
这里是一份从下载安装到体验亚秒级查询的完整流程,分别介绍了有hadoop环境(基于hadoop环境的安装)和没有hadoop环境(从docker镜像安装)两种场景下kylin的安装使用,用户可以根据自己的环境选择其中的任意一种方式。
你可以按照文章里的步骤对kylin进行初步的了解和体验,掌握kylin的基本使用技能,然后结合自己的业务场景使用kylin来设计模型,加速查询。
一、 从docker镜像安装使用kylin(不需要提前准备hadoop环境)
为了让用户方便的试用 Kylin,我们提供了 Kylin 的 docker 镜像。该镜像中,Kylin 依赖的各个服务均已正确的安装及部署,包括:
- JDK 1.8
- Hadoop 2.7.0
- Hive 1.2.1
- Hbase 1.1.2 (with Zookeeper)
- Spark 2.3.1
- Kafka 1.1.1
- MySQL 5.1.73
我们已将面向用户的 Kylin 镜像上传至 docker 仓库,用户无需在本地构建镜像,只需要安装docker,就可以体验kylin的一键安装。
step1、首先执行以下命令从 docker 仓库 pull 镜像:
docker pull apachekylin/apache-kylin-standalone:3.1.0
此处的镜像包含的是kylin最新Release版本kylin 3.1.0。由于该镜像中包含了所有kylin依赖的大数据组件,所以拉取镜像需要的时间较长,请耐心等待。Pull成功后显示如下:
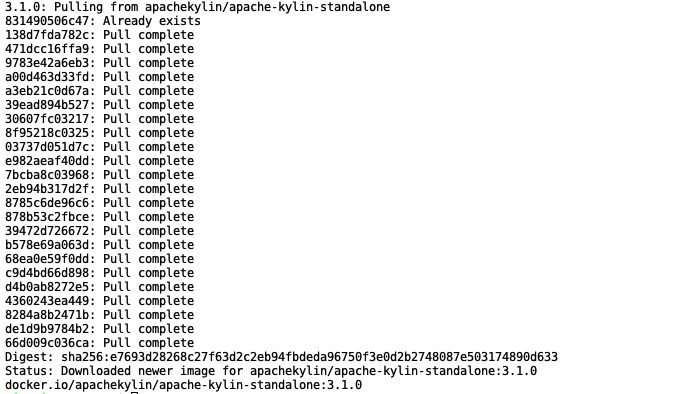
step2、执行以下命令来启动容器:
docker run -d \
-m 8G \
-p 7070:7070 \
-p 8088:8088 \
-p 50070:50070 \
-p 8032:8032 \
-p 8042:8042 \
-p 16010:16010 \
apachekylin/apache-kylin-standalone:3.1.0
