
This tutorial is an example step by step about how to optimize build of cube.
In this scenario we’re trying to optimize a very simple Cube, with 1 fact and 1 lookup table (Date Dimension). Before do a real tunning, please get an overall understanding about Cube build process from Optimize Cube Build
The baseline is:
- One Measure: Balance, calculate always Max, Min and Count
- All Dim_date (10 items) will be used as dimensions
- Input is a Hive CSV external table
- Output is a Cube in HBase without compression
With this configuration, the results are: 13 min to build a cube of 20 Mb (Cube_01)
Cube_02: Reduce combinations
To make the first improvement, use Joint and Hierarchy on Dimensions to reduce the combinations (number of cuboids).
Put together all ID and Text of: Month, Week, Weekday and Quarter using Joint Dimension
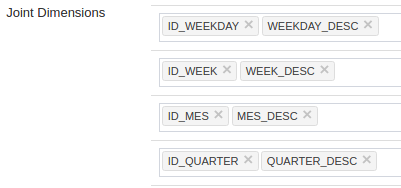
Define Id_date and Year as a Hierarchy Dimension
This reduces the size down to 0.72MB and time to 5 min
Kylin 2149, ideally, these Hierarchies can be defined also:
* Id_weekday > Id_date
* Id_Month > Id_date
* Id_Quarter > Id_date
* Id_week > Id_date
But for now, it impossible to use Joint and Hierarchy together for one dimension.
Cube_03: Compress output
To make the next improvement, compress HBase Cube with Snappy:

Another option is Gzip:

The results of compression output are:
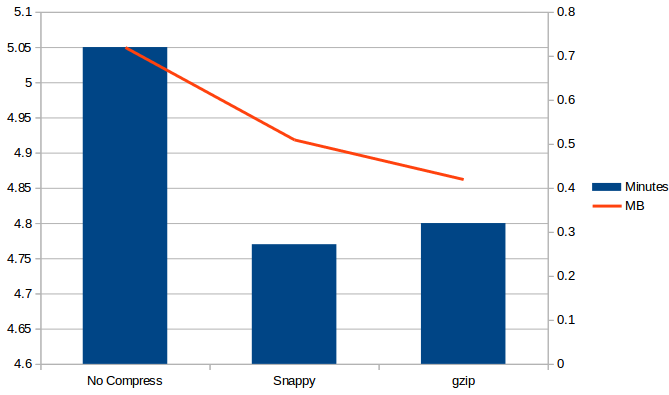
The difference between Snappy and Ggzip in time is less than 1% but in size it is 18%
Cube_04: Compress Hive table
The time distribution is like this:
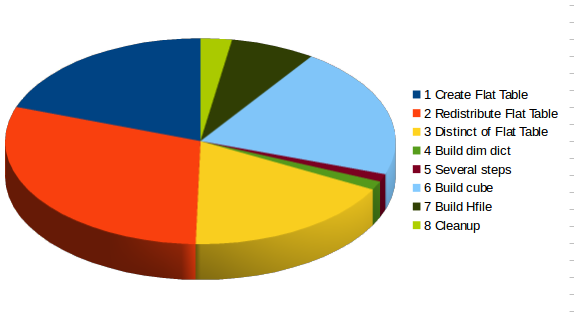
Group detailed times by concepts :
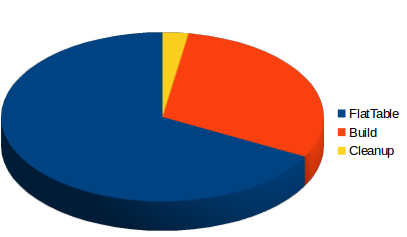
67 % is used to build / process flat table and respect 30% to build the cube
A lot of time is used in the first steps.
This time distribution is typical in a cube with few measures and few dim (or very optimized)
Try to use ORC Format and compression on Hive input table (Snappy):
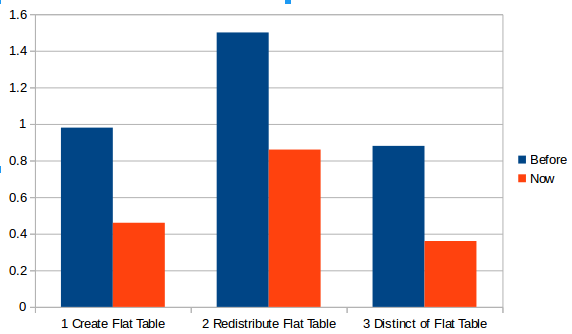
The time in the first three steps (Flat Table) has been improved by half.
Other columnar formats can be tested:
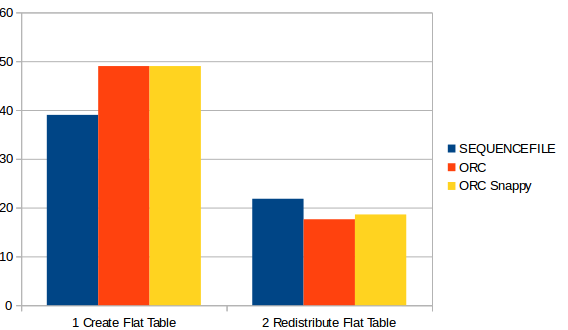
- ORC
- ORC compressed with Snappy
But the results are worse than when using Sequence file.
See comments about this here: Shaofengshi in MailList
The second strep is to redistribute Flat Hive table:
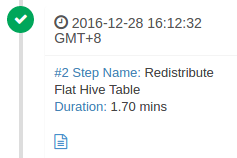
Is a simple row count, two approximations can be made
* If it doesn’t need to be accurate, the rows of the fact table can be counted→ this can be performed in parallel with Step 1 (and 99% of the time it will be accurate)

