。kylin.stream.max-fragment-size-mb: 合并后,每个Fragment File的大小不会超过该值,默认值是 300。kylin.stream.fragments-auto-merge-enable: 是否开启后台自动合并Fragment File。默认值是 true。kylin.stream.metrics.option: 指定是否开启Receiver端的metrics信息收集, 可选值是 csv/console/jmx。kylin.stream.event.timezone: 指定从Event Time衍生出来的时间衍生列如HOUR_START/DAY_START使用哪种时区,默认是UTC时间。kylin.stream.auto-resubmit-after-discard-enabled: 当用户 discard了某一个 Realtime的构建任务,是否自动重新提交新任务。
提示:入门教程 请参考 Real-time OLAP。
存储清理配置
本小节介绍 Kylin 存储清理有关的配置。
存储清理相关
kylin.storage.clean-after-delete-operation: 是否清理 HBase 和 HDFS 中的 segment 数据。默认值为 FALSE。
查询配置
本小节介绍 Kylin 查询有关的配置。
查询相关
kylin.query.skip-empty-segments:查询是否跳过数据量为 0 的 segment,默认值为 TRUEkylin.query.large-query-threshold:指定最大返回行数,默认值为 1000000kylin.query.security-enabled:是否在查询时检查 ACL,默认值为 TRUEkylin.query.security.table-acl-enabled:是否在查询时检查对应表的 ACL,默认值为 TRUEkylin.query.calcite.extras-props.conformance:是否严格解析,默认值为 LENIENTkylin.query.calcite.extras-props.caseSensitive:是否大小写敏感,默认值为 TRUEkylin.query.calcite.extras-props.unquotedCasing:是否需要将查询语句进行大小写转换,参数值可选UNCHANGED,TO_UPPER,TO_LOWER,默认值为TO_UPPER,即全部大写kylin.query.calcite.extras-props.quoting:是否添加引号,参数值可选DOUBLE_QUOTE,BACK_TICK,BRACKET,默认值为DOUBLE_QUOTEkylin.query.statement-cache-max-num:缓存的 PreparedStatement 的最大条数,默认值为 50000kylin.query.statement-cache-max-num-per-key:每个键缓存的 PreparedStatement 的最大条数,默认值为 50kylin.query.enable-dict-enumerator:是否启用字典枚举器,默认值为 FALSEkylin.query.enable-dynamic-column:是否启用动态列,默认值为 FALSE,设置为 TRUE 后可以查询一列中不包含 NULL 的行数
模糊查询
kylin.storage.hbase.max-fuzzykey-scan:设置扫描的模糊键的阈值,超过该参数值便不再扫描模糊键,默认值为 200kylin.storage.hbase.max-fuzzykey-scan-split:分割大模糊键集来减少每次扫描中模糊键的数量,默认值为 1kylin.storage.hbase.max-visit-scanrange:默认值为 1000000
查询缓存
kylin.query.cache-enabled:是否启用缓存,默认值为 TRUEkylin.query.cache-threshold-duration:查询延时超过阈值则保存进缓存,默认值为 2000(ms)kylin.query.cache-threshold-scan-count:查询所扫描的数据行数超过阈值则保存进缓存,默认值为 10240(rows)kylin.query.cache-threshold-scan-bytes:查询所扫描的数据字节数超过阈值则保存进缓存,默认值为 1048576(byte)
查询限制
kylin.query.timeout-seconds:设置查询超时时间,默认值为 0,即没有限制,如果设置的值小于 60,会被强制替换成 60 秒kylin.query.timeout-seconds-coefficient:设置查询超时秒数的系数,默认值为 0.5kylin.query.max-scan-bytes:设置查询扫描字节的上限,默认值为 0,即没有限制kylin.storage.partition.max-scan-bytes:设置查询扫描的最大字节数,默认值为 3221225472(bytes),即 3GBkylin.query.max-return-rows:指定查询返回行数的上限,默认值为 5000000
坏查询
kylin.query.timeout-seconds 的值为大于 60 或为 0,kylin.query.timeout-seconds-coefficient 其最大值为 double 的上限。这两个参数的乘积为坏查询检查的间隔时间,如果为 0,那么会设为 60 秒,最长秒数是 int 的最大值。