容器会很快启动,由于容器内指定端口已经映射到本机端口,可以直接在本机浏览器中打开各个服务的页面,如:
- Kylin 页面:http://127.0.0.1:7070/kylin/
- Hdfs NameNode 页面:http://127.0.0.1:50070
- Yarn ResourceManager 页面:http://127.0.0.1:8088
- HBase 页面:http://127.0.0.1:60010
容器启动时,会自动启动以下服务:
- NameNode, DataNode
- ResourceManager, NodeManager
- HBase
- Kafka
- Kylin
并自动运行 $KYLIN_HOME/bin/sample.sh及在 Kafka 中创建 kylin_streaming_topic topic 并持续向该 topic 中发送数据。这是为了让用户启动容器后,就能体验以批和流的方式的方式构建 Cube 并进行查询。
用户可以通过docker exec命令进入容器,容器内相关环境变量如下:
JAVA_HOME=/home/admin/jdk1.8.0_141
HADOOP_HOME=/home/admin/hadoop-2.7.0
KAFKA_HOME=/home/admin/kafka_2.11-1.1.1
SPARK_HOME=/home/admin/spark-2.3.1-bin-hadoop2.6
HBASE_HOME=/home/admin/hbase-1.1.2
HIVE_HOME=/home/admin/apache-hive-1.2.1-bin
KYLIN_HOME=/home/admin/apache-kylin-3.1.0-bin-hbase1x
使用ADMIN/KYLIN的用户名和密码组合登陆Kylin后,用户可以使用sample cube来体验cube的构建和查询,也可以按照下面“基于hadoop环境安装使用kylin”中从step8之后的教程来创建并查询属于自己的model和cube。
