
Kylin v3.0.0 releases the brand new real-time OLAP feature, by the power of new added streaming receiver cluster, Kylin can query streaming data with sub-second latency. You can check this tech blog for the overall design and core concept.
If you prefer to ingest kafka event in micro-batch way(with about 10-minutes level latency), you may consider using older Near RT streaming. Since these two feature are all for kafka data source, don’t mix them.
This doc is a step by step tutorial, illustrating how to create and build a sample streaming cube.
In this tutorial, we will use Hortonworks HDP-2.4.0.0.169 Sandbox VM + Kafka v1.0.2(Scala 2.11) as the environment.
- Basic concept
- Prepare environment
- Create cube
- Start consumption
- Monitor receiver
The configuration can be found at Real-time OLAP configuration.
The detail can be found at Deep Dive into Real-time OLAP.
If you want to configure timezone for derived time column or learn how to update streaming cube’s segment, please check this Lambda Mode and Timezone.
Basic Concept
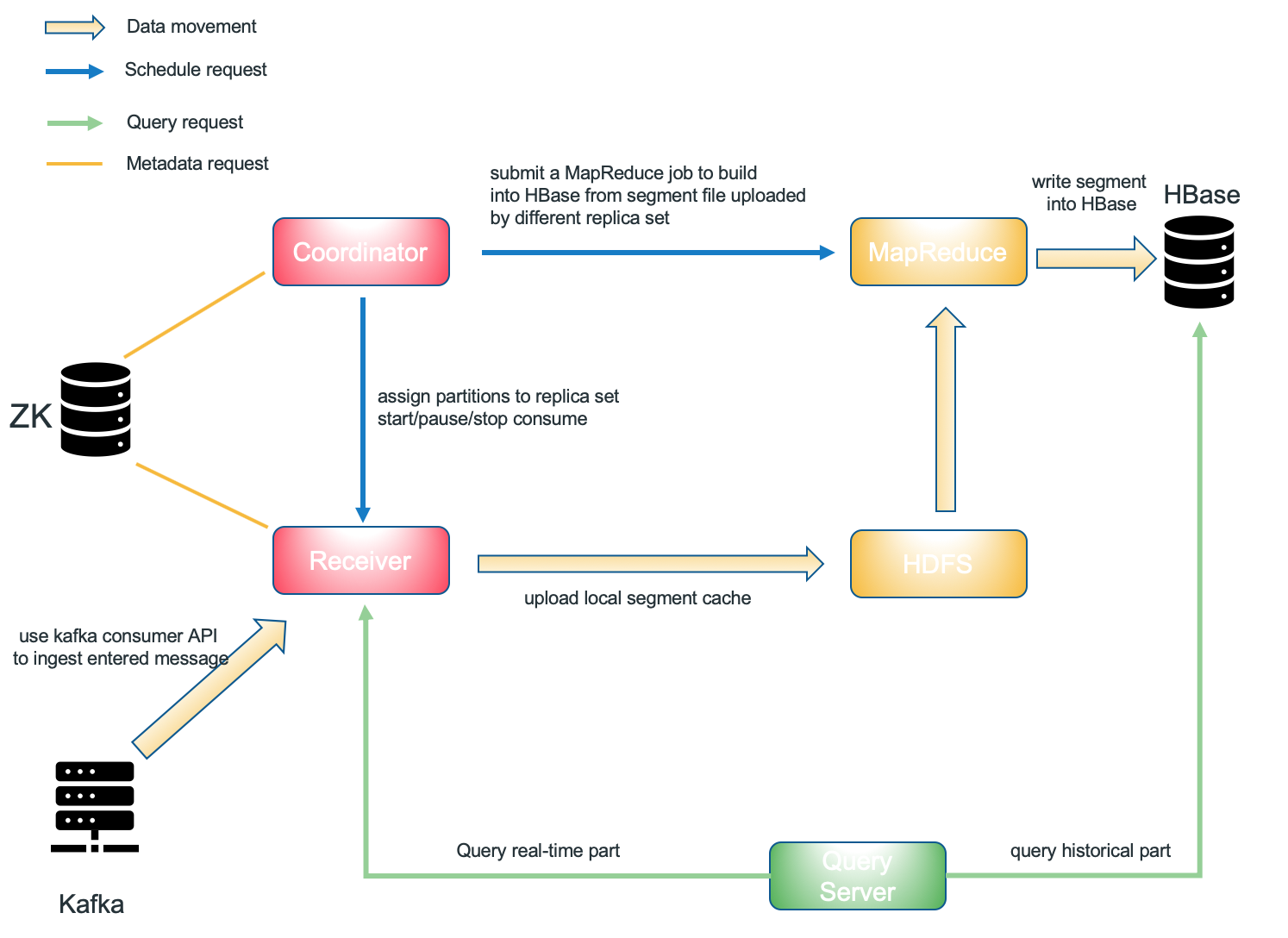
Component of Kylin’s real-time OLAP
- Kafka Cluster [data source]
- Kylin Process [job server/query server/coordinator]
- Kylin streaming receiver Cluster [real-time part computation and storage]
- HBase Cluster [historical part storage]
- Zookeeper Cluster [receiver metadata storage]
- MapReduce [distributed computation]
- HDFS [distributed storage]
Streaming Coordinator
Streaming coordinator works as the master node of streaming receiver cluster. It’s main responsibility include assign/unassign specific topic partition to specific replica set, pause or resume consuming behavior, collect mertics such as consume rate (message per second).
When kylin.server.mode is set to 3.1.3, that process is a streaming coordinator candidate(as well as query server and job server if you use all). Coordinator only manage metadata, won’t process entered message.
Coordinator Cluster
For the purpose of eliminating single point of failure, we could start more than one coordinator process. When cluster has several coordinator processes, a leader will be selected by zookeeper. Only the leader will answer coordinator client’s request, others process will become standby/candidate, so single point of failure will be eliminated.
Streaming Receiver
Streaming Receiver is the worker node. It is managed by Streaming Coordinator, its responsibility is as follow:
- ingest realtime event
- build base cuboid locally(more cuboid could be build if configured correctly)
- answer the query request for partial data which was assigned to itself
- upload local segment cache to HDFS or delete it when segment state change to immutable
Receiver Cluster
We call the collection of all streaming receiver as receiver cluster.
Replica Set
A replica set is a group of streaming receivers. Replica set is the minimum unit of task assignment, so that means all receivers in the one replica set will do the same task(cosume same partition of topic). When some receiver shut down unexpectedly but all replica set have at least one accessible receiver, the receiver cluster is still queryable and data won’t lose.
Prepare environment
Install Kafka
Don’t use HDP’s build-in Kafka as it is too old, stop it first if it is running. Please download Kafka 1.0 binary package from Kafka project page, and then uncompress it under a folder like /usr/local/.
tar -zxvf kafka_2.12-1.0.2.tgz
cd kafka_2.12-1.0.2
export KAFKA_HOME=`pwd`
bin/kafka-server-start.sh config/server.properties &Install Kylin
Download the Kylin, uncompress and rename directory to somethings like
apache-kylin-3.0.0-master, copy directory apache-kylin-3.0.0-master and rename to apache-kylin-3.0.0-receiver. So you will got two directories, the first one for start Kylin process and another for start Receiver process.
tar zxf apache-kylin-3.0.0-SNAPSHOT-bin.tar.gz
mv apache-kylin-3.0.0-SNAPSHOT-bin apache-kylin-3.0.0-SNAPSHOT-bin-master
cp -r apache-kylin-3.0.0-SNAPSHOT-bin-master apache-kylin-3.0.0-SNAPSHOT-bin-receiverInstall Spark
From v2.6.1, Kylin will not ship Spark binary anymore; You need to install Spark seperately, and then point SPARK_HOME system environment variable to it:
export SPARK_HOME=/path/to/sparkor run the script to download it:
sh bin/download-spark.shMock streaming data
Create a sample topic “kylin_streaming_topic”, with 3 partitions:
cd $KAFKA_HOME
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kylin_streaming_topic
Created topic "kylin_streaming_topic".Put sample data to this topic, you can write a python script to do that.
python user_action.py --max-uid 2000 --max-vid 2000 --msg-sec 100 --enable-hour-power false | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kylin_streaming_topicThis tool will send 100 records to Kafka every second. Please keep it running during this tutorial. You can check the sample message with kafka-console-consumer.sh now.
