
Here are some basic technical concepts used in Apache Kylin, please check them for your reference.
For terminology in domain, please refer to: Terminology
CUBE
-
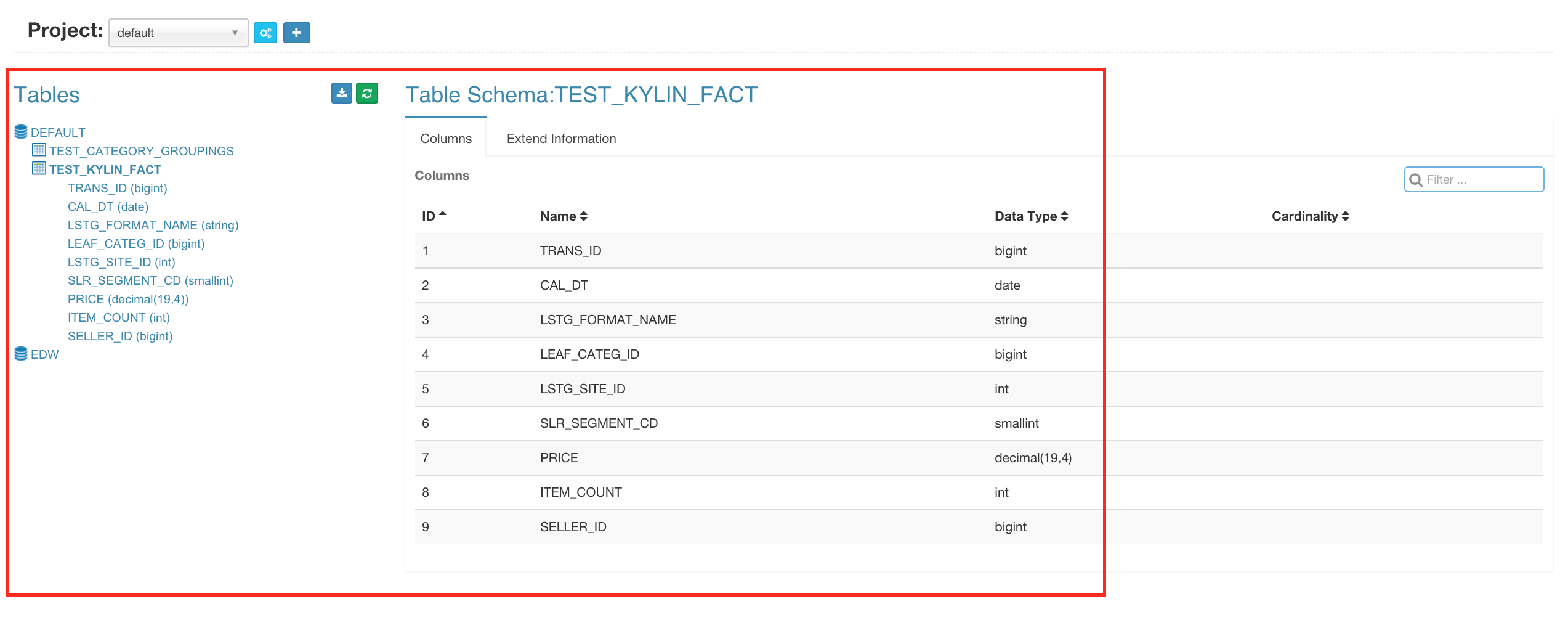
Table - This is the definition of hive tables as source of cubes, which must be synced before building cubes.