二、 基于hadoop环境安装使用kylin
对于已经有稳定hadoop环境的用户,可以下载kylin的二进制包将其部署安装在自己的hadoop集群。安装之前请根据以下要求进行环境检查:
-
前置条件:
Kylin 依赖于 Hadoop 集群处理大量的数据集。您需要准备一个配置好 HDFS,YARN,MapReduce,Hive, HBase,Zookeeper 和其他服务的 Hadoop 集群供 Kylin 运行。
Kylin 可以在 Hadoop 集群的任意节点上启动。方便起见,您可以在 master 节点上运行 Kylin。但为了更好的稳定性,我们建议您将 Kylin 部署在一个干净的 Hadoop client 节点上,该节点上 Hive,HBase,HDFS 等命令行已安装好且 client 配置(如 core-site.xml,hive-site.xml,hbase-site.xml及其他)也已经合理的配置且其可以自动和其它节点同步。
运行 Kylin 的 Linux 账户要有访问 Hadoop 集群的权限,包括创建/写入 HDFS 文件夹,Hive 表, HBase 表和提交 MapReduce 任务的权限。 -
硬件要求:
运行 Kylin 的服务器建议最低配置为 4 core CPU,16 GB 内存和 100 GB 磁盘。 -
操作系统要求:
CentOS 6.5+ 或Ubuntu 16.0.4+ -
软件要求:
- Hadoop 2.7+,3.0
- Hive 0.13+,1.2.1+
- Hbase 1.1+,2.0(从kylin 2.5开始支持)
- JDK: 1.8+
建议使用集成的Hadoop环境进行kylin的安装与测试,比如Hortonworks HDP 或Cloudera CDH ,kylin发布前在 Hortonworks HDP 2.2-2.6 and 3.0, Cloudera CDH 5.7-5.11 and 6.0, AWS EMR 5.7-5.10, Azure HDInsight 3.5-3.6上测试通过。