Start Kylin Process
The kylin process will work as coordinator of the receiver cluster. 7070 is the default port for coordinator.
cd /usr/local/apache-kylin-3.0.0-SNAPSHOT-bin-master
export KYLIN_HOME=`pwd`
sh bin/kylin.sh startIf you want to change the port for Kylin(coordinator), please first use $KYLIN_HOME/bin/kylin-port-replace-util.sh to change port(for tomcat), and then make sure to update kylin.stream.node as well.
Start Receiver Process
The receiver process will work as worker of the receiver cluster. 9090 is the default port for receiver.
cd ../apache-kylin-3.0.0-SNAPSHOT-bin-receiver/
export KYLIN_HOME=`pwd`
sh bin/kylin.sh streaming startIf you want to change the port for streaming receiver, you only need to change kylin.stream.node in kylin.properties.
Create cube
Create streaming table
After start kylin process and receiver process successfully, login Kylin Web GUI at http://sandbox:7070/kylin/
Create a new project and click “Model” -> “Data Source”, then click the icon “Add Streaming TableV2”. (Attention please, the option “Add Streaming Table” is for Near RT Streaming)
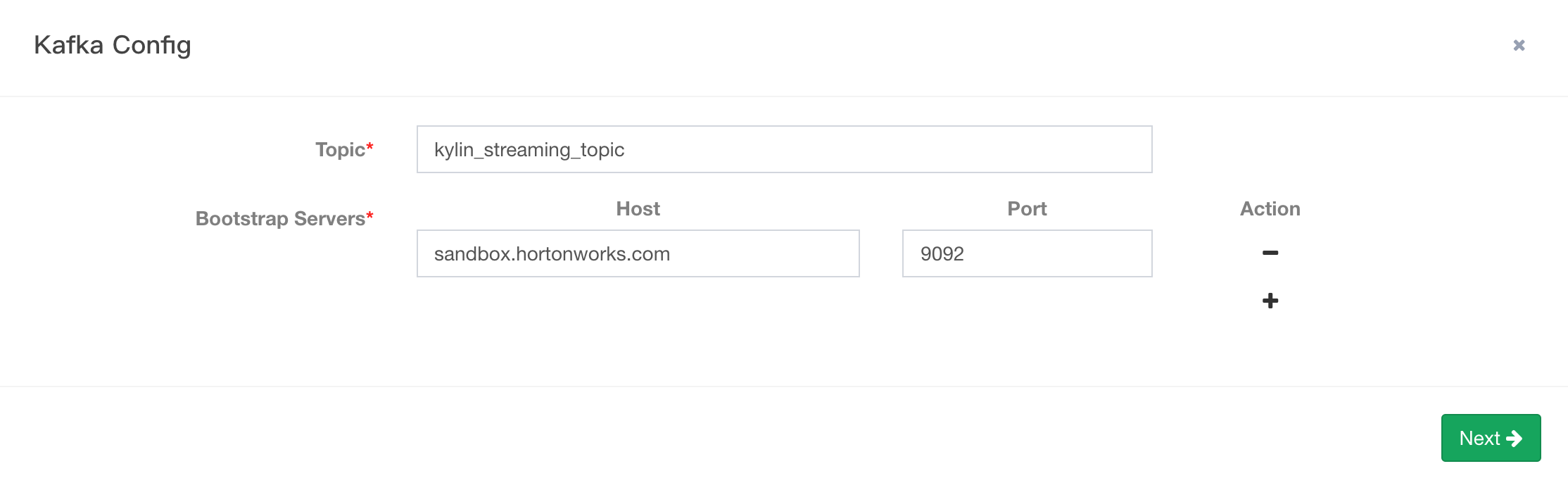
In the pop-up dialogue, you should enter topic name and kafka broker host information. After that, click “Next”.
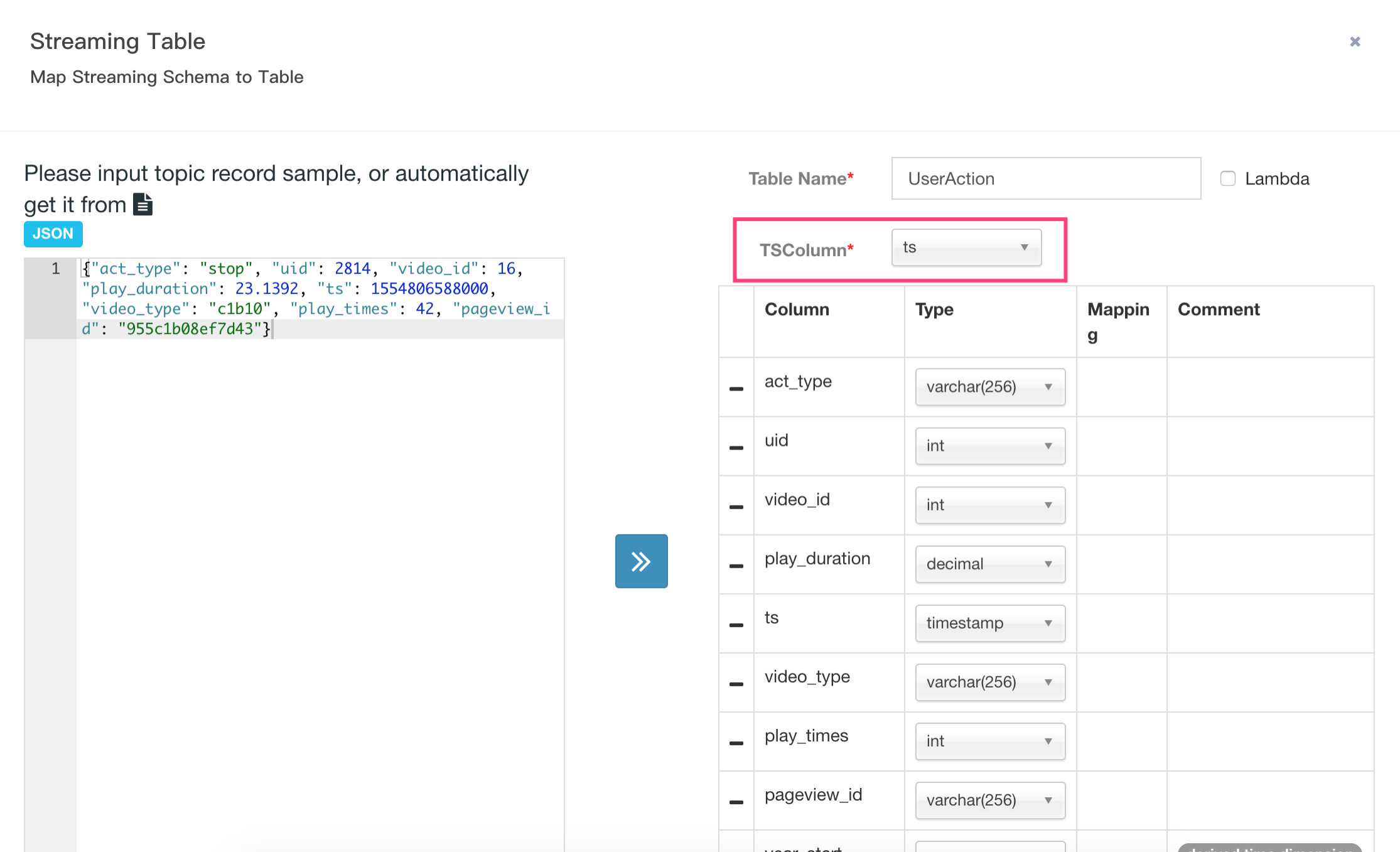
In the second pop-up dialogue, enter a sample record, click the “»” button, Kylin parses the JSON message and lists all the properties. Please remember to check the right TimeStamp Column, By default timestamp column (specified by “tsColName”) should be a bigint (epoch time) value. Don’t check “lambda”, please view documentation if you are interested in.
