
Kylin v2.0 介绍了 Spark cube engine,在 build cube 步骤中使用 Apache Spark 代替 MapReduce;您可以通过查看 这篇博客 的图片了解整体情况。当前的文档使用样例 cube 对如何尝试 new engine 进行了演示。
准备阶段
您需要一个安装了 Kylin v2.1.0 及以上版本的 Hadoop 环境。使用 Hortonworks HDP 2.4 Sandbox VM,其中 Hadoop 组件和 Hive/HBase 已经启动了。
安装 Kylin v2.1.0 及以上版本
从 Kylin 的下载页面下载适用于 HBase 1.x 的 Kylin v2.1.0,然后在 /usr/local/ 文件夹中解压 tar 包:
wget http://www-us.apache.org/dist/kylin/apache-kylin-2.1.0/apache-kylin-2.1.0-bin-hbase1x.tar.gz -P /tmp
tar -zxvf /tmp/apache-kylin-2.1.0-bin-hbase1x.tar.gz -C /usr/local/
export KYLIN_HOME=/usr/local/apache-kylin-2.1.0-bin-hbase1x准备 “kylin.env.hadoop-conf-dir”
为使 Spark 运行在 Yarn 上,需指定 HADOOP_CONF_DIR 环境变量,其是一个包含 Hadoop(客户端) 配置文件的目录,通常是 /etc/hadoop/conf。
通常 Kylin 会在启动时从 Java classpath 上检测 Hadoop 配置目录,并使用它来启动 Spark。 如果您的环境中未能正确发现此目录,那么可以显式地指定此目录:在 kylin.properties 中设置属性 “kylin.env.hadoop-conf-dir” 好让 Kylin 知道这个目录:
kylin.env.hadoop-conf-dir=/etc/hadoop/conf检查 Spark 配置
Kylin 在 $KYLIN_HOME/spark 中嵌入一个 Spark binary (v2.1.2),所有使用 “kylin.engine.spark-conf.” 作为前缀的 Spark 配置属性都能在 $KYLIN_HOME/conf/kylin.properties 中进行管理。这些属性当运行提交 Spark job 时会被提取并应用;例如,如果您配置 “kylin.engine.spark-conf.spark.executor.memory=4G”,Kylin 将会在执行 “spark-submit” 操作时使用 “–conf spark.executor.memory=4G” 作为参数。
运行 Spark cubing 前,建议查看一下这些配置并根据您集群的情况进行自定义。下面是建议配置,开启了 Spark 动态资源分配:
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
kylin.engine.spark-conf.spark.dynamicAllocation.enabled=true
kylin.engine.spark-conf.spark.dynamicAllocation.minExecutors=1
kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors=1000
kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout=300
kylin.engine.spark-conf.spark.yarn.queue=default
kylin.engine.spark-conf.spark.driver.memory=2G
kylin.engine.spark-conf.spark.executor.memory=4G
kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024
kylin.engine.spark-conf.spark.executor.cores=1
kylin.engine.spark-conf.spark.network.timeout=600
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
#kylin.engine.spark-conf.spark.executor.instances=1
kylin.engine.spark-conf.spark.eventLog.enabled=true
kylin.engine.spark-conf.spark.hadoop.dfs.replication=2
kylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress=true
kylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
kylin.engine.spark-conf.spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec
kylin.engine.spark-conf.spark.eventLog.dir=hdfs\:///kylin/spark-history
kylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs\:///kylin/spark-history
## uncomment for HDP
#kylin.engine.spark-conf.spark.driver.extraJavaOptions=-Dhdp.version=current
#kylin.engine.spark-conf.spark.yarn.am.extraJavaOptions=-Dhdp.version=current
#kylin.engine.spark-conf.spark.executor.extraJavaOptions=-Dhdp.version=current为了在 Hortonworks 平台上运行,需要将 “hdp.version” 指定为 Yarn 容器的 Java 选项,因此请取消 kylin.properties 的最后三行的注释。
除此之外,为了避免重复上传 Spark jar 包到 Yarn,您可以手动上传一次,然后配置 jar 包的 HDFS 路径;请注意,HDFS 路径必须是全路径名。
jar cv0f spark-libs.jar -C $KYLIN_HOME/spark/jars/ .
