
Cube迁移功能主要用于把QA环境下的Cube迁移到PROD环境下,Kylin v3.1.0对这个功能进行了加强,加强的功能列表如下:
- 在迁移前,Kylin会使用内部定义的一些规则对Cube的质量及兼容性做校验,之前的版本则需要人工去校验;
- 通过邮件的方式发送迁移请求及迁移结果通知,取代之前的人工沟通;
- 支持跨Hadoop集群的迁移功能;
I. 在同一个Hadoop集群下的Cube迁移
提供如下两种方式来迁移同一个Hadoop集群下的Cube:
- 使用Kylin portal;
- 使用工具类’CubeMigrationCLI.java’;
1. 迁移的前置条件
- Cube迁移的操作按钮只有Cube的管理员才可见。
- 在迁移前,必须对要迁移的Cube进行构建,确认查询性能,Cube的状态必须是READY。
- 配置项’kylin.cube.migration.enabled‘必须是true。
- 确保Cube要迁移的目标项目(PROD环境下)必须存在。
- QA环境和PROD环境必须在同一个Hadoop集群下, 即具有相同的 HDFS, HBase and HIVE等。
2. 通过Web界面进行Cube迁移的步骤
首先,要确保有操作Cube的权限。
步骤 1
在QA环境里的 ‘Model’ 页面,点击’Actions’列中的’Action’下拉列表,选择’Migrate’操作:
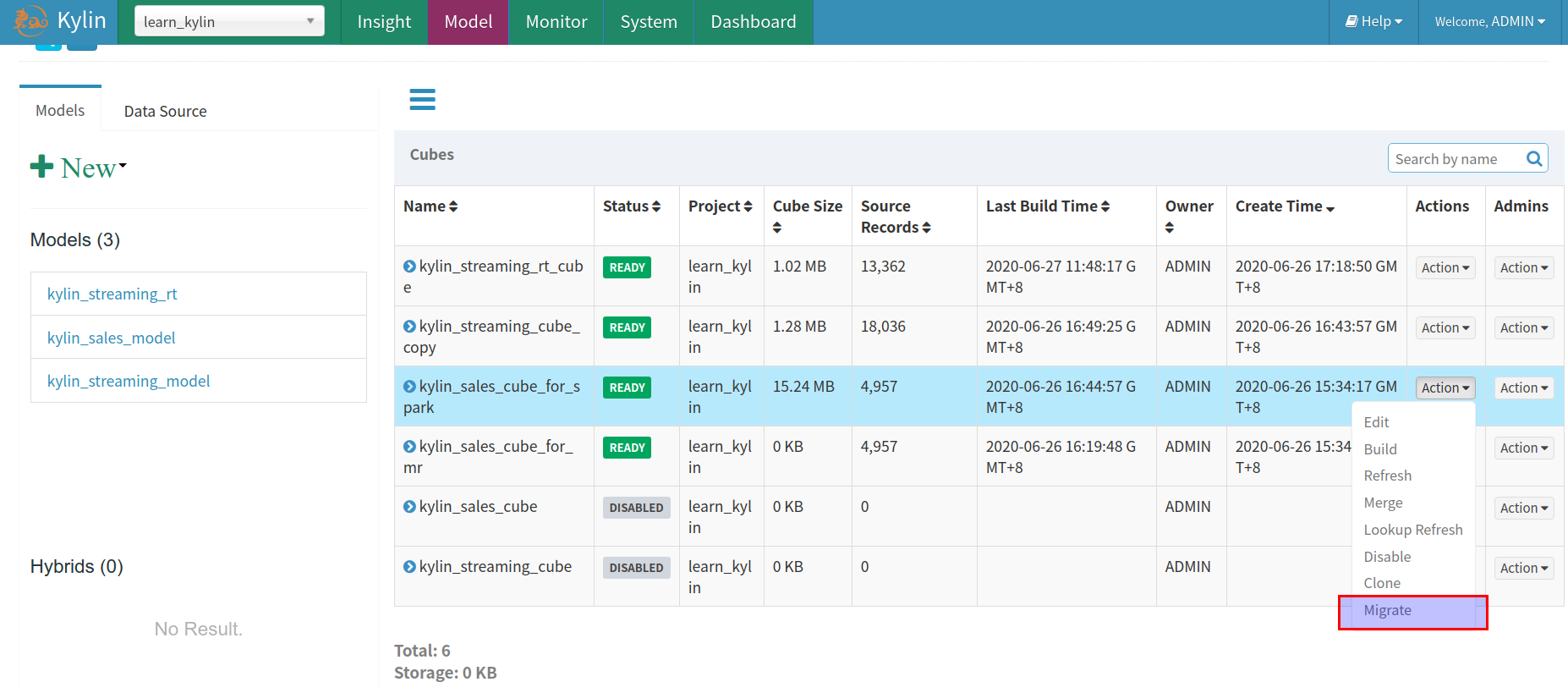
步骤 2
在点击’Migrate’按钮后, 将会出现一个弹出框:
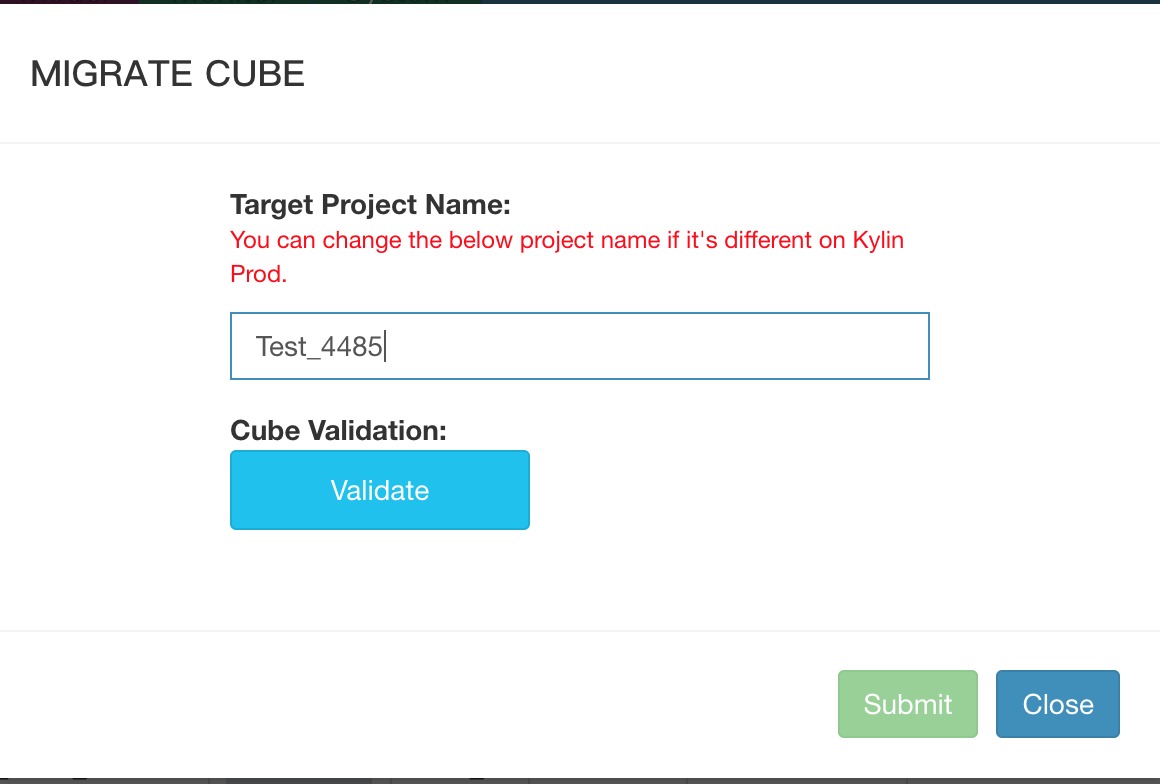
步骤 3
在弹出框中输入PROD环境的目标项目名称,使用QA环境的项目名称作为默认值。
步骤 4
在弹出框中点击’Validate’按钮,将会在后端对迁移的Cube做一些验证,待验证完毕,会出现验证结果的弹出框。
验证异常及解决方法
-
The target project XXX does not exist on PROD-KYLIN-INSTANCE:7070: 输入的PROD环境的目标项目名称必须存在。 -
Cube email notification list is not set or empty: 要迁移的Cube的邮件通知列表不能为空。
建议性提示
Auto merge time range for cube XXXX is not set: 建议设置Cube的配置项:’Auto Merge Threshold’。ExpansionRateRule: failed on expansion rate check with exceeding 5: Cube的膨胀率超过配置项’kylin.cube.migration.expansion-rate’配置的值,可以设置为一个合理的值。Failed on query latency check with average cost 5617 exceeding 2000ms: 如果设置配置项’kylin.cube.migration.rule-query-latency-enabled’为true, 在验证阶段后端会自动生成一些SQL来测试Cube的查询性能,可以合理设置配置项’kylin.cube.migration.query-latency-seconds’的值。