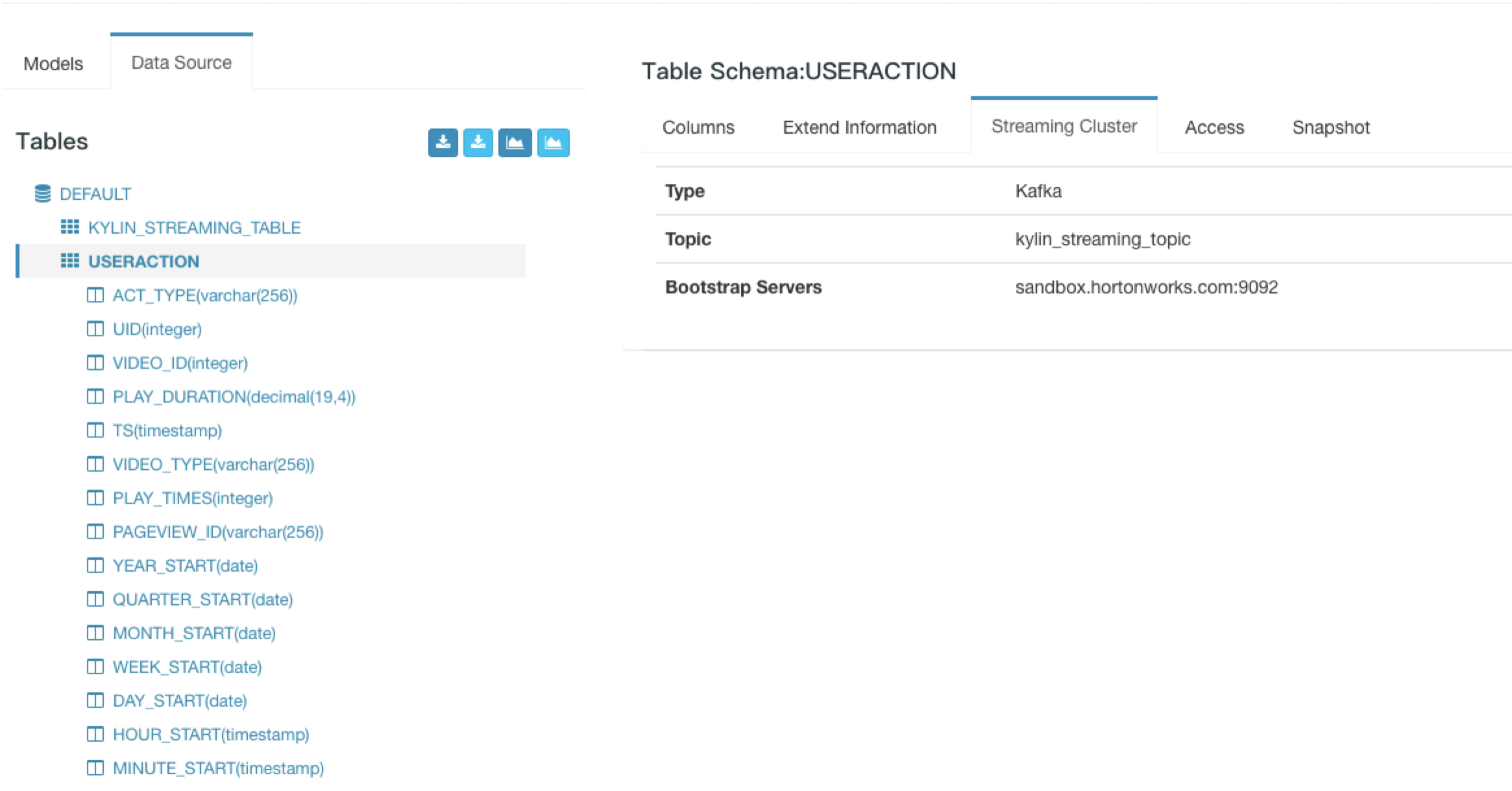
After create streaming table, you can check schema information and kafka cluster information.
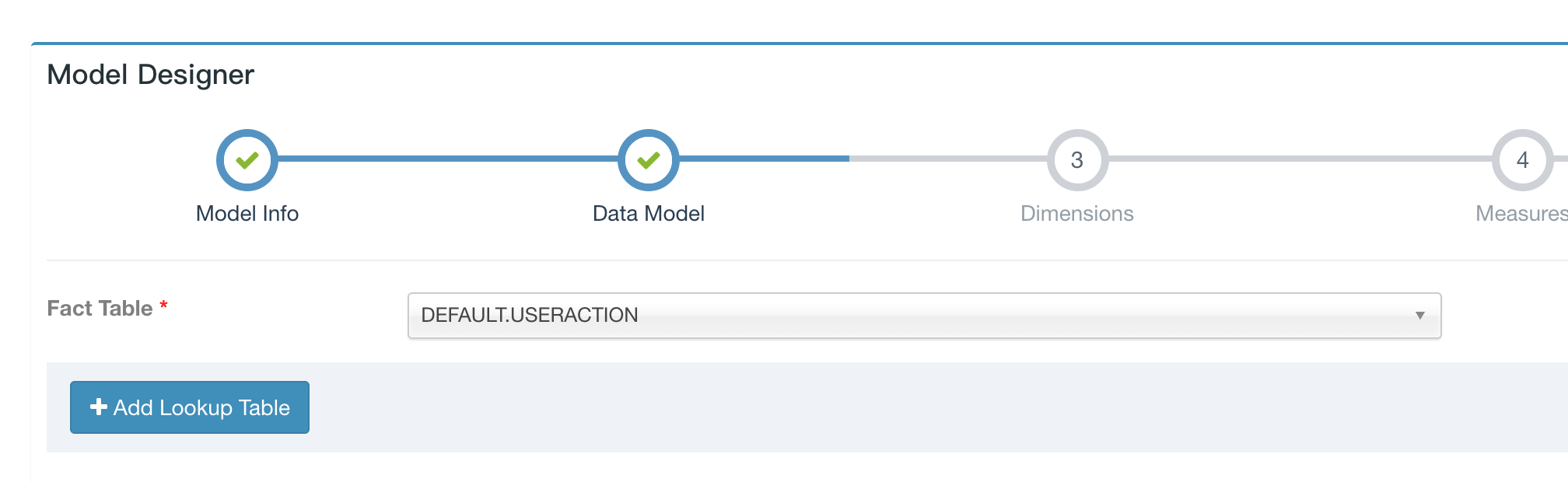
Design Model
Currently, streaming cube does not support join with lookup tables, when define the data model, only select fact table, no lookup table.
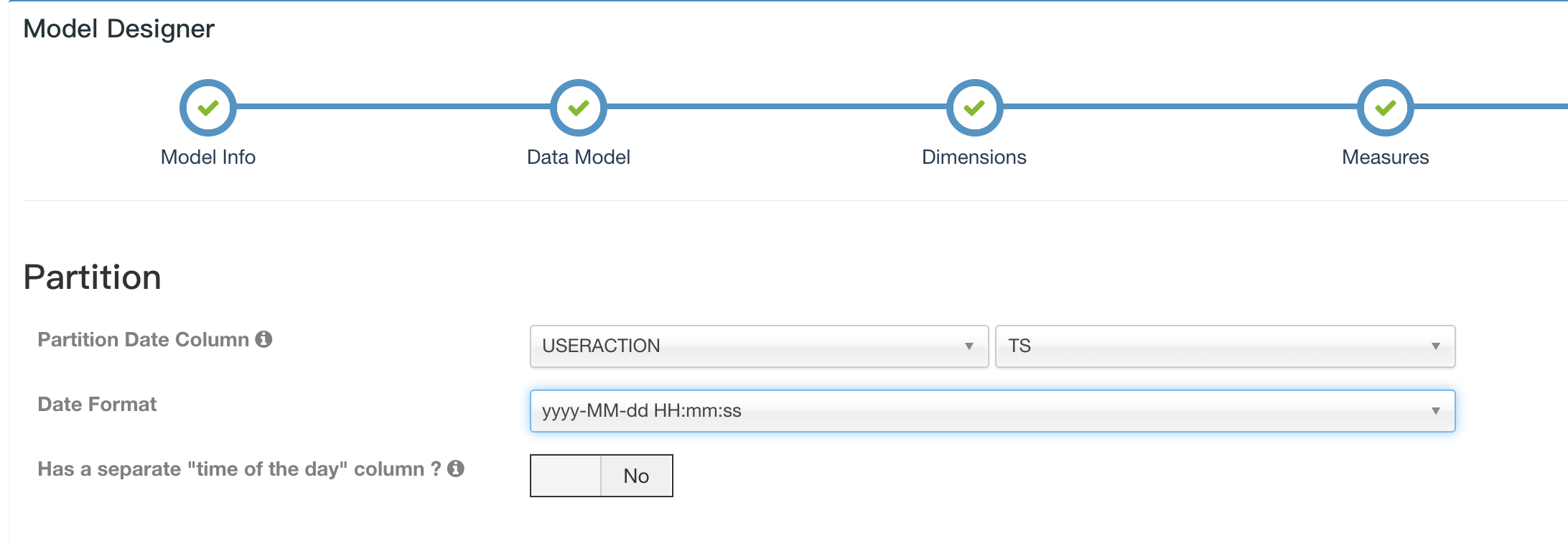
Streaming cube must be partitioned, please choose the timestamp column as partition column.