-
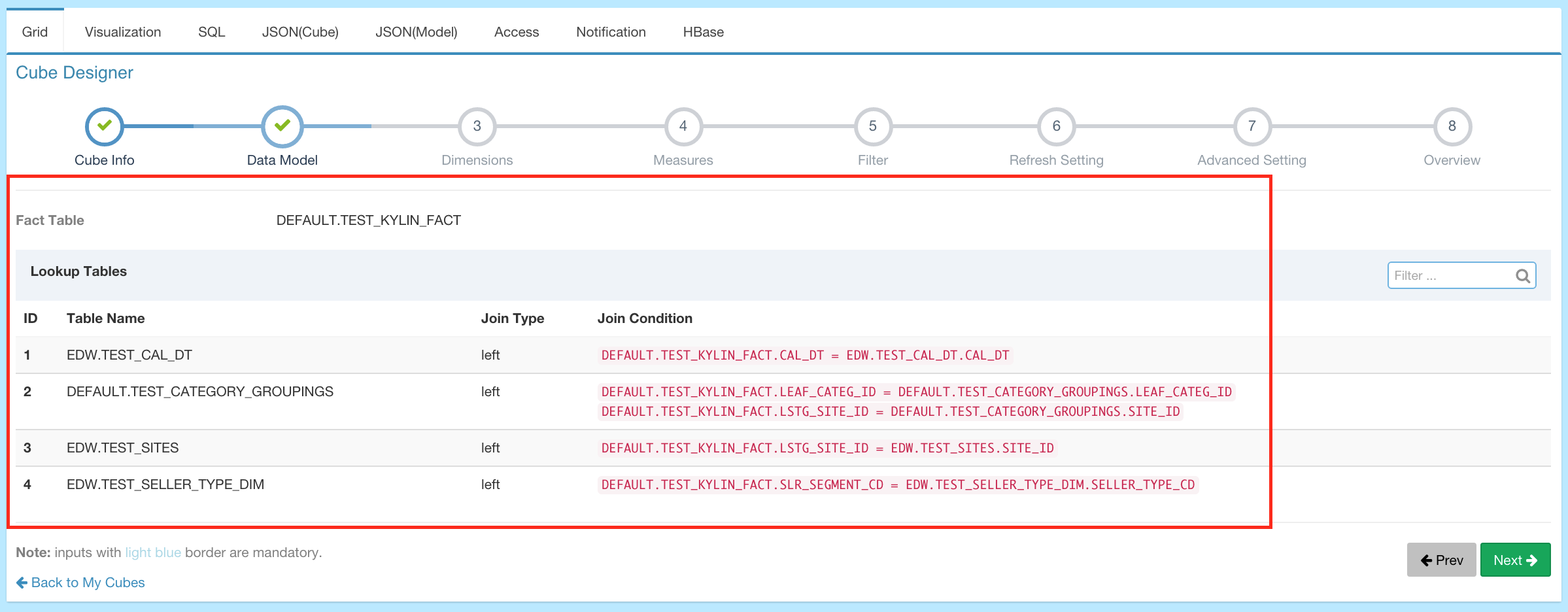
Data Model - This describes a STAR SCHEMA data model, which defines fact/lookup tables and filter conditions.
-
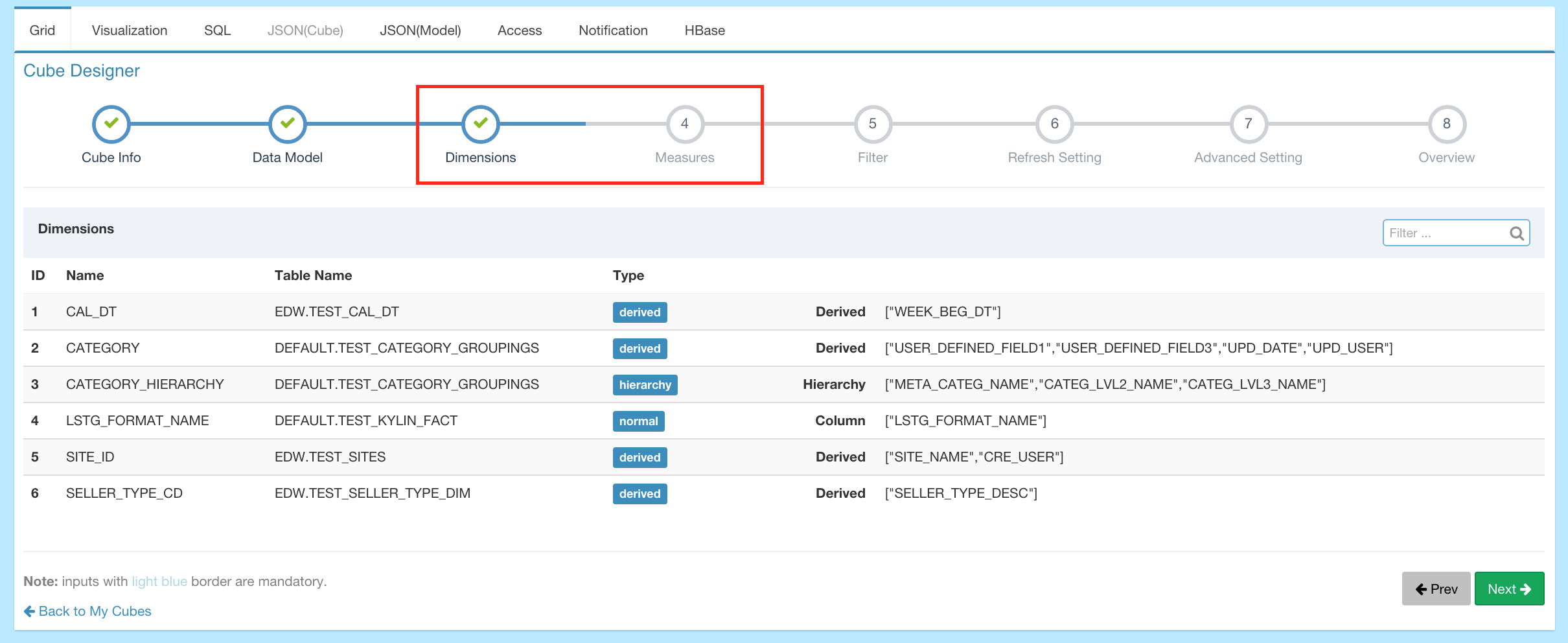
Cube Descriptor - This describes the definition and settings for a cube instance, defining which data model to use, what dimensions and measures to have, how to partition into segments and how to handle auto-merge, etc.