当你的环境满足上述前置条件时 ,你可以开始安装使用kylin。
step1、下载kylin压缩包
从Apache Kylin Download Site下载一个适用于你的Hadoop版本的二进制文件。目前最新Release版本是kylin 3.1.0和kylin 2.6.6,其中3.0版本支持实时摄入数据进行预计算的功能。以CDH 5.的hadoop环境为例,可以使用如下命令行下载kylin 3.1.0:
cd /usr/local/
wget http://apache.website-solution.net/kylin/apache-kylin-3.1.0/apache-kylin-3.1.0-bin-cdh57.tar.gz
step2、解压kylin
解压下载得到的kylin压缩包,并配置环境变量KYLIN_HOME指向解压目录:
tar -zxvf apache-kylin-3.1.0-bin-cdh57.tar.gz
cd apache-kylin-3.1.0-bin-cdh57
export KYLIN_HOME=`pwd`
step3、下载SPARK
由于kylin启动时会对SPARK环境进行检查,所以你需要设置SPARK_HOME指向自己的spark安装路径:
export SPARK_HOME=/path/to/spark
如果您没有已经下载好的Spark环境,也可以使用kylin自带脚本下载spark:
$KYLIN_HOME/bin/download-spark.sh
脚本会将解压好的spark放在$KYLIN_HOME目录下,如果系统中没有设置SPARK_HOME,启动kylin时会自动找到$KYLIN_HOME目录下的spark。
step4、环境检查
Kylin 运行在 Hadoop 集群上,对各个组件的版本、访问权限及 CLASSPATH 等都有一定的要求,为了避免遇到各种环境问题,您可以执行
$KYLIN_HOME/bin/check-env.sh