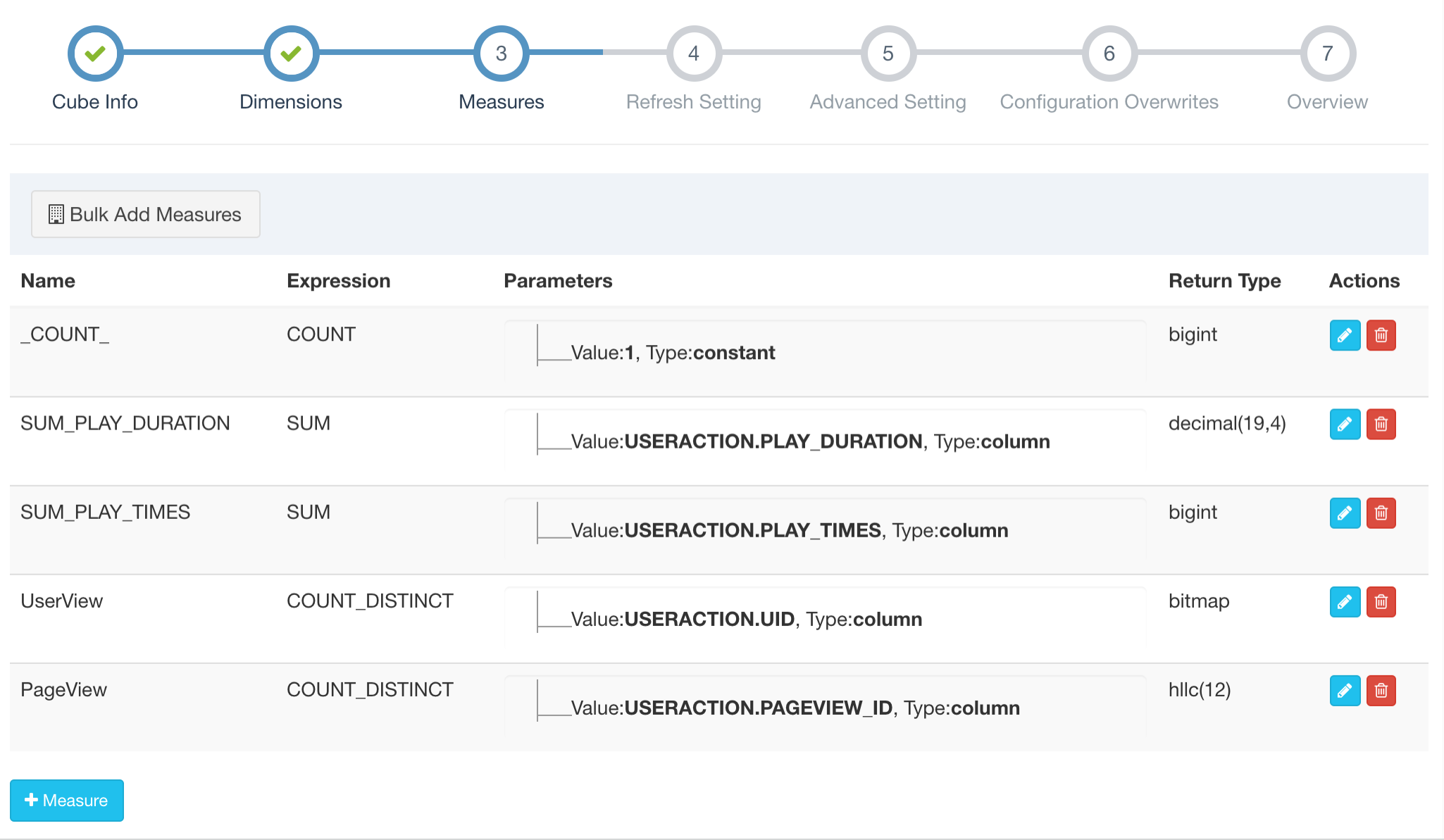
Design Cube
The streaming Cube is almost the same as a normal cube. But a couple of points and options need get your attention:
- Please choose “MapReduce” as your Build Engine, Spark is NOT supported now
- Some measures are not supported : topN is not supported, count_distinct(bitmap) is supported from Kylin 3.0 GA as a beta/preview feature(please see KYLIN-4141 for detail)
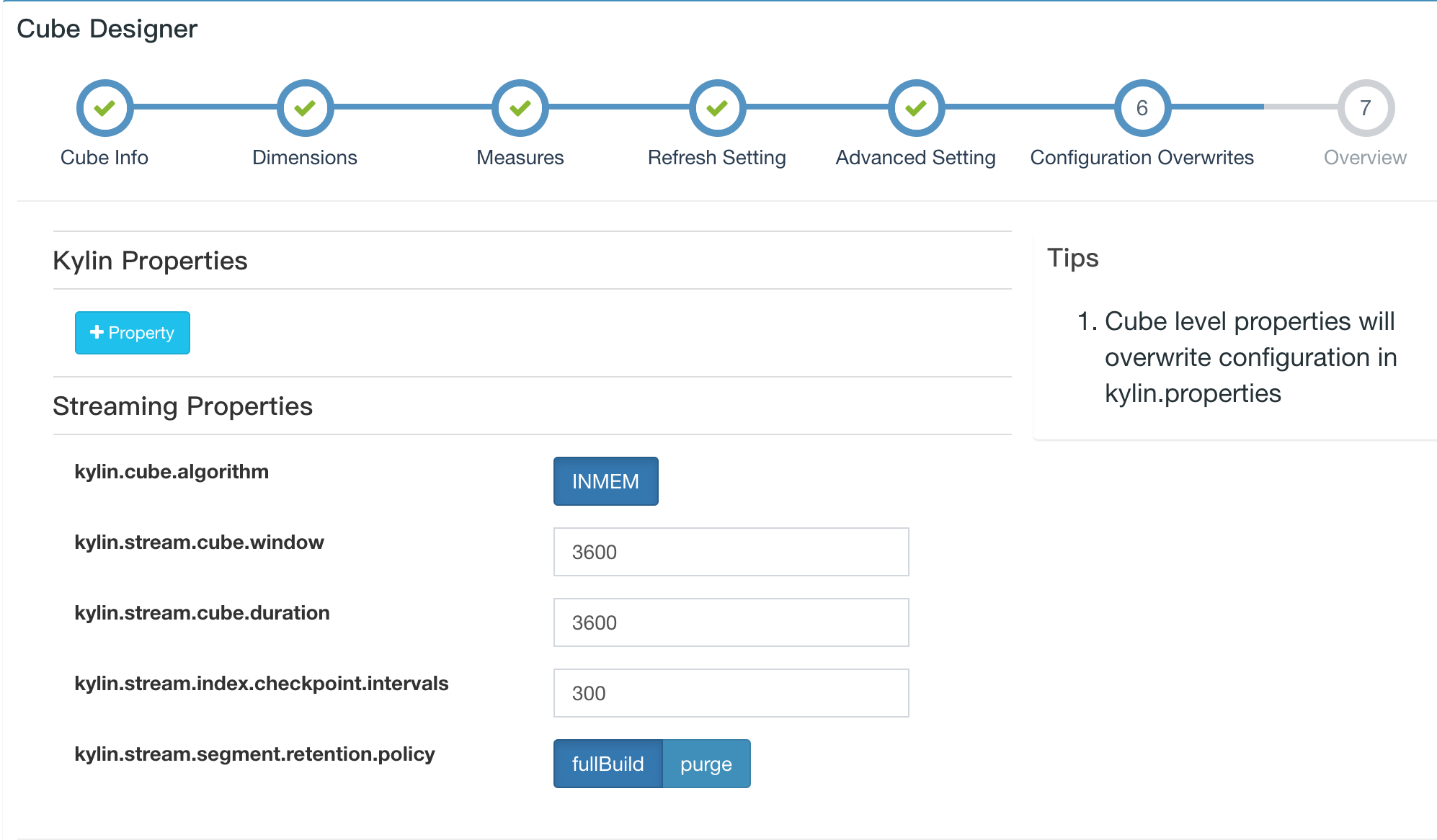
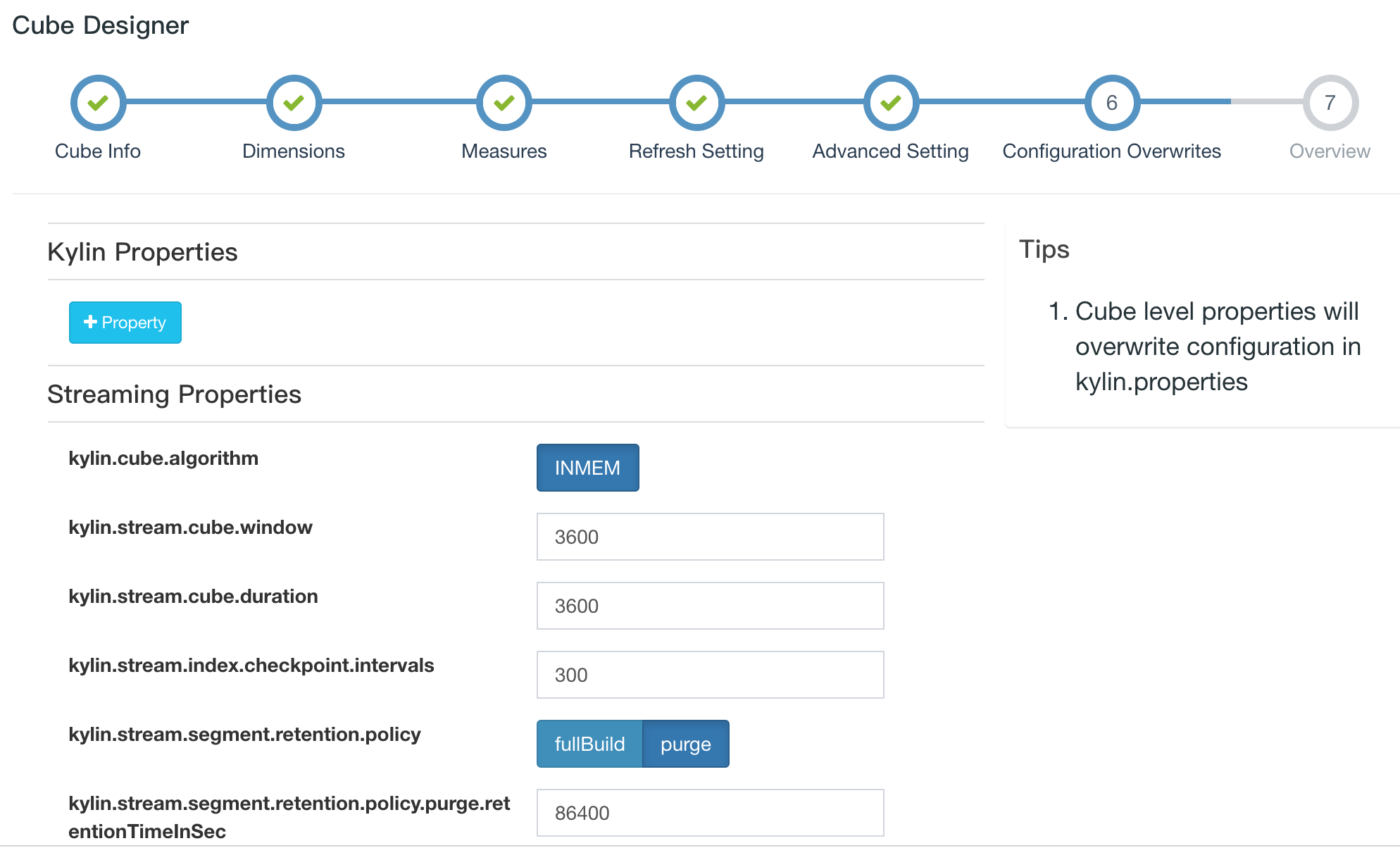
kylin.stream.cube.windowwill decide how event is divided into different segment, it is the length of duration of each segment, value in seconds, default value is 3600kylin.stream.cube.durationdecide how long a segment wait for late eventkylin.stream.segment.retention.policydecide whether to purge or upload local segment cache when sgement become immutablekylin.stream.segment.retention.policy.purge.retentionTimeInSecwhenkylin.stream.segment.retention.policyis