- In the future versions (KYLIN-2165 v2.0), this steps will be implemented using Hive table statistics.
Cube_05: Partition Hive table (fail)
The distribution of rows is:
| Table | Rows |
|---|---|
| Fact Table | 3.900.00 |
| Dim Date | 2.100 |
And the query (the simplified version) to build the flat table is:
```sql
SELECT
,DIM_DATE.X
,DIM_DATE.y
,FACT_POSICIONES.BALANCE
FROM FACT_POSICIONES INNER JOIN DIM_DATE
ON ID_FECHA = .ID_FECHA
WHERE (ID_DATE >= '2016-12-08' AND ID_DATE < '2016-12-23')
```The problem here, is that, Hive in only using 1 Map to create Flat Table. It is important to lets go to change this behavior. The solution is to partition DIM and FACT in the same columns
- Option 1: Use id_date as a partition column on Hive table. This has a big problem: the Hive metastore is meant for few a hundred of partitions and not thousands (In Hive 9452 there is an idea to solve this but it isn’t finished yet)
- Option 2: Generate a new column for this purpose like Monthslot.
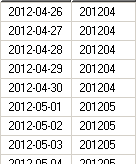
Add the same column to dim and fact tables
Now, upgrade the the data model with this new condition to join tables
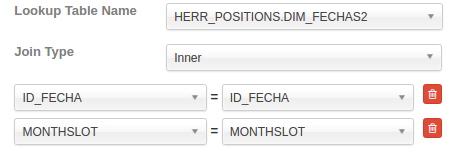
The new query to generate flat table will be similar to:
```sql
SELECT *
FROM FACT_POSICIONES **INNER JOIN** DIM_DATE
ON ID_FECHA = .ID_FECHA AND MONTHSLOT=MONTHSLOT
```Rebuild the new cube with this data model
As a result, the performance has worsened :( . After tried several attempts, there hasn’t been a solution
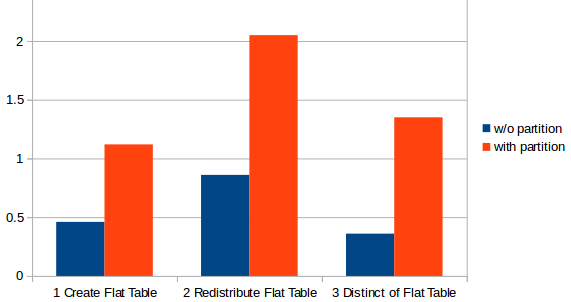
The problem is that partitions were not used to generate several Mappers