来进行环境检测,如果您的环境存在任何的问题,脚本将打印出详细报错信息。如果没有报错信息,代表您的环境适合 Kylin 运行。
step5、启动kylin
运行如下命令来启动kylin:
$KYLIN_HOME/bin/kylin.sh start
如果启动成功,命令行的末尾会输出如下内容:
A new Kylin instance is started by root. To stop it, run 'kylin.sh stop'
Check the log at /usr/local/apache-kylin-3.1.0-bin-cdh57/logs/kylin.log
Web UI is at http://<hostname>:7070/kylin
step6、访问kylin
Kylin 启动后您可以通过浏览器 http://
step7、创建Sample Cube
Kylin提供了一个创建样例Cube的脚本,以供用户快速体验Kylin。
在命令行运行:
$KYLIN_HOME/bin/sample.sh
完成后登陆kylin,点击System->Configuration->Reload Metadata来重载元数据
元数据重载完成后你可以在左上角的Project中看到一个名为learn_kylin的项目,它包含kylin_sales_cube和kylin_streaming_cube, 它们分别为batch cube和streaming cube,你可以直接对kylin_sales_cube进行构建,构建完成后就可以查询。
对于kylin_streaming_cube,需要设置KAFKA_HOME指向你的kafka安装目录:
export KAFKA_HOME=/path/to/kafka
然后执行
${KYLIN_HOME}/bin/sample-streaming.sh
该脚本会在 localhost:9092 broker 中创建名为 kylin_streaming_topic 的 Kafka Topic,它也会每秒随机发送 100 条 messages 到 kylin_streaming_topic,然后你可以对kylin_streaming_cube进行构建。