hadoop fs -mkdir -p /kylin/spark/
hadoop fs -put spark-libs.jar /kylin/spark/然后,要在 kylin.properties 中进行如下配置:
kylin.engine.spark-conf.spark.yarn.archive=hdfs://sandbox.hortonworks.com:8020/kylin/spark/spark-libs.jar所有 “kylin.engine.spark-conf.*” 参数都可以在 Cube 或 Project 级别进行重写,这为用户提供了灵活性。
创建和修改样例 cube
运行 sample.sh 创建样例 cube,然后启动 Kylin 服务器:
$KYLIN_HOME/bin/sample.sh
$KYLIN_HOME/bin/kylin.sh startKylin 启动后,访问 Kylin 网站,在 “Advanced Setting” 页,编辑名为 “kylin_sales” 的 cube,将 “Cube Engine” 由 “MapReduce” 换成 “Spark”:

点击 “Next” 进入 “Configuration Overwrites” 页面,点击 “+Property” 添加属性 “kylin.engine.spark.rdd-partition-cut-mb” 其值为 “500” (理由如下):

样例 cube 有两个耗尽内存的度量: “COUNT DISTINCT” 和 “TOPN(100)”;当源数据较小时,他们的大小估计的不太准确: 预估的大小会比真实的大很多,导致了更多的 RDD partitions 被切分,使得 build 的速度降低。500 对于其是一个较为合理的数字。点击 “Next” 和 “Save” 保存 cube。
对于没有”COUNT DISTINCT” 和 “TOPN” 的 cube,请保留默认配置。
用 Spark 构建 Cube
点击 “Build”,选择当前日期为 end date。Kylin 会在 “Monitor” 页生成一个构建 job,第 7 步是 Spark cubing。Job engine 开始按照顺序执行每一步。

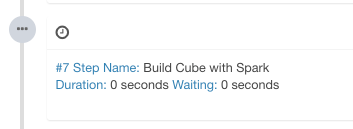
当 Kylin 执行这一步时,您可以监视 Yarn 资源管理器里的状态. 点击 “Application Master” 链接将会打开 Spark 的 UI 网页,它会显示每一个 stage 的进度以及详细的信息。
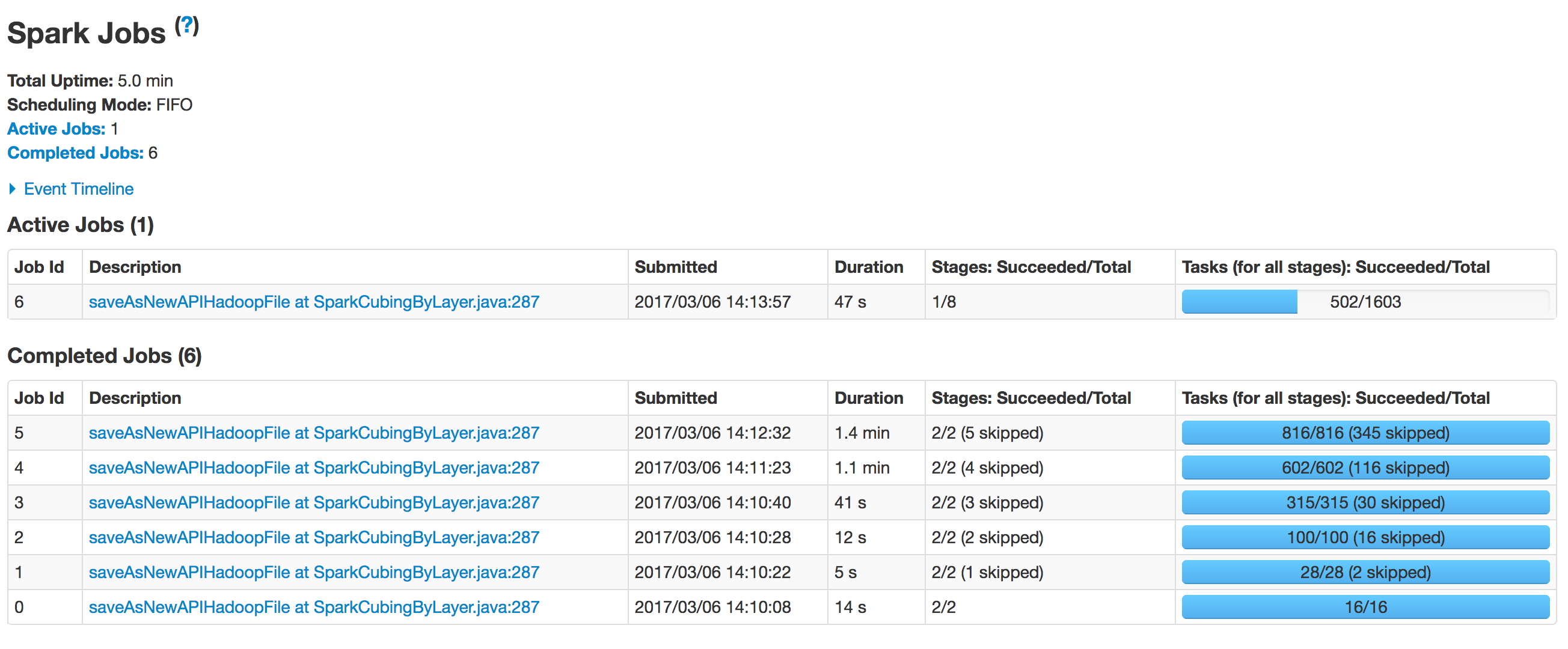
所有步骤成功执行后,Cube 的状态变为 “Ready” 且您可以像往常那样进行查询。
通过Apache Livy使用Spark
开启使用Livy需要修改如下配置:
kylin.engine.livy-conf.livy-enabled=true
kylin.engine.livy-conf.livy-url=http://ip:8998
kylin.engine.livy-conf.livy-key.file=hdfs:///path/kylin-job-3.0.0-SNAPSHOT.jar