kylin.query.badquery-stacktrace-depth:设置堆栈追踪的深度,默认值为 10kylin.query.badquery-history-number:设置要展示的历史坏查询的数量,默认为 50kylin.query.badquery-alerting-seconds:默认为 90,如果运行时间大于这个值,那么首先就会打出该查询的日志信息,包括(时长、项目、线程、用户、查询 id)。至于是否保存最近的查询,取决于另一个参数。然后记录 Stack 日志信息,记录的深度由另一个参数指定,方便后续问题分析kylin.query.badquery-persistent-enabled:默认为 true,会保存最近的一些坏查询,而且不可在 Cube 级别进行覆盖
查询下压
kylin.query.pushdown.runner-class-name=org.apache.kylin.query.adhoc.PushDownRunnerJdbcImpl:如果需要启用查询下压,需要移除这句配置的注释kylin.query.pushdown.jdbc.url:JDBC 的 URLkylin.query.pushdown.jdbc.driver:JDBC 的 driver 类名,默认值为org.apache.hive.jdbc.HiveDriverkylin.query.pushdown.jdbc.username:JDBC 对应数据库的用户名,默认值为hivekylin.query.pushdown.jdbc.password:JDBC 对应数据库的密码kylin.query.pushdown.jdbc.pool-max-total:JDBC 连接池的最大连接数,默认值为8kylin.query.pushdown.jdbc.pool-max-idle:JDBC 连接池的最大等待连接数,默认值为8kylin.query.pushdown.jdbc.pool-min-idle:默认值为 0kylin.query.pushdown.update-enabled:指定是否在查询下压中开启 update,默认值为 FALSEkylin.query.pushdown.cache-enabled:是否开启下压查询的缓存来提高相同查询语句的查询效率,默认值为 FALSE
提示:更多信息请参考查询下压
查询改写
kylin.query.force-limit:该参数通过为 select * 语句强制添加 LIMIT 分句,达到缩短数据返回时间的目的,该参数默认值为 -1,将该参数值设置为正整数,如 1000,该值会被应用到 LIMIT 分句,查询语句最终会被转化成 select * from fact_table limit 1000kylin.storage.limit-push-down-enabled: 默认值为 TRUE,设置为 FALSE 意味着关闭存储层的 limit-pushdownkylin.query.flat-filter-max-children:指定打平 filter 时 filter 的最大值。默认值为 500000
收集查询指标到 JMX
kylin.server.query-metrics-enabled:默认值为 FALSE,设为 TRUE 来将查询指标收集到 JMX
提示:更多信息请参考 JMX
收集查询指标到 dropwizard
kylin.server.query-metrics2-enabled:默认值为 FALSE,设为 TRUE 来将查询指标收集到 dropwizard
提示:更多信息请参考 dropwizard
安全配置
本小节介绍 Kylin 安全有关的配置。
用户名和密码
请参考文档:How to add new user or change the default password
集成 LDAP 实现单点登录
kylin.security.profile:安全认证的方式,参数值可选ldap,testing,saml。集成 LDAP 实现单点登录时应设置为ldapkylin.security.ldap.connection-server:LDAP 服务器,如 ldap://ldap_server:389kylin.security.ldap.connection-username:LDAP 用户名kylin.security.ldap.connection-password:LDAP 密码kylin.security.ldap.user-search-base:定义同步到 Kylin 的用户的范围kylin.security.ldap.user-search-pattern:定义登录验证匹配的用户名kylin.security.ldap.user-group-search-base:定义同步到 Kylin 的用户组的范围kylin.security.ldap.user-group-search-filter:定义同步到 Kylin 的用户的类型kylin.security.ldap.service-search-base:当需要服务账户可以访问 Kylin 时需要定义kylin.security.ldap.service-search-pattern:当需要服务账户可以访问 Kylin 时需要定义kylin.security.ldap.service-group-search-base:当需要服务账户可以访问 Kylin 时需要定义kylin.security.acl.admin-role:将一个 LDAP 群组映射成管理员角色(组名大小写敏感)kylin.server.auth-user-cache.expire-seconds:LDAP 用户信息缓存时间,默认值为 300(s)kylin.server.auth-user-cache.max-entries:LDAP 用户数目最大缓存,默认值为 100
集成 Apache Ranger