步骤 5
待验证通过,点击’Submit’按钮发起Cube迁移请求给Cube的管理员。后端会自动发送请求邮件给Cube管理员:
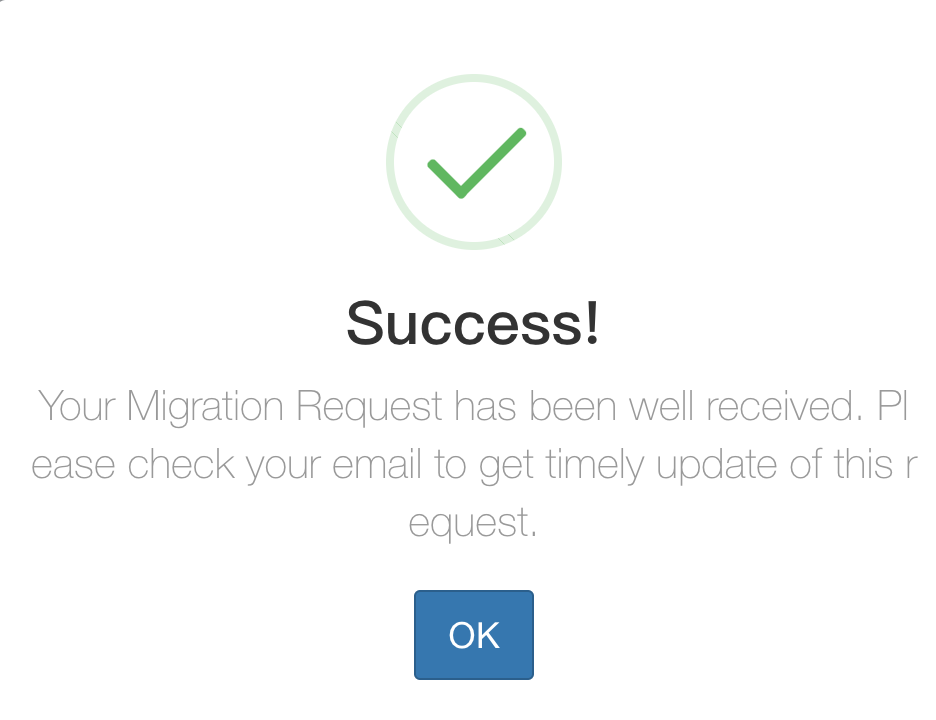
步骤 6
Cube管理员在接收到Cube迁移请求邮件后,可以通过’Model’页面里’Admins’列的’Action’下拉列表,选择’Approve Migration’操作还是’Reject Migration’操作,同时后端会自动发送请求结果邮件给请求者:

步骤 7
如果Cube管理员选择’Approve Migration’,将会出现如下弹出框:
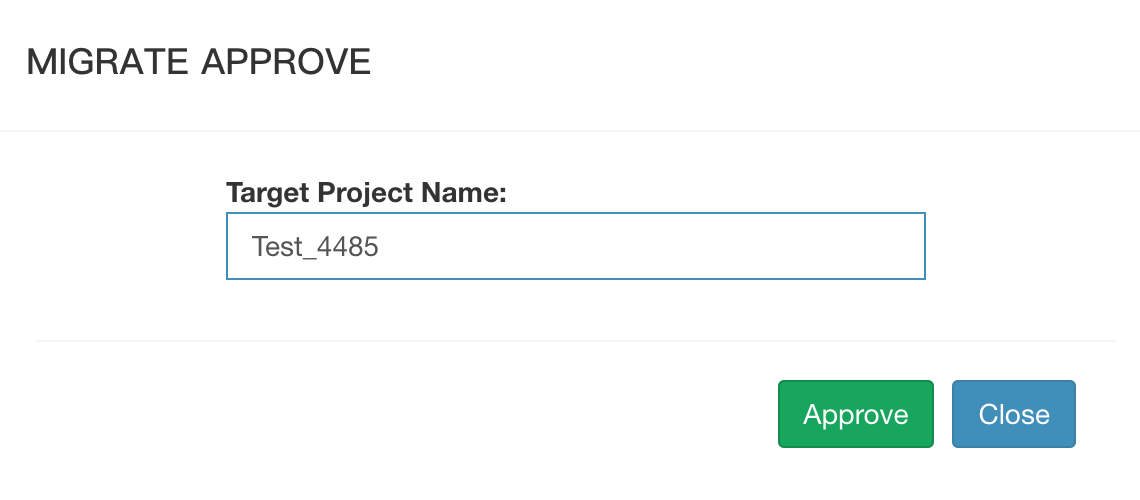
在弹出框输入正确的目标项目名称,点击’Approve’按钮,后端开始迁移Cube。
步骤 8
迁移Cube成功后,将会出现如下弹出框,显示迁移成功:
步骤 9
最后, 在PROD环境下的’Model’页面,迁移的Cube会出现在列表中,且状态是DISABLED。
3. 使用’CubeMigrationCLI.java’工具类进行迁移
作用
CubeMigrationCLI.java 用于迁移 cubes。例如:将 cube 从测试环境迁移到生产环境。请注意,不同的环境是共享相同的 Hadoop 集群,包括 HDFS,HBase 和 HIVE。此 CLI 不支持跨 Hadoop 集群的数据迁移。
如何使用
前八个参数必须有且次序不能改变。
./bin/kylin.sh org.apache.kylin.tool.CubeMigrationCLI <srcKylinConfigUri> <dstKylinConfigUri> <cubeName> <projectName> <copyAclOrNot> <purgeOrNot> <overwriteIfExists> <realExecute> <migrateSegmentOrNot>例如:
./bin/kylin.sh org.apache.kylin.tool.CubeMigrationCLI ADMIN:KYLIN@kylin-qa:7070 ADMIN:KYLIN@kylin-prod:7070 kylin_sales_cube learn_kylin true false false true false命令执行成功后,请 reload metadata,您想要迁移的 cube 将会存在于迁移后的 project 中。
下面会列出所有支持的参数:
- 如果您使用 cubeName 这个参数,但想要迁移的 cube 所对应的 model 在要迁移的环境中不存在,model 的数据也会迁移过去。
- 如果您将 overwriteIfExists 设置为 false,且该 cube 已存在于要迁移的环境中,当您运行命令,cube 存在的提示信息将会出现。
- 如果您将 migrateSegmentOrNot 设置为 true,请保证 Kylin metadata 的 HDFS 目录存在且 Cube 的状态为 READY。
| Parameter | Description |
|---|---|
| srcKylinConfigUri | The URL of the source environment’s Kylin configuration. It can be username:password@host:7070, or an absolute file path to the kylin.properties. If you use the URL method, you need to change the ADMIN user name and password to username:password@hostname:port format is placed in the URL, because there is a API needs to be called with admin permission during the migration process. |
| dstKylinConfigUri | The URL of the target environment’s Kylin configuration. |
| cubeName | the name of Cube to be migrated.(Make sure it exist) |
| projectName | The target project in the target environment.(Make sure it exist) |
| copyAclOrNot | true or false: whether copy Cube ACL to target environment. |
| purgeOrNot | true or false: whether purge the Cube from src server after the migration. |
| overwriteIfExists | true or false: overwrite cube if it already exists in the target environment. |
| realExecute | true or false: if false, just print the operations to take, if true, do the real migration. |