set to true, this setting decide the survive duration of immutable segment before they were be purgedkylin.stream.build.additional.cuboidsdecide whether to build addition cuboid on receiver side, if set to true, “Mandatory Cuboids” will be calculated by receiverkylin.stream.cube-num-of-consumer-tasksaffect the number of replica sets be assigned to one topic
Start consumption
Create replica set
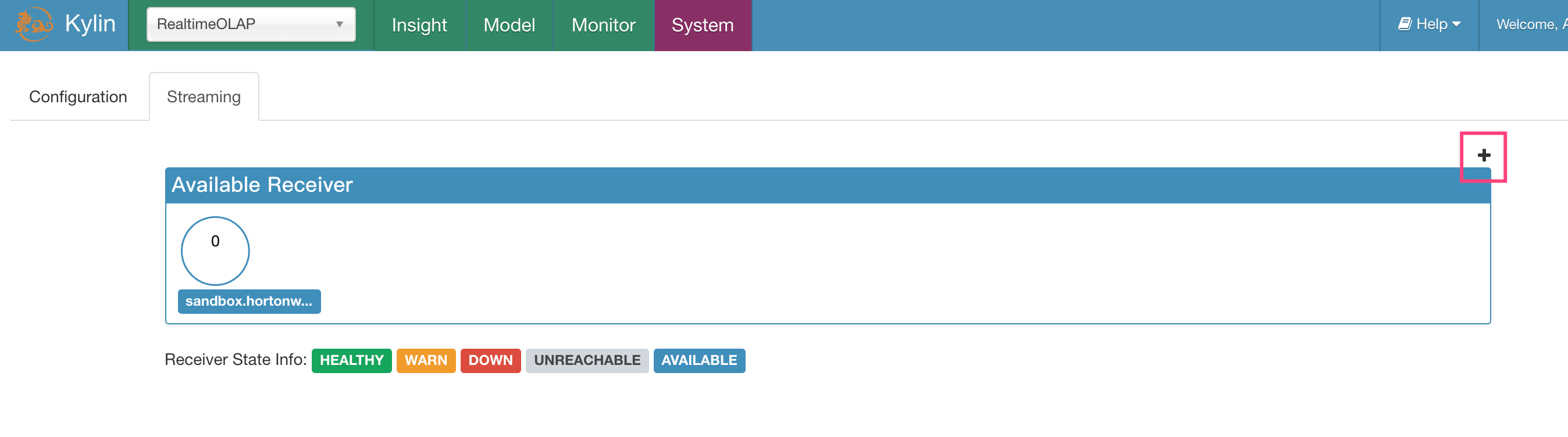
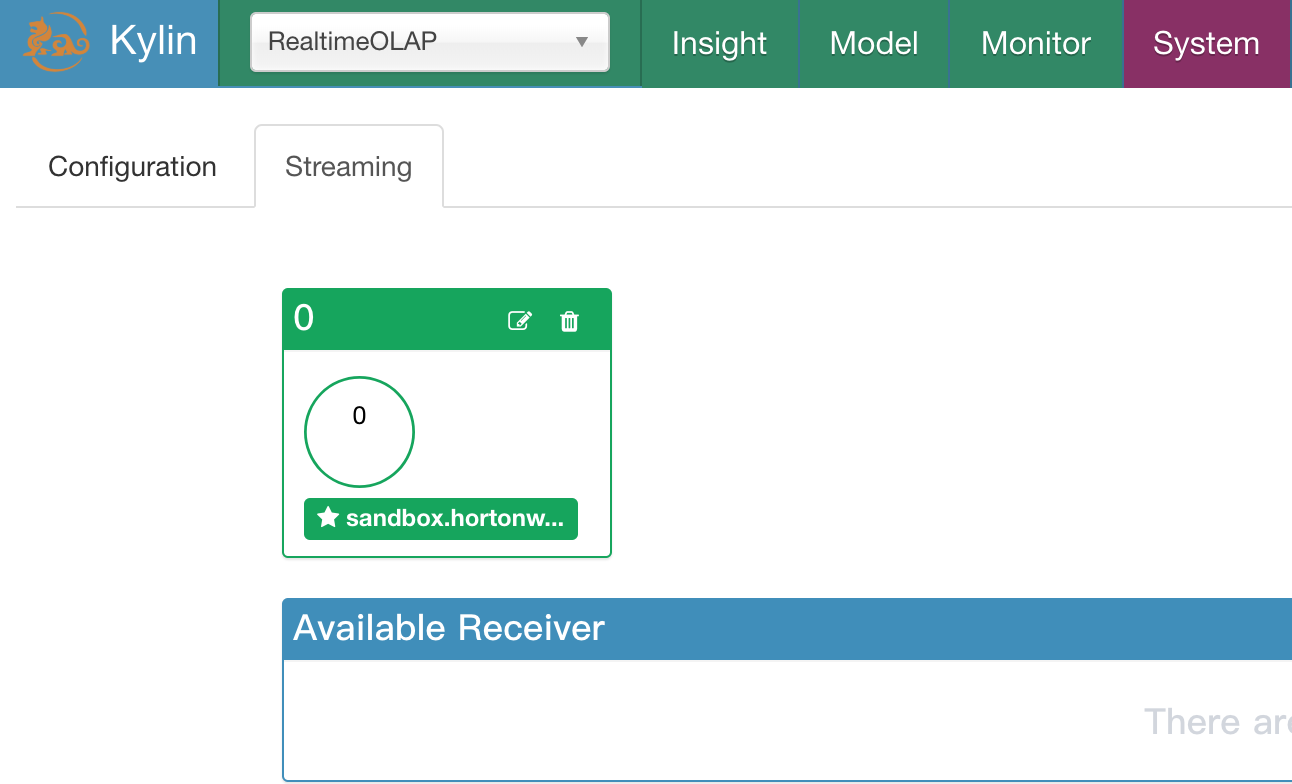
Click the “System” tab and next click the “Streaming” tab. You can see all available receiver listed in a rectangle area. A blue circle with the hostname below indicate a receiver which didn’t belong to any replica set (to be allocated).
Let us create a new replica set by click a small “+” at the top right corner.
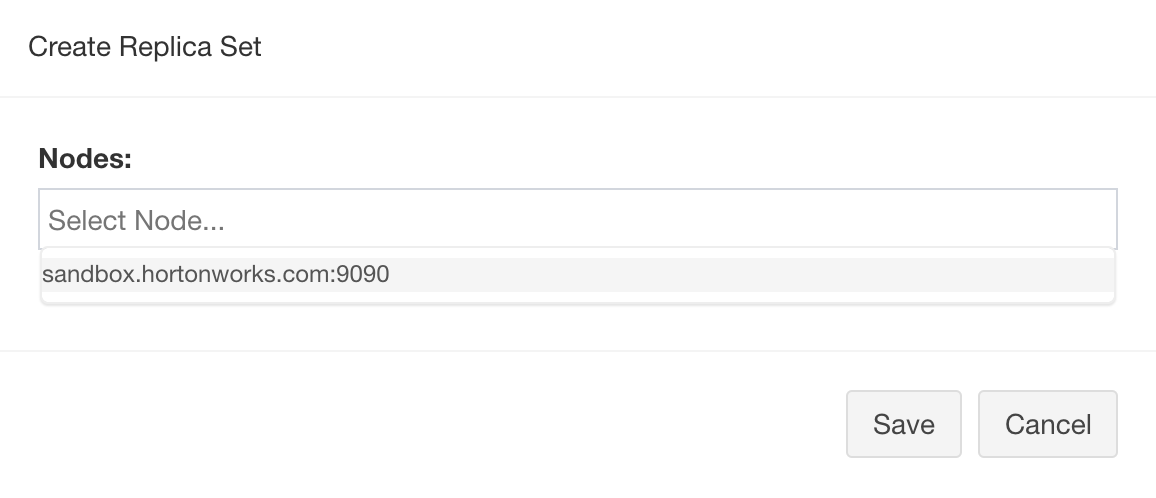
After that, let’s add receiver which you want to be added to the replica set.