kylin.server.external-acl-provider=org.apache.ranger.authorization.kylin.authorizer.RangerKylinAuthorizer
提示:更多信息请参考Ranger 的安装文档之如何集成 Kylin 插件
启用 ZooKeeper ACL
kylin.env.zookeeper-acl-enabled:启用 ZooKeeper ACL 以阻止未经授权的用户访问 Znode 或降低由此导致的不良操作的风险,默认值为FALSEkylin.env.zookeeper.zk-auth:使用 用户名:密码 作为 ACL 标识,默认值为digest:ADMIN:KYLINkylin.env.zookeeper.zk-acl:使用单个 ID 作为 ACL 标识,默认值为world:anyone:rwcda,anyone表示任何人
使用 Memcached 作为 Kylin 查询缓存
从 v2.6.0,Kylin 可以使用 Memcached 作为查询缓存,一起引入的还有一系列缓存增强 (KYLIN-2895)。想要启用该功能,您需要执行以下步骤:
-
在一个或多个节点上安装 Memcached (最新稳定版 v1.5.12); 如果资源够的话,可以在每个安装 Kylin 的节点上安装 Memcached。
-
按照如下所示方式修改 $KYLIN_HOME/tomcat/webapps/kylin/WEB-INF/classes 目录下的 applicationContext.xml 的内容:
注释如下代码:
<bean id="ehcache"
class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean"
p:configLocation="classpath:ehcache-test.xml" p:shared="true"/>
<bean id="cacheManager" class="org.springframework.cache.ehcache.EhCacheCacheManager"
p:cacheManager-ref="ehcache"/>取消如下代码的注释:
<bean id="ehcache" class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean"
p:configLocation="classpath:ehcache-test.xml" p:shared="true"/>
<bean id="remoteCacheManager" class="org.apache.kylin.cache.cachemanager.MemcachedCacheManager" />
<bean id="localCacheManager" class="org.apache.kylin.cache.cachemanager.InstrumentedEhCacheCacheManager"
p:cacheManager-ref="ehcache"/>
<bean id="cacheManager" class="org.apache.kylin.cache.cachemanager.RemoteLocalFailOverCacheManager" />
<bean id="memcachedCacheConfig" class="org.apache.kylin.cache.memcached.MemcachedCacheConfig">
<property name="timeout" value="500" />
<property name="hosts" value="${kylin.cache.memcached.hosts}" />
</bean>applicationContext.xml 中 ${kylin.cache.memcached.hosts} 的值就是在 conf/kylin.properties 中指定的 kylin.cache.memcached.hosts 的值。
3.在 conf/kylin.properties 中添加如下参数:
kylin.query.cache-enabled=true
kylin.query.lazy-query-enabled=true
kylin.query.cache-signature-enabled=true
kylin.query.segment-cache-enabled=true
kylin.cache.memcached.hosts=memcached1:11211,memcached2:11211,memcached3:11211kylin.query.cache-enabled是否开启查询缓存的总开关,默认值为true。kylin.query.lazy-query-enabled是否为短时间内重复发送的查询,等待并重用前次查询的结果,默认为false。kylin.query.cache-signature-enabled是否为缓存进行签名检查,依据签名变化来决定缓存的有效性。缓存的签名由项目中的 cube / hybrid 的状态以及它们的最后构建时间等来动态计算(在缓存被记录时),默认为false,高度推荐设置为true。kylin.query.segment-cache-enabled是否在 segment 级别缓存从 存储引擎(HBase)返回的数据,默认为false;设置为true,且启用 Memcached 分布式缓存开启的时候,此功能才会生效。可为频繁构建的 cube (如 streaming cube)提升缓存命中率,从而提升性能。kylin.cache.memcached.hosts指明了 memcached 的机器名和端口。