-
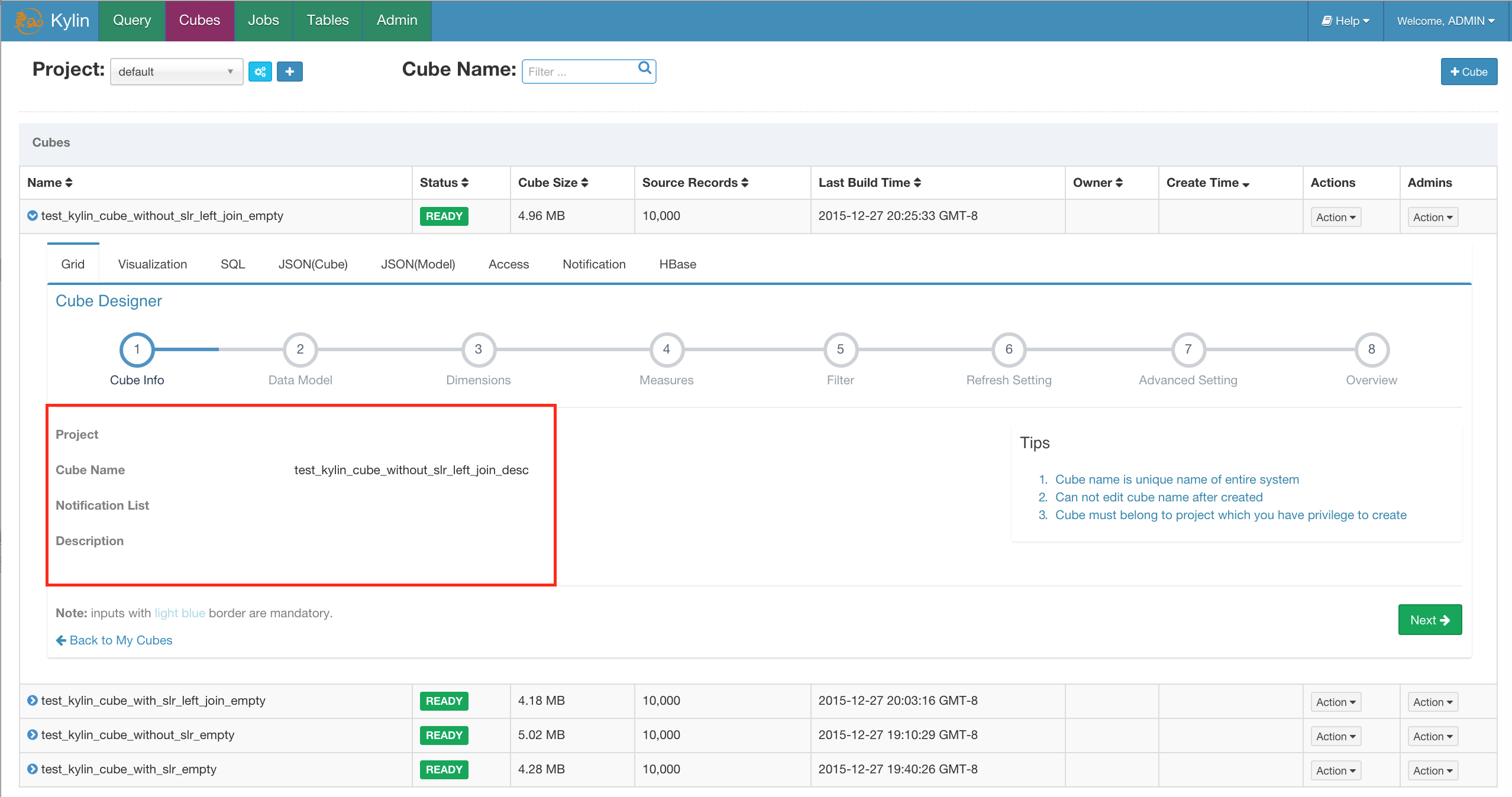
Cube Instance - This is the instance of cube built from one cube descriptor, and consists of one or more cube segments according to partition settings.
-
Partition - User can define a DATE/STRING column as partition column on the cube descriptor to separate one cube into several segments with different date periods.