关于sample cube,可以参考Sample Cube。
当然,你也可以根据下面的教程来尝试创建自己的Cube。
step8、创建project
登陆kylin后,点击左上角的+号来创建Project:

step9、加载Hive表
点击Model->Data Source->Load Table From Tree,
Kylin会读取到Hive数据源中的表并以树状方式显示出来,你可以选择自己要使用的表,然后点击sync进行将其加载到kylin。
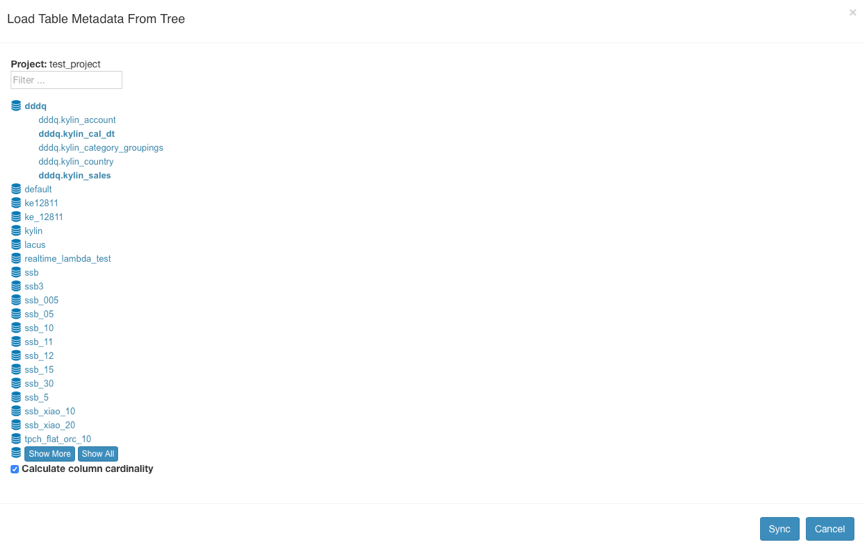
step10、创建模型
点击Model->New->New Model:
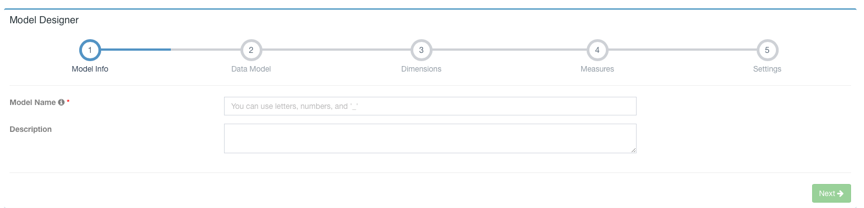
输入Model Name点击Next进行下一步,选择Fact Table和Lookup Table,添加Lookup Table时需要设置与事实表的JOIN条件。
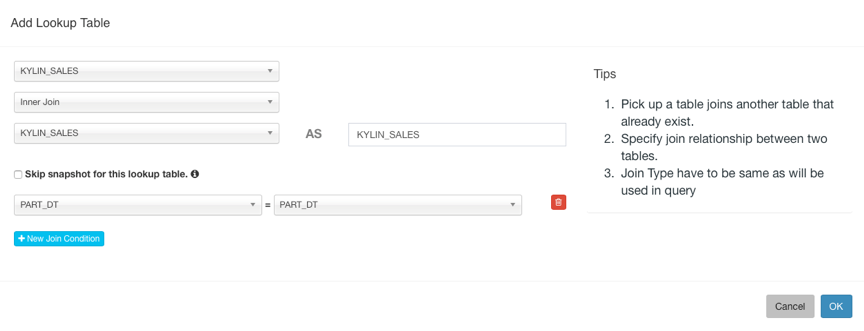
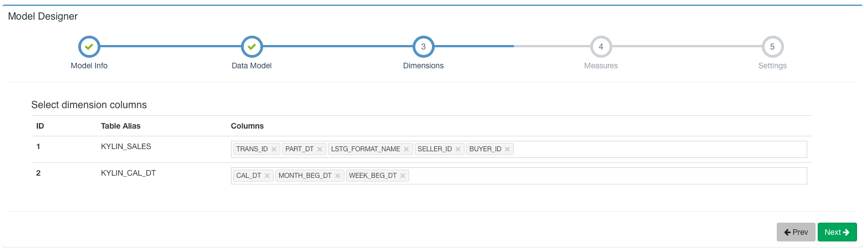
然后点击Next到下一步添加Dimension:
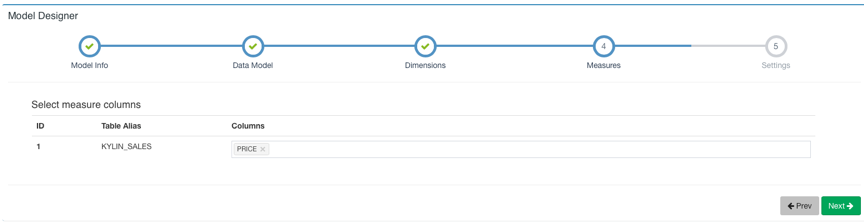
点击Next下一步添加Measure:
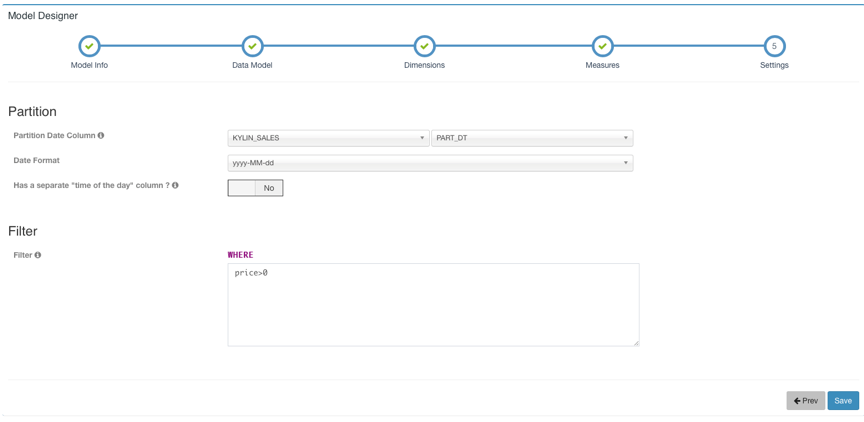
点击Next下一步跳转到设置时间分区列和过滤条件页面,时间分区列用于增量构建时选择时间范围,如果不设置时间分区列则代表该model下的cube都是全量构建。过滤条件会在打平表时用于where条件。
最后点击Save保存模型。
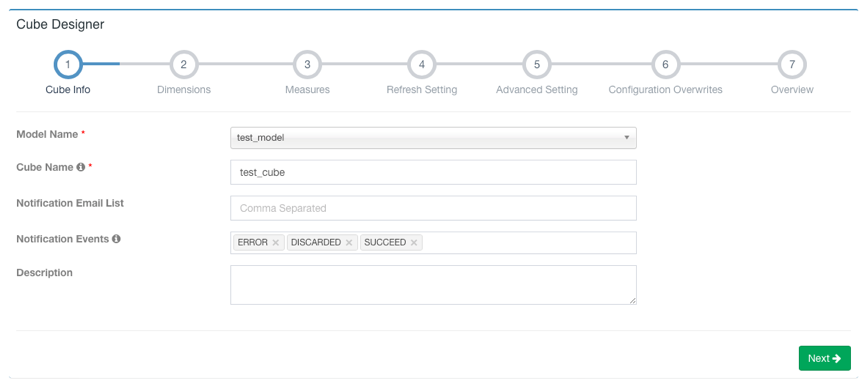
step11、创建Cube
选择Model->New->New Cube