If you want to enable HA for receiver, please add more than one receiver for each replica set. But in this tutorial we only has one available receiver, so we add it to new replica set and click “Save” button.
If everything works well, you should see a new green rectangle with a green circle inside, that’s the new replica set. You may find the number “0” on the top left corner, that’s the id of new add replica set. And blue circle disappear because receiver has been allocated to replica set 0.
Enable Consumption
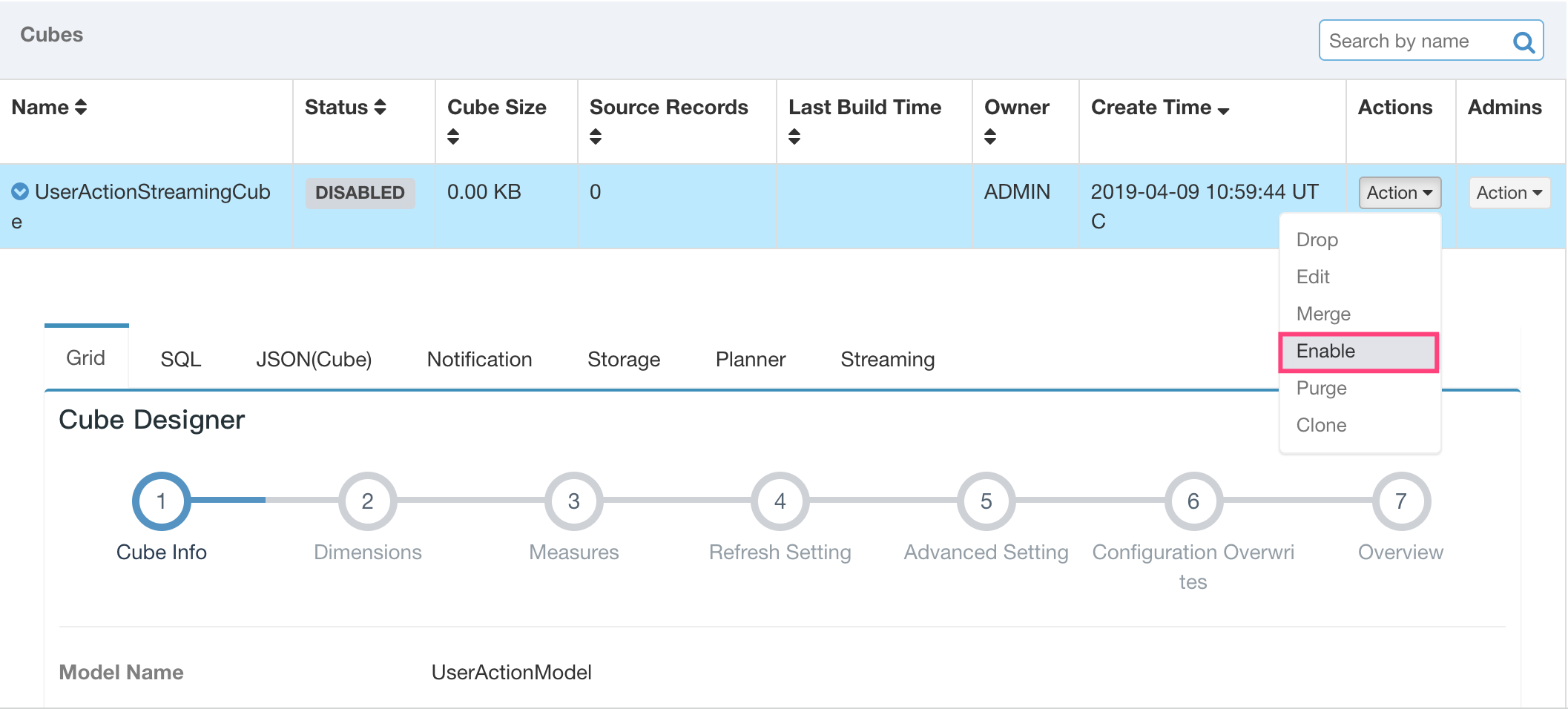
Now we have a replica set 0, so we can assign consumption task to it. Go to the cube design page, find the streaming cube and click “Enable”. Coordinator will choose available replica set and assign consumption task to them. Because we only have one replica set, Coordinator will assign all partitions’ consumption task to replica set 0.