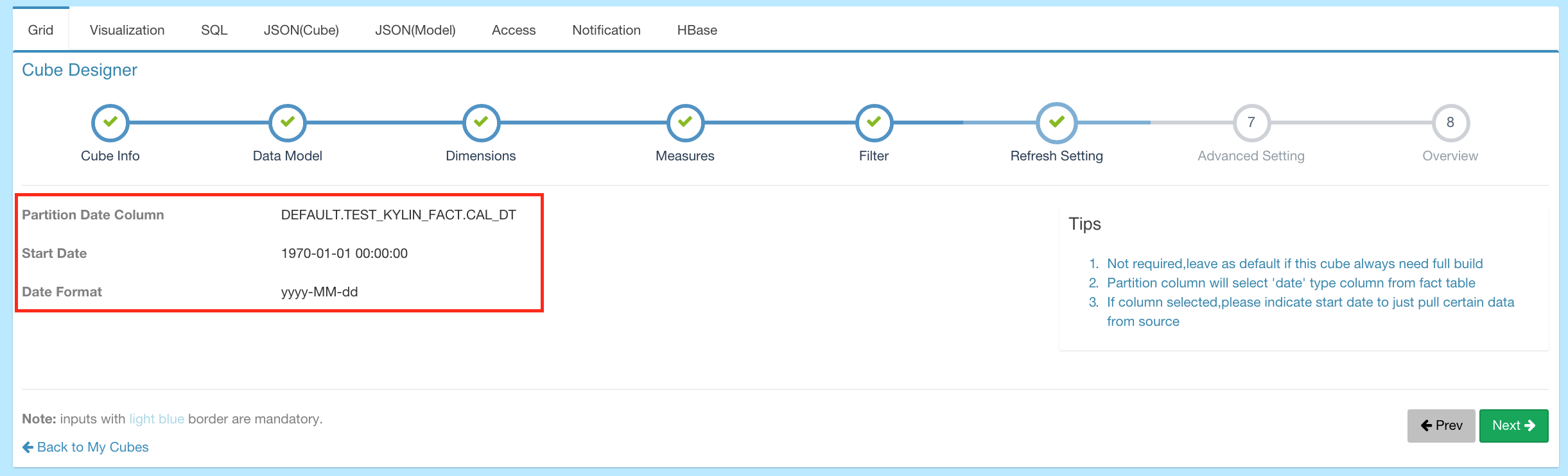
-
Cube Segment - This is the actual carrier of cube data, and it maps to an HTable in HBase. One building job creates one new segment for the cube instance. Once data changes on specified date period, we can refresh related segments to avoid rebuilding the whole cube.