点击Next到下一步添加Dimension,Lookup Table的维度可以设置为Normal(普通维度)或者Derived(衍生维度)两种类型,默认设置为衍生维度,衍生维度代表该列可以从所属维度表的主键中衍生出来,所以实际上只有主键列会被Cube加入计算。
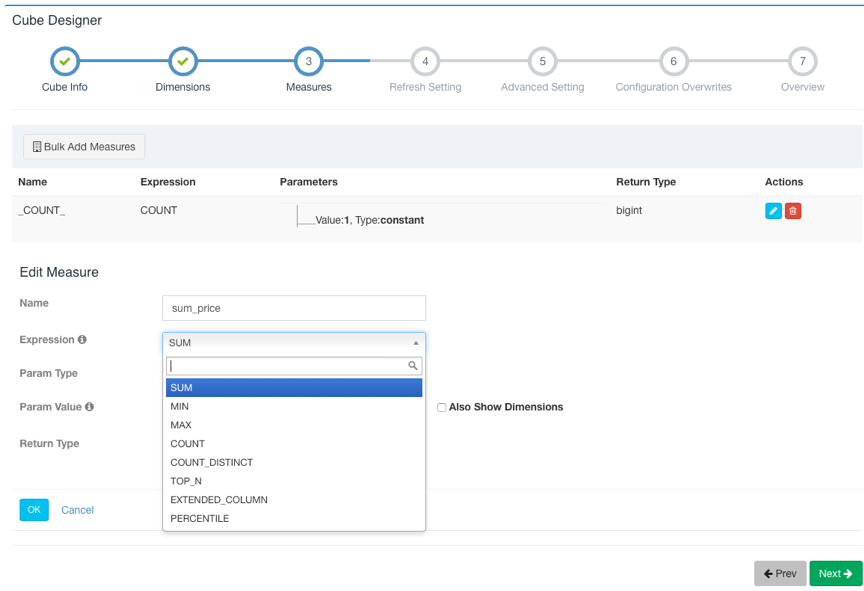
点击Next到下一步,点击+Measure来添加需要预计算的度量。Kylin会默认创建一个Count(1)的度量。Kylin支持SUM、MIN、MAX、COUNT、COUNT_DISTINCT、TOP_N、EXTENDED_COLUMN、PERCENTILE八种度量。请为COUNT_DISTINCT和TOP_N选择合适的返回类型,这关系到Cube的大小。添加完成之后点击ok,该Measure将会显示在Measures列表中
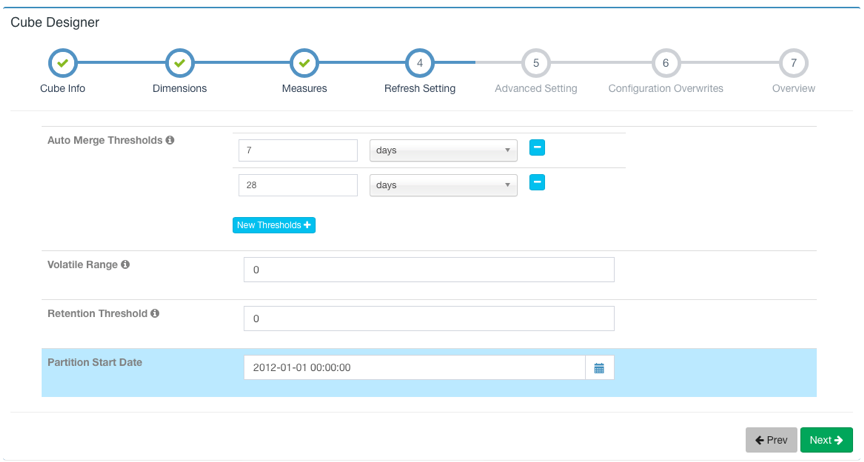
添加完所有Measure后点击Next进行下一步,这一页是关于Cube数据刷新的设置。在这里可以设施自动合并的阈值(Auto Merge Thresholds)、数据保留的最短时间(Retention Threshold)以及第一个Segment的起点时间。
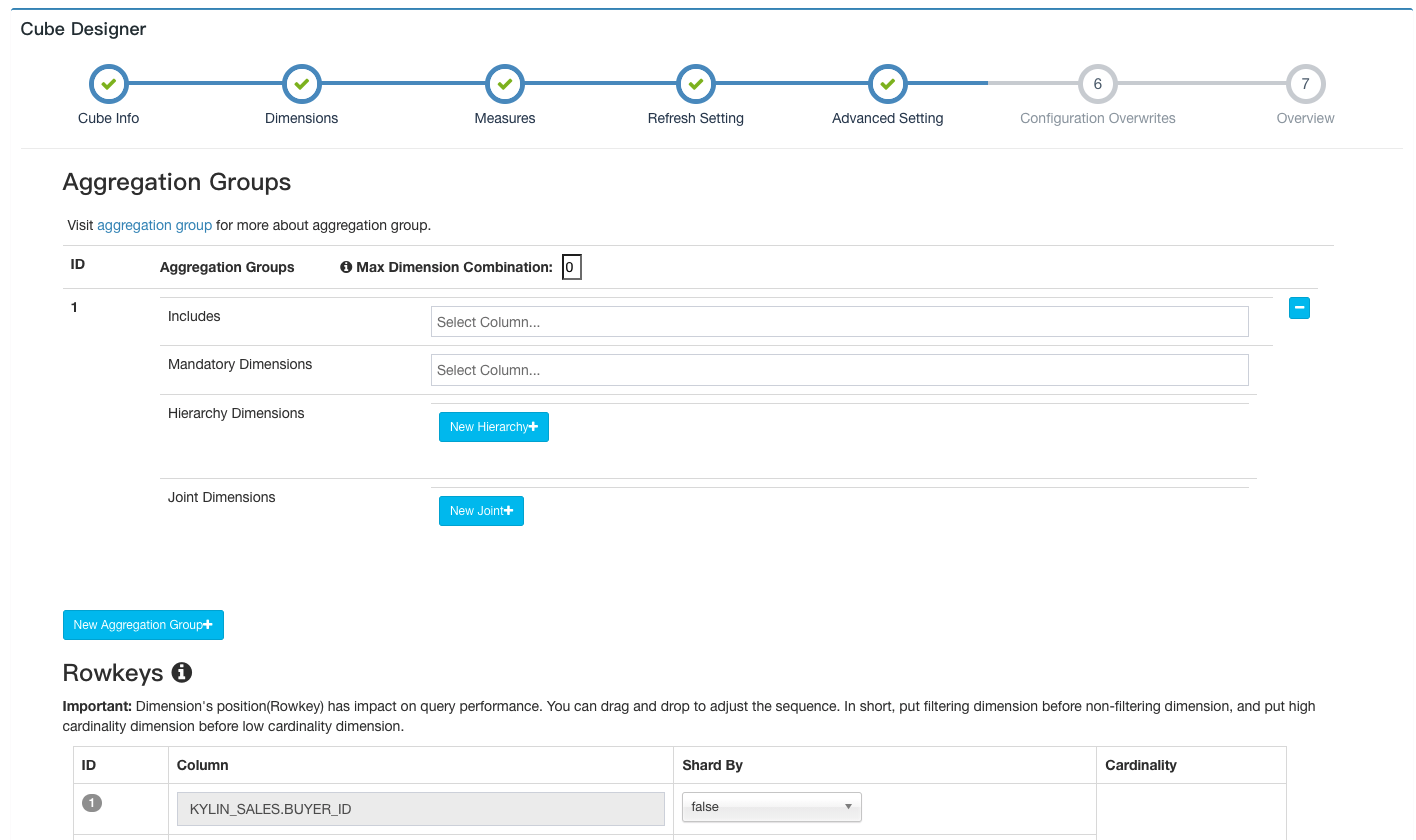
点击Next跳转到下一页高级设置。在这里可以设置聚合组、RowKeys、Mandatory Cuboids、Cube Engine等。
关于高级设置的详细信息,可以参考create_cube 页面中的步骤5,其中对聚合组等设置进行了详细介绍。
关于更多维度优化,可以阅读aggregation-group。
对于高级设置不是很熟悉时可以先保持默认设置,点击Next跳转到Kylin Properties页面,你可以在这里重写cube级别的kylin配置项,定义覆盖的属性,配置项请参考配置项。
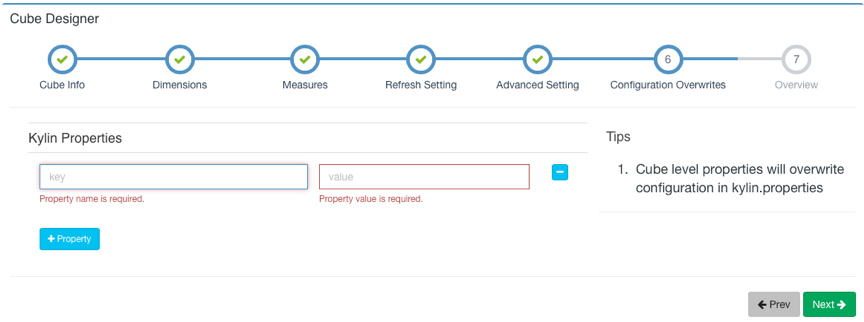