(I checked this issue with ShaoFeng Shi. He thinks the problem is that there are few many rows and we are not working with a real Hadoop cluster. See this tech note).
Resume of results
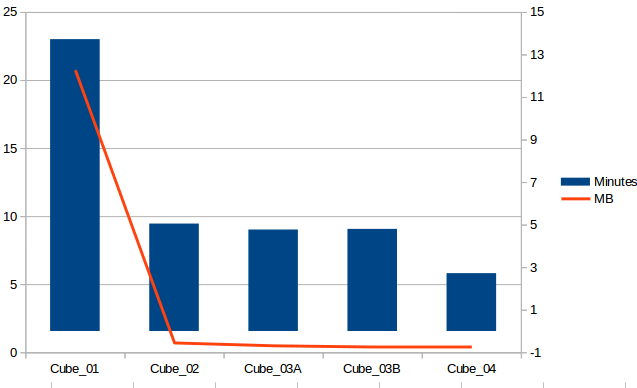
The tunning process has been:
* Hive Input tables compressed
* HBase Output compressed
* Apply techniques of reduction of cardinality (Joint, Derived, Hierarchy and Mandatory)
* Personalize Dim encoder for each Dim and choose the best order of Dim in Row Key
Now, there are three types of cubes:
* Cubes with low cardinality in their dimensions (Like cube 4, most of time is used in flat table steps)
* Cubes with high cardinality in their dimensions (Like cube 6,most of time is used on Build cube, the flat table steps are lower than 10%)
* The third type, ultra high cardinality (UHC) which is outside the scope of this article
Cube 6: Cube with high cardinality Dimensions
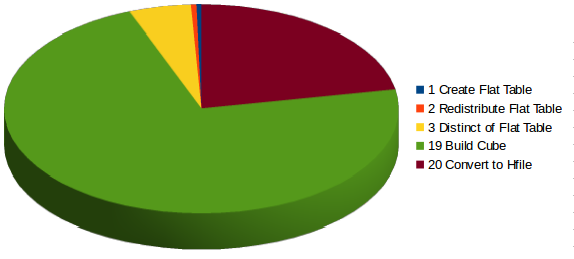
In this case the 72% of the time is used to build Cube
This step is a MapReduce task, you can see the YARN log of these steps on  >
> 
How can the performance of Map – Reduce be improved? The easy way is to increase the numbers of Mappers and Reduces (= Increase parallelism).
NOTE: YARN / MapReduce have a lot parameters to configure and adapt to the your system. The focus here is only on small parts.
(In my system I can assign 12 – 14 GB and 8 cores to YARN Resources):
- yarn.nodemanager.resource.memory-mb = 15 GB
- yarn.scheduler.maximum-allocation-mb = 8 GB
- yarn.nodemanager.resource.cpu-vcores = 8 cores
With this config our max theoretical orical grade of parallelism list is 8. However, but this has a problem: “Timed out after 3600 secs”

The parameter mapreduce.task.timeout (1 hour by default) define max time that Application Master (AM) can happen with out ACK of Yarn Container. Once this time passes, AM kill the container and retry the same 4 times (with the same result)
Where is the problem? The problem is that 4 mappers started, but each mapper needed more than 4 GB to finish
- The solution 1: add more RAM to YARN
- The solution 2: increase vCores number used in Mapper step to reduce the RAM used
- The solution 3: you can play with max RAM to YARN by node (yarn.nodemanager.resource.memory-mb) and experiment with minimum RAM per to container (yarn.scheduler.minimum-allocation-mb). If you increase minimum RAM per container, YARN will reduce the numbers of Mappers
In the last two cases the results are the same: reduce the level of parallelism ==>
* Now we only start 3 mappers start at the same time, the fourth must be wait for a free slot
* The three first mappers distribute spread the ram among themselves, and as a result they will have enough ram to finish the task
During a normal “Build Cube” step you will see similars messages on YARN log:

If you don’t see this periodically, perhaps you have a bottleneck in the memory.
Cube 7: Improve cube response time
We can try to use different aggregations groups to improve the query performance of some very important Dim or a Dim with high cardinality.
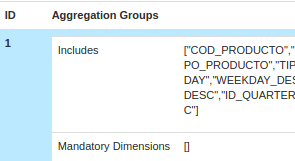
In our case we define 3 Aggregations Groups:
1. “Normal cube”
2. Cube with Date Dim and Currency (as mandatory)
3. Cube with Date Dim and Carteras_Desc (as mandatory)
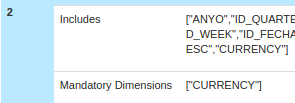
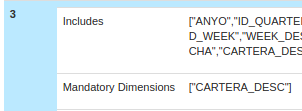
Compare without / with AGGs:
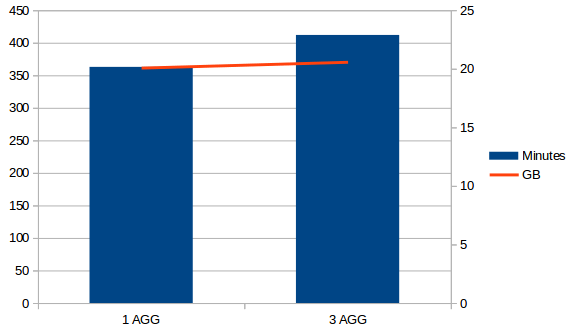
Now it uses 3% more of time to build the cube and 0.6% of space, but queries by currency or Carteras_Desc will be much faster.