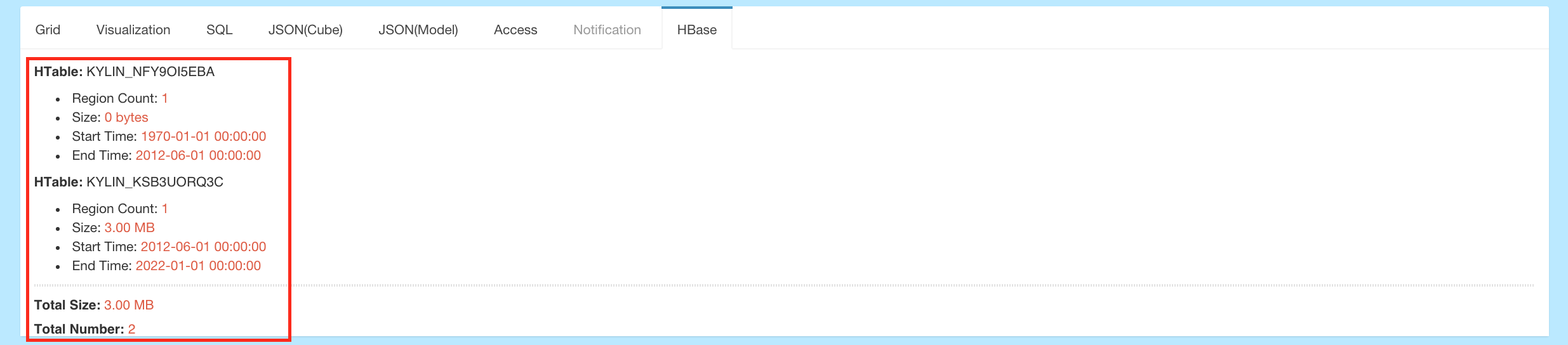
-
Aggregation Group - Each aggregation group is a subset of dimensions, and cuboid are built with combinations inside. It aims at pruning for optimization.
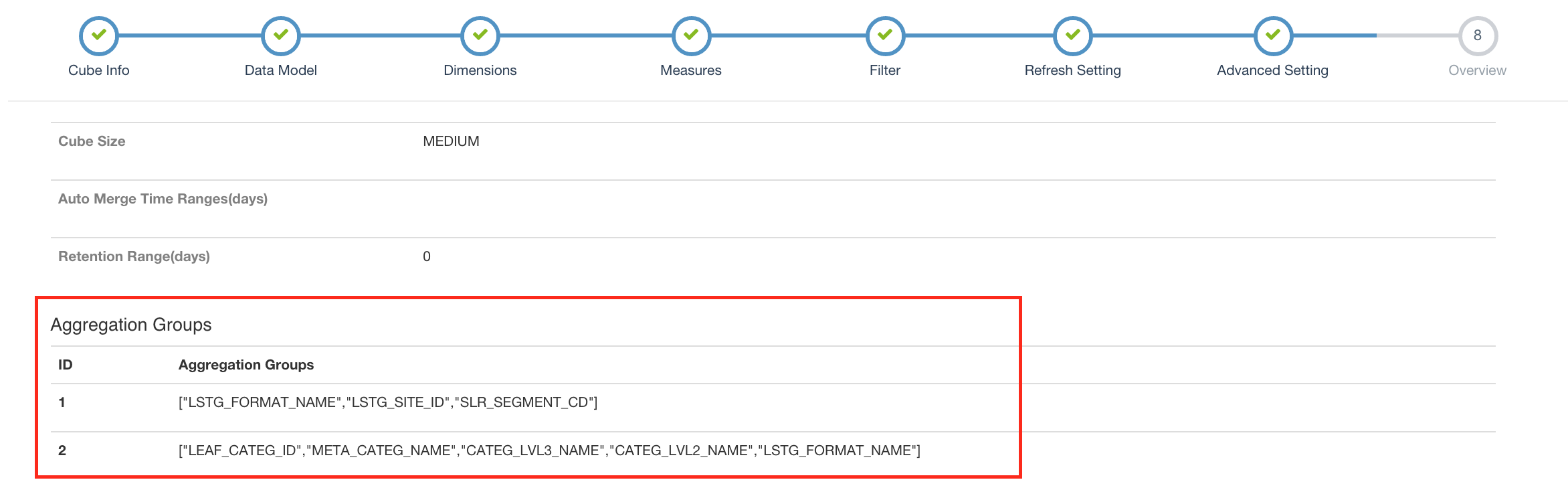
DIMENSION & MEASURE
- Mandatory - This dimension type is used for cuboid pruning, if a dimension is specified as “mandatory”, then