kylin.engine.livy-conf.livy-arr.jars=hdfs:///path/hbase-client-1.2.0-{$env.version}.jar,hdfs:///path/hbase-common-1.2.0-{$env.version}.jar,hdfs:///path/hbase-hadoop-compat-1.2.0-{$env.version}.jar,hdfs:///path/hbase-hadoop2-compat-1.2.0-{$env.version}.jar,hdfs:///path/hbase-server-1.2.0-{$env.version}.jar,hdfs:///path/htrace-core-3.2.0-incubating.jar,hdfs:///path/metrics-core-2.2.0.jar需要注意的是jar包路径之间不能存在空格。
可选功能
现在构建步骤中的’extract fact table distinct value’ 和 ‘build dimension dictionary’ 两个步骤也可以使用Spark进行构建了。相关的配置如下:
kylin.engine.spark-fact-distinct=true
kylin.engine.spark-dimension-dictionary=true
kylin.engine.spark-uhc-dictionary=true疑难解答
当出现 error,您可以首先查看 “logs/kylin.log”. 其中包含 Kylin 执行的所有 Spark 命令,例如:
2017-03-06 14:44:38,574 INFO [Job 2d5c1178-c6f6-4b50-8937-8e5e3b39227e-306] spark.SparkExecutable:121 : cmd:export HADOOP_CONF_DIR=/usr/local/apache-kylin-2.1.0-bin-hbase1x/hadoop-conf && /usr/local/apache-kylin-2.1.0-bin-hbase1x/spark/bin/spark-submit --class org.apache.kylin.common.util.SparkEntry --conf spark.executor.instances=1 --conf spark.yarn.queue=default --conf spark.yarn.am.extraJavaOptions=-Dhdp.version=current --conf spark.history.fs.logDirectory=hdfs:///kylin/spark-history --conf spark.driver.extraJavaOptions=-Dhdp.version=current --conf spark.master=yarn --conf spark.executor.extraJavaOptions=-Dhdp.version=current --conf spark.executor.memory=1G --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs:///kylin/spark-history --conf spark.executor.cores=2 --conf spark.submit.deployMode=cluster --files /etc/hbase/2.4.0.0-169/0/hbase-site.xml --jars /usr/hdp/2.4.0.0-169/hbase/lib/htrace-core-3.1.0-incubating.jar,/usr/hdp/2.4.0.0-169/hbase/lib/hbase-client-1.1.2.2.4.0.0-169.jar,/usr/hdp/2.4.0.0-169/hbase/lib/hbase-common-1.1.2.2.4.0.0-169.jar,/usr/hdp/2.4.0.0-169/hbase/lib/hbase-protocol-1.1.2.2.4.0.0-169.jar,/usr/hdp/2.4.0.0-169/hbase/lib/metrics-core-2.2.0.jar,/usr/hdp/2.4.0.0-169/hbase/lib/guava-12.0.1.jar,/usr/local/apache-kylin-2.1.0-bin-hbase1x/lib/kylin-job-2.1.0.jar -className org.apache.kylin.engine.spark.SparkCubingByLayer -hiveTable kylin_intermediate_kylin_sales_cube_555c4d32_40bb_457d_909a_1bb017bf2d9e -segmentId 555c4d32-40bb-457d-909a-1bb017bf2d9e -confPath /usr/local/apache-kylin-2.1.0-bin-hbase1x/conf -output hdfs:///kylin/kylin_metadata/kylin-2d5c1178-c6f6-4b50-8937-8e5e3b39227e/kylin_sales_cube/cuboid/ -cubename kylin_sales_cube您可以拷贝 cmd 以便在 shell 中手动执行,然后快速进行参数调整;执行期间,您可以访问 Yarn 资源管理器查看更多的消息。如果 job 已经完成了,您可以在 Spark history server 中查看历史信息。
Kylin 默认将历史信息输出到 “hdfs:///kylin/spark-history”,您需要在该目录下启动 Spark history server,或在 conf/kylin.properties 中使用参数 “kylin.engine.spark-conf.spark.eventLog.dir” 和 “kylin.engine.spark-conf.spark.history.fs.logDirectory” 替换为您已存在的 Spark history server 的事件目录。
下面的命令可以在 Kylin 的输出目录下启动一个 Spark history server 实例,运行前请确保 sandbox 中已存在的 Spark history server 关闭了:
$KYLIN_HOME/spark/sbin/start-history-server.sh hdfs://sandbox.hortonworks.com:8020/kylin/spark-history浏览器访问 “http://sandbox:18080” 将会显示 job 历史:
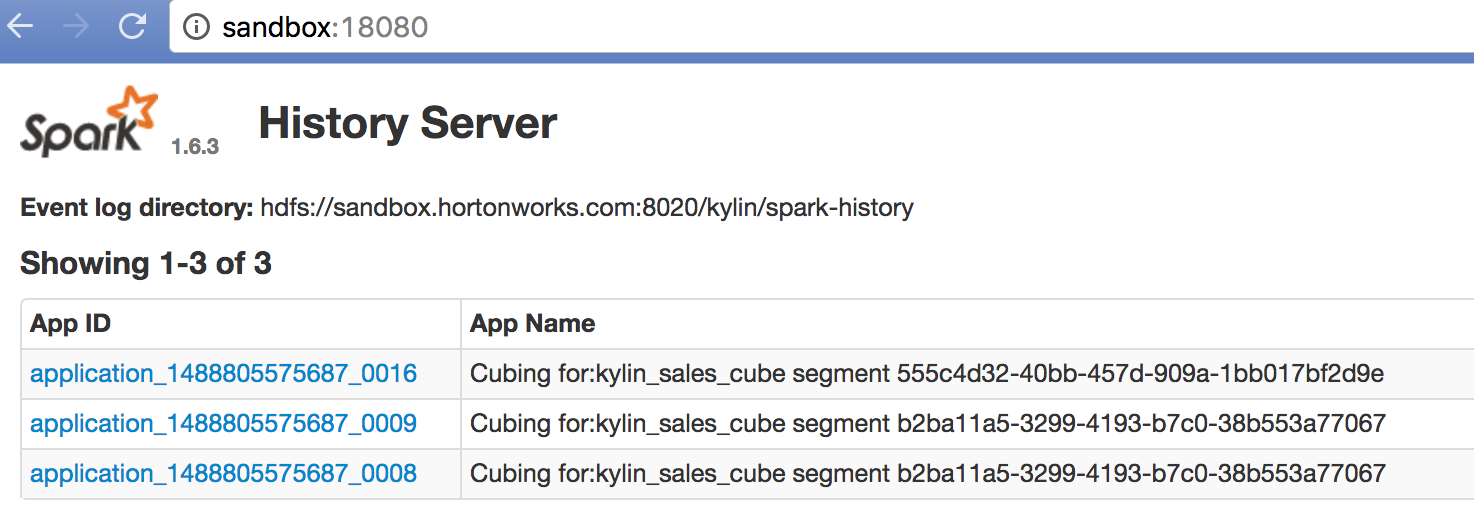
点击一个具体的 job,运行时的具体信息将会展示,该信息对疑难解答和性能调整有极大的帮助。
在某些 Hadoop 版本上, 在 “Convert Cuboid Data to HFile” 这一步可能会遇到下面这个错误:
Caused by: java.lang.RuntimeException: Could not create interface org.apache.hadoop.hbase.regionserver.MetricsRegionServerSourceFactory Is the hadoop compatibility jar on the classpath?
at org.apache.hadoop.hbase.CompatibilitySingletonFactory.getInstance(CompatibilitySingletonFactory.java:73)
at org.apache.hadoop.hbase.io.MetricsIO.<init>(MetricsIO.java:31)
at org.apache.hadoop.hbase.io.hfile.HFile.<clinit>(HFile.java:192)
... 15 more
Caused by: java.util.NoSuchElementException
at java.util.ServiceLoader$LazyIterator.nextService(ServiceLoader.java:365)
at java.util.ServiceLoader$LazyIterator.next(ServiceLoader.java:404)
at java.util.ServiceLoader$1.next(ServiceLoader.java:480)
at org.apache.hadoop.hbase.CompatibilitySingletonFactory.getInstance(CompatibilitySingletonFactory.java:59)
... 17 more解决办法是: 将 hbase-hadoop2-compat-*.jar 和 hbase-hadoop-compat-*.jar 拷贝到 $KYLIN_HOME/spark/jars 目录下 (这两个 jar 文件可以从 HBase 的 lib 目录找到); 如果你已经生成了 Spark assembly jar 并上传到了 HDFS, 那么你需要重新打包上传。在这之后,重试失败的 cube 任务,应该就可以成功了。相关的 JIRA issue 是 KYLIN-3607,会在未来版本修复.
进一步
如果您是 Kylin 的管理员但是对于 Spark 是新手,建议您浏览 Spark 文档,别忘记相应地去更新配置。您可以开启 Spark 的 Dynamic Resource Allocation ,以便其对于不同的工作负载能自动伸缩。Spark 性能依赖于集群的内存和 CPU 资源,当有复杂数据模型和巨大的数据集一次构建时 Kylin 的 Cube 构建将会是一项繁重的任务。如果您的集群资源不能够执行,Spark executors 就会抛出如 “OutOfMemorry” 这样的错误,因此请合理的使用。对于有 UHC dimension,过多组合 (例如,一个 cube 超过 12 dimensions),或耗尽内存的度量 (Count Distinct,Top-N) 的 Cube,建议您使用 MapReduce engine。如果您的 Cube 模型较为简单,所有度量都是 SUM/MIN/MAX/COUNT,源数据规模小至中等,Spark engine 将会是个好的选择。
如果您有任何问题,意见,或 bug 修复,欢迎在 dev@kylin.apache.org 中讨论。