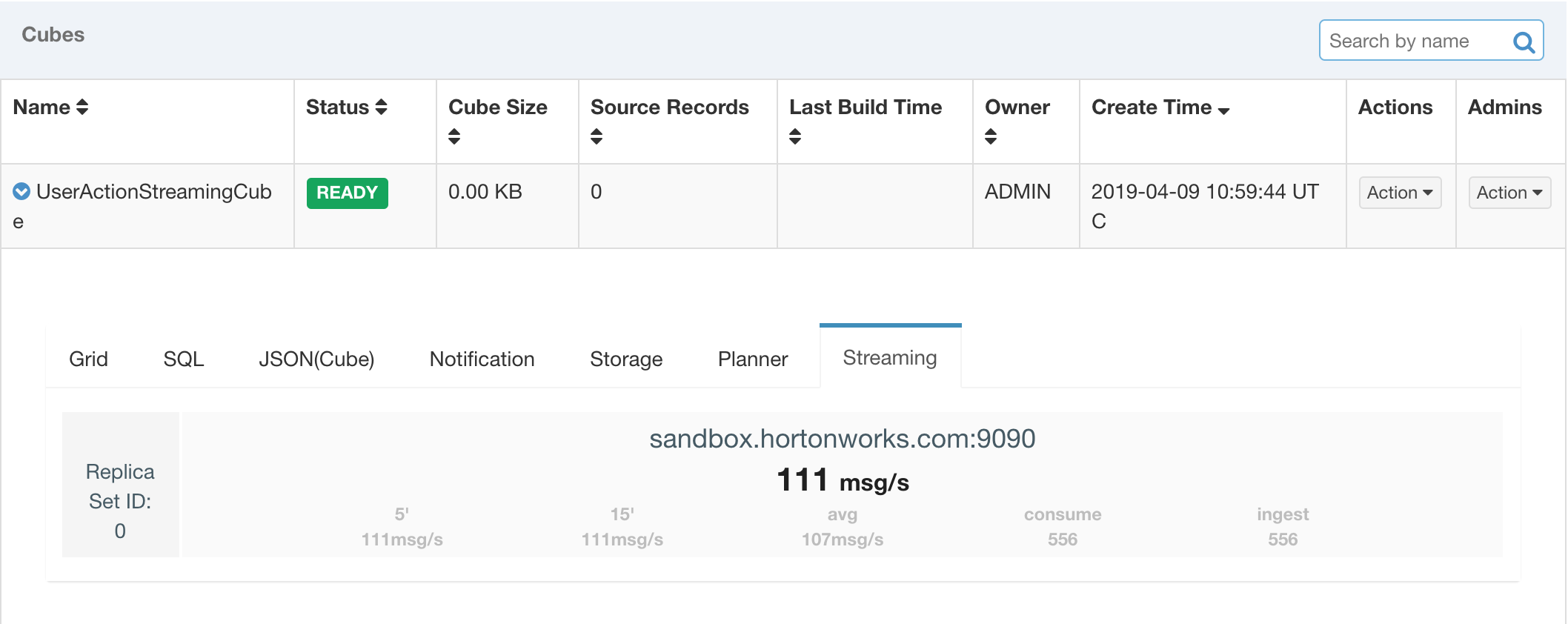
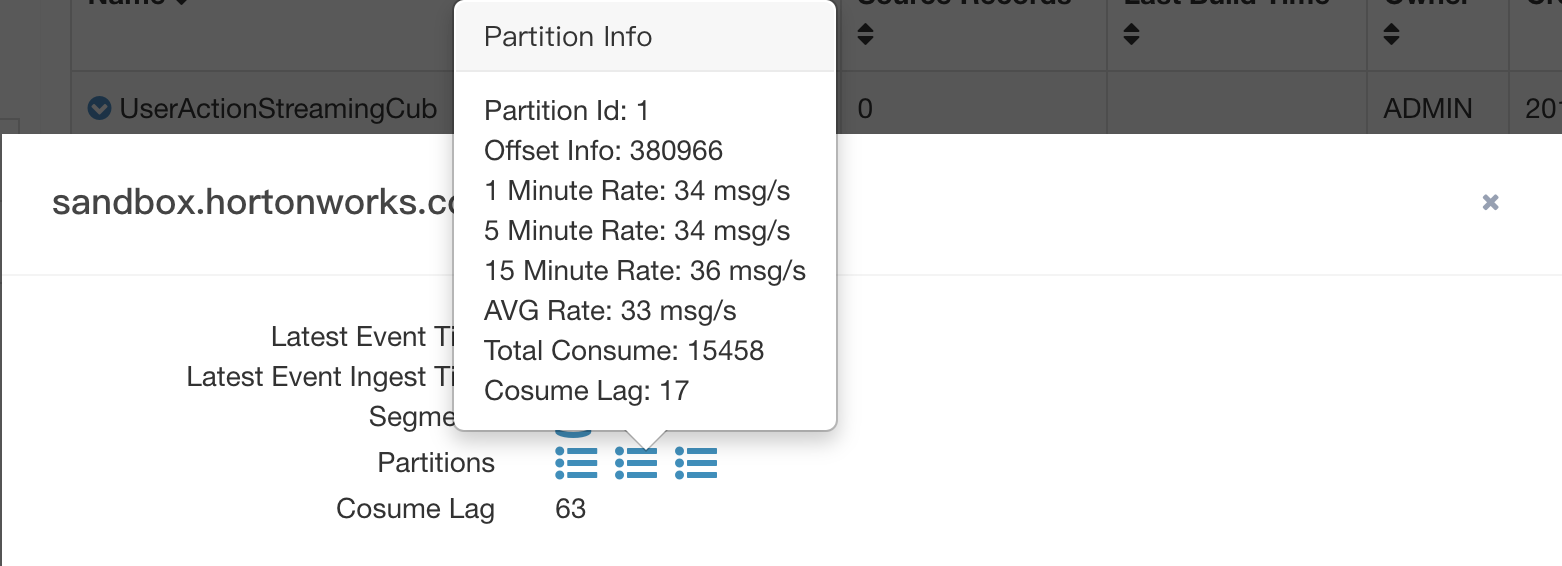
Wait a few seconds, click the small “streaming” tab in streaming cube, you will find consumption statistics information for all assigned replica sets. The bold and larger number in the middle indicate the ingest rate of the latest one minute. The grep and smaller number below indicate(from left to right) :
- ingest rate of the latest five minutes
- ingest rate of the latest fifteen minutes
- average ingest rate since receiver process was started
- the number events be consumed by receiver
- the number events be ingested by receiver
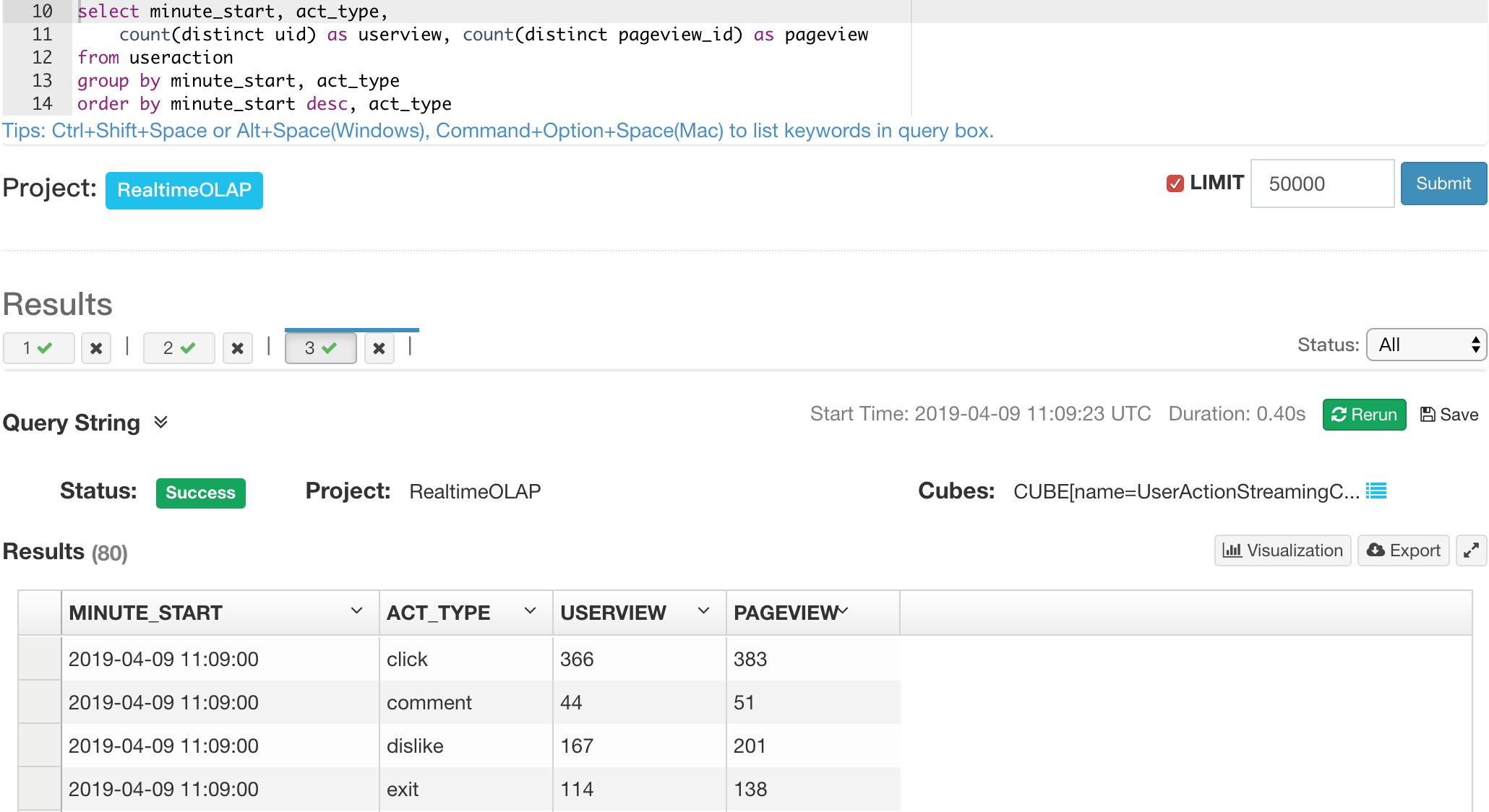
After confirming receiver have ingest a few income events, let’s query streaming cube. The query result show the lastest pageview statistics and userview statistics the last few minutes.
Monitor receiver behavior
If you click each receiver in streaming tab of cube designer page, you will find a pop-up dialogue as below to indicate receiver behavior about assigned consumption task which shows the cube level statistics information.
- Last Event Time: the value of the latest event’s timestamp column
- Latest Event Ingest Time: the moment of latest ingestion
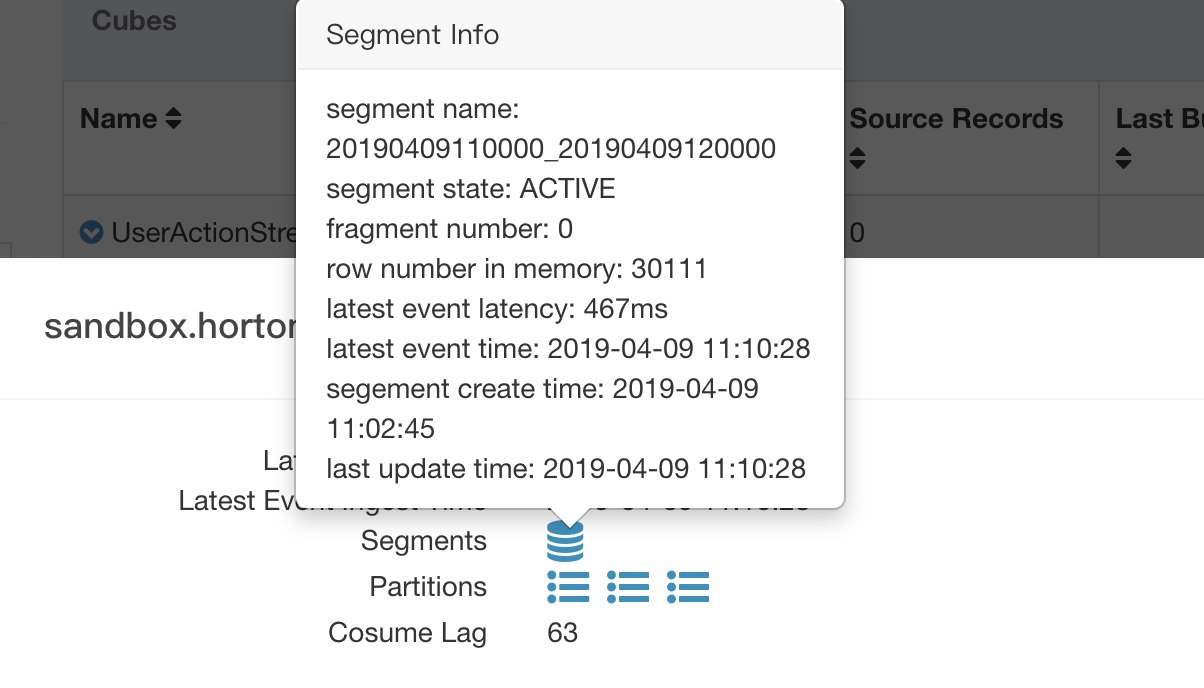
- Segments: all segment which state maybe active/ immutable/ remote persisted.
- Partitions: topic partition which assigned to current receiver
- Consume Lag: total consume lag of all assigned partition