配置完成后,点击Next按钮到下一页,这里可以预览你正在创建的Cube的基本信息,并且可以返回之前的步骤进行修改。如果没有需要修改的部分,就可以点击Save按钮完成Cube创建。之后,这个Cube将会出现在你的Cube列表中。
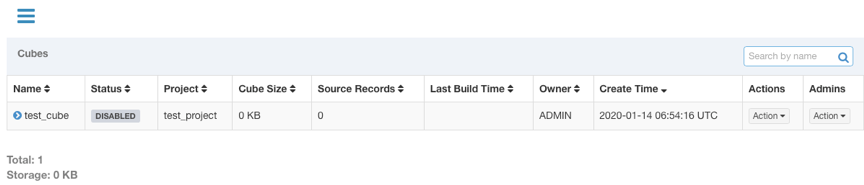
step12、构建Cube
上一个步骤创建好的Cube只有定义,而没有计算好的数据,它的状态是‘DISABLED’,是不可以查询的。要想让Cube有数据,还需要对它进行构建。
Cube的构建方式通常有两种:全量构建和增量构建。
点击要构建的Cube的Actions列下的Action展开,选择Build,如果Cube所属Model中没有设置时间分区列,则默认全量构建,点击Submit直接提交构建任务。
如果设置了时间分区列,则会出现如下页面,在这里你要选择构建数据的起止时间:
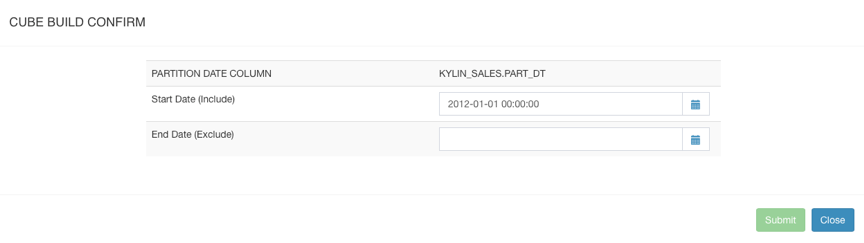
设置好起止时间后,点击Submit提交构建任务。然后你可以在Monitor页面观察构建任务的状态。Kylin会在页面上显示每一个步骤的运行状态、输出日志以及MapReduce任务。可以在${KYLIN_HOME}/logs/kylin.log中查看更详细的日志信息。
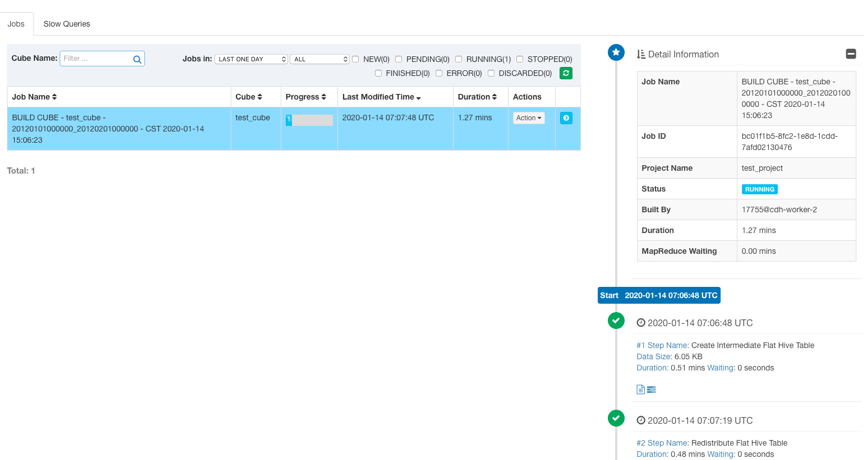
任务构建完成后,Cube状态会变成READY,并且可以看到Segment的信息。
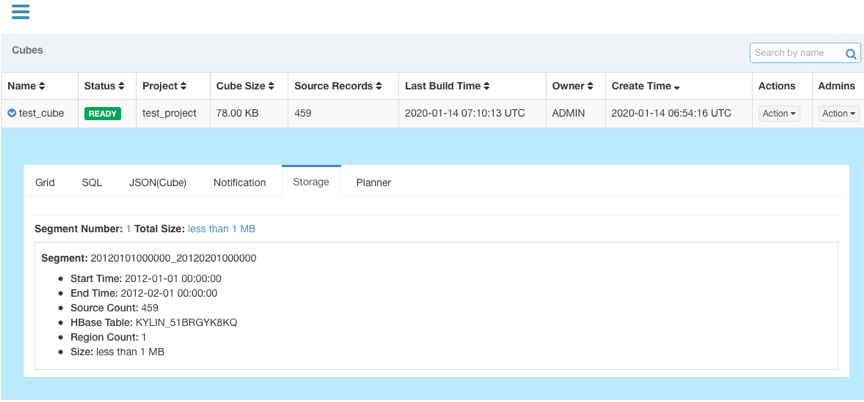
step13、查询Cube
Cube构建完成后,在Insight页面的Tables列表下面可以看到构建完成的Cube的table,并可以对其进行查询.查询语句击中Cube后会返回存储在Hbase中的预计算结果。
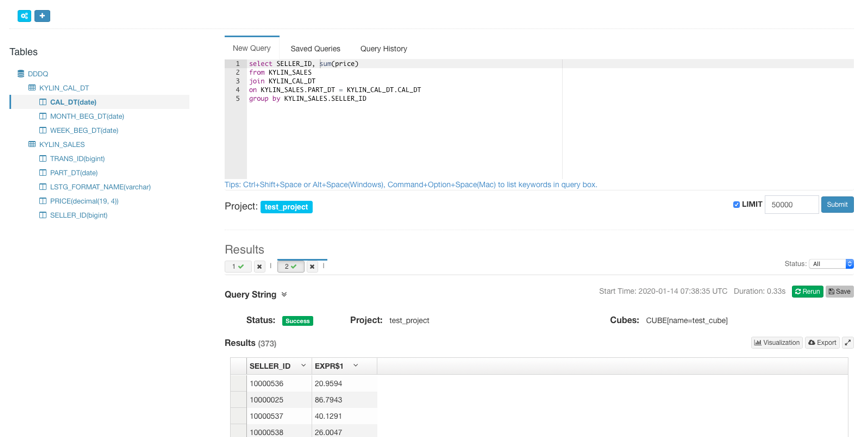
恭喜,进行到这里你已经具备了使用Kylin的基本技能,可以去发现和探索更多更强大的功能了。