those combinations without such dimension are pruned.
- Hierarchy - This dimension type is used for cuboid pruning, if dimensions A,B,C form a “hierarchy” relation, then only combinations with A, AB or ABC shall be remained.
-
Derived - In lookup tables, some dimensions could be generated from their PK, so there are specific mappings between them and the FK from the fact table. So those dimensions are DERIVED, and they don’t participate in cuboid generation.
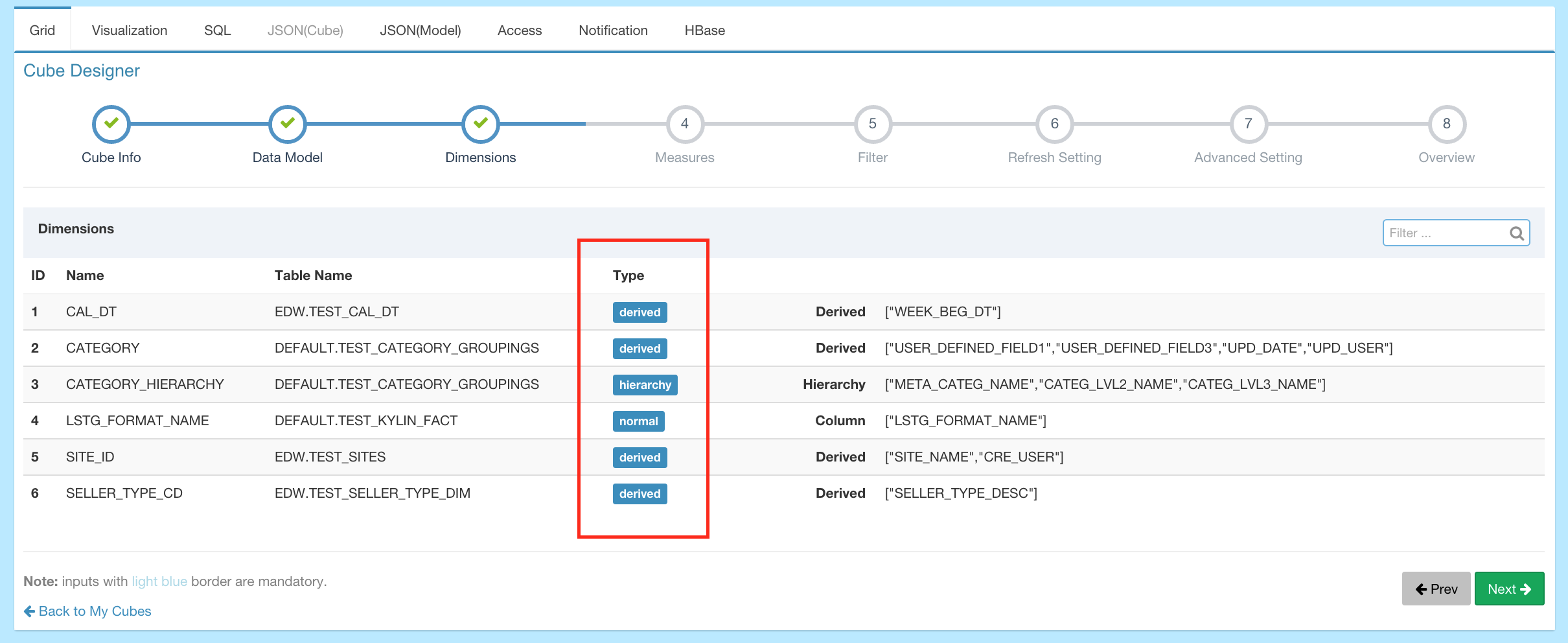
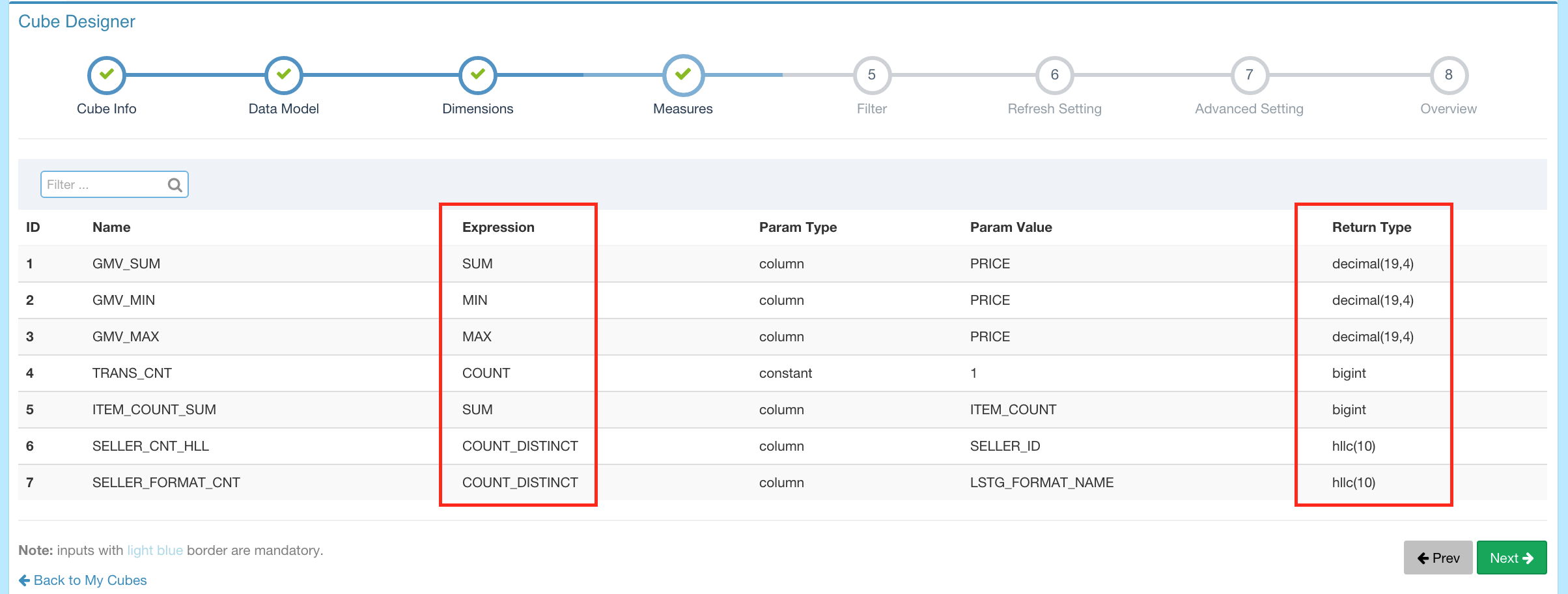
- Count Distinct(HyperLogLog) - Immediate COUNT DISTINCT is hard to calculate, an approximate algorithm - HyperLogLog is introduced, and it keeps the error rate in a low level.