When the mouse pointer moves over the segment icon, the segment level statistics will be displayed.
When the mouse pointer moves over the segment icon, the partition level statistics will be displayed.
Trouble shooting
Metadata clean up
- If you find you have messed up and want to clean up, please remove streaming metadata in Zookeeper.
This can be done by executingrmr PATH_TO_DELETEinzookeeper-clientshell. By default, the root dir of streaming metadata is underkylin.env.zookeeper-base-path+kylin.metadata.url+/stream.
For example, if you setkylin.env.zookeeper-base-pathto/kylin, setkylin.metadata.urltokylin_metadata@hbase, you should delete path/kylin/kylin_metadata/stream.
Port related issue
-
Please make sure that the port 7070 and 9090 is not occupied. If you need to change port, please do this set
kylin.stream.nodeinkylin.propertiesfor receiver or coordinator separately. -
If you find error message in kylin_streaming_receiver.log, like this:
sh 2019-12-26 13:46:40,153 ERROR [main] coordinator.ZookeeperStreamMetadataStore:275 : Error when get coordinator leader com.fasterxml.jackson.core.JsonParseException: Unexpected character ('.' (code 46)): Expected space separating root-level values
The root cause is that the Kylin(Coordinator) process failed to register itself to metadata(zookeeper), so receiver cannot start because it cannot find cluster’s leader. -
If you have more suggestion and question, free free to ask us at user’s mailing list.