| migrateSegmentOrNot | (Optional) true or false: whether copy segment data to target environment. Default true. |
II. 跨Hadoop集群下的Cube迁移
注意:
- 当前只支持使用工具类’CubeMigrationCrossClusterCLI.java’来进行跨Hadoop集群下的Cube迁移。
- 跨Hadoop集群的Cube迁移,支持同时把Cube数据从QA环境迁移到PROD环境。
1. 迁移的前置条件
- 在迁移前,必须对要迁移的Cube进行构建Segment,确认查询性能,Cube的状态必须是READY。
- PROD环境下的目标项目名称必须和QA环境下的项目名称一致。
2. 如何使用工具类’CubeMigrationCrossClusterCLI.java’来迁移Cube
./bin/kylin.sh org.apache.kylin.tool.migration.CubeMigrationCrossClusterCLI <kylinUriSrc> <kylinUriDst> <updateMappingPath> <cube> <hybrid> <project> <all> <dstHiveCheck> <overwrite> <schemaOnly> <execute> <coprocessorPath> <codeOfFSHAEnabled> <distCpJobQueue> <distCpJobMemory> <nThread>例如:
./bin/kylin.sh org.apache.kylin.tool.migration.CubeMigrationCrossClusterCLI -kylinUriSrc ADMIN:KYLIN@QA.env:17070 -kylinUriDst ADMIN:KYLIN@PROD.env:17777 -cube kylin_sales_cube -updateMappingPath $KYLIN_HOME/updateTableMapping.json -execute true -schemaOnly false -overwrite true命令执行成功后,在PROD环境下的’Model’页面,迁移的Cube会出现在列表中,且状态是READY。
下面会列出所有支持的参数:
| Parameter | Description |
|---|---|
| kylinUriSrc | (Required) The source kylin uri with format user:pwd@host:port. |
| kylinUriDst | (Required) The target kylin uri with format user:pwd@host:port. |