- Count Distinct(Precise) - Precise COUNT DISTINCT will be pre-calculated based on RoaringBitmap. Currently, only int and bigint are supported.
- Top N - For example, with this measure type, user can easily get specified numbers of top sellers/buyers, etc.
CUBE ACTIONS
- BUILD - Given an interval of partition column, this action is to build a new cube segment.
- REFRESH - This action will rebuild the cube segment in some partition periods, which is used in case of source table increasing.
- MERGE - This action will merge multiple continuous cube segments into a single one. This can be automated with the auto-merge setting in cube descriptor.
- PURGE - Clear segments under a cube instance. This will only update the metadata, and won’t delete the cube data from HBase.

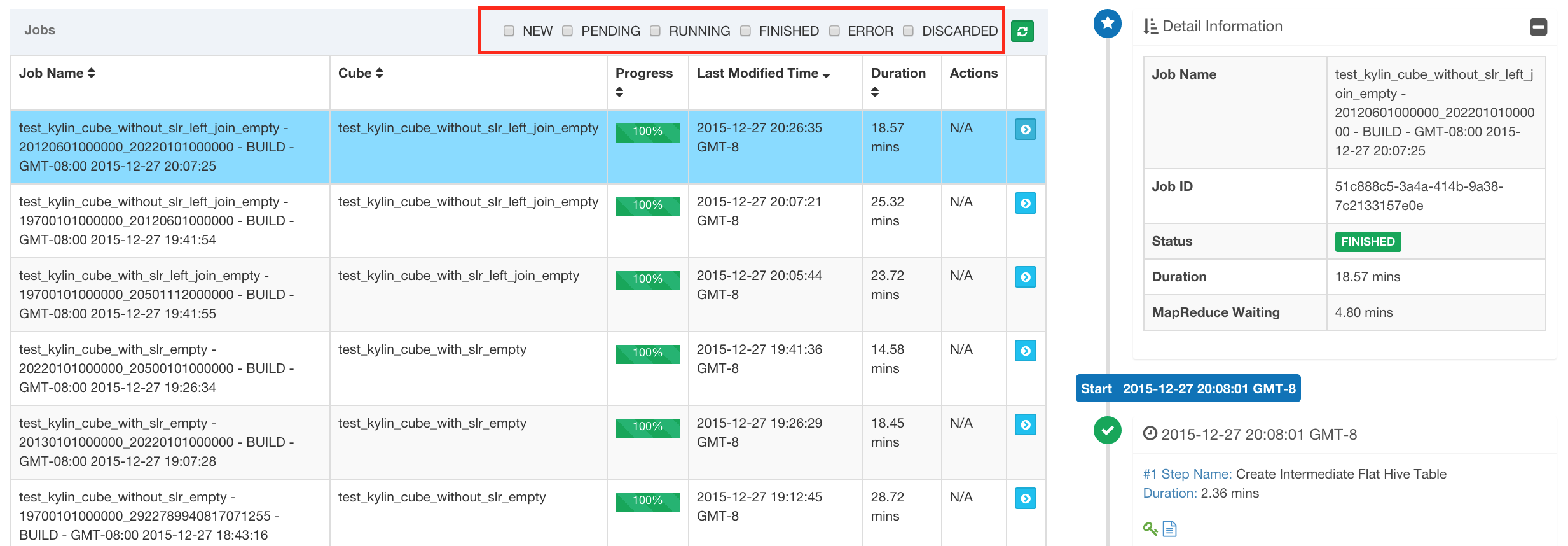
JOB STATUS
- NEW - This denotes that one job has been just created.
- PENDING - This denotes that one job is paused by job scheduler and is waiting for resources.
- RUNNING - This denotes that one job is running in progress.
- FINISHED - This denotes that one job is finished successfully.
- ERROR - This denotes that one job is aborted with errors.
- DISCARDED - This denotes that one job is cancelled by end users.
JOB ACTION
- RESUME - Once a job is in ERROR status, this action will try to restore it from the latest successful point.
- DISCARD - No matter what the status of a job is, users can end it and release resources with the DISCARD action.