| updateMappingPath | (Optional) The path for the update Hive table mapping file, the format is json. |
| cube | The cubes which you want to migrate, separated by ‘,’. |
| hybrid | The hybrids which you want to migrate, separated by ‘,’. |
| project | The projects which you want to migrate, separated by ‘,’. |
| all | Migrate all projects. Note: You must add only one of above four parameters: ‘cube’, ‘hybrid’, ‘project’ or ‘all’. |
| dstHiveCheck | (Optional) Whether to check target hive tables, the default value is true. |
| overwrite | (Optional) Whether to overwrite existing cubes, the default value is false. |
| schemaOnly | (Optional) Whether only migrate cube related schema, the default value is true. Note: If set to false, it will migrate cube data too. |
| execute | (Optional) Whether it’s to execute the migration, the default value is false. |
| coprocessorPath | (Optional) The path of coprocessor to be deployed, the default value is get from KylinConfigBase.getCoprocessorLocalJar(). |
| codeOfFSHAEnabled | (Optional) Whether to enable the namenode ha of clusters. |
| distCpJobQueue | (Optional) The mapreduce.job.queuename for DistCp job. |
| distCpJobMemory | (Optional) The mapreduce.map.memory.mb for DistCp job. |
| nThread | (Optional) The number of threads for migrating cube data in parallel. |