
Real-time Streaming Design in Apache Kylin
Why Build Real-time Streaming in Kylin
The real-time streaming feature is contributed by eBay big data team in Kylin 3.0, the purpose we build real-time streaming is:
-
Milliseconds Data Preparation Delay
Kylin provide sub-second query latency for extremely large dataset, the underly magic is precalculation cube. But the cube building often take long time(usually hours for large data sets), in some case, the analyst needs real-time data to do analysis, so we want to provide real-time OLAP, which means data can be queried immediately when produced to system. -
Support Lambda Architecture
Real-time data often not reliable, that may caused by many reasons, for example, the upstream processing system has a bug, or the data need to be changed after some time, etc. So we need to support lambda architecture, which means the cube can be built from the streaming source(like Kafka), and the historical cube data can be refreshed from batch source(like Hive). -
Less MR jobs and HBase Tables
Since Kylin 1.6, community has provided a streaming solution, it uses MR to consume Kafka data and then do batch cube building, it can provide minute-level data preparation latency, but to ensure the data latency, you need to schedule the MR very shortly(5 minutes or even less), that will cause too many hadoop jobs and small hbase tables in the system, and dramatically increase the Hadoop system’s load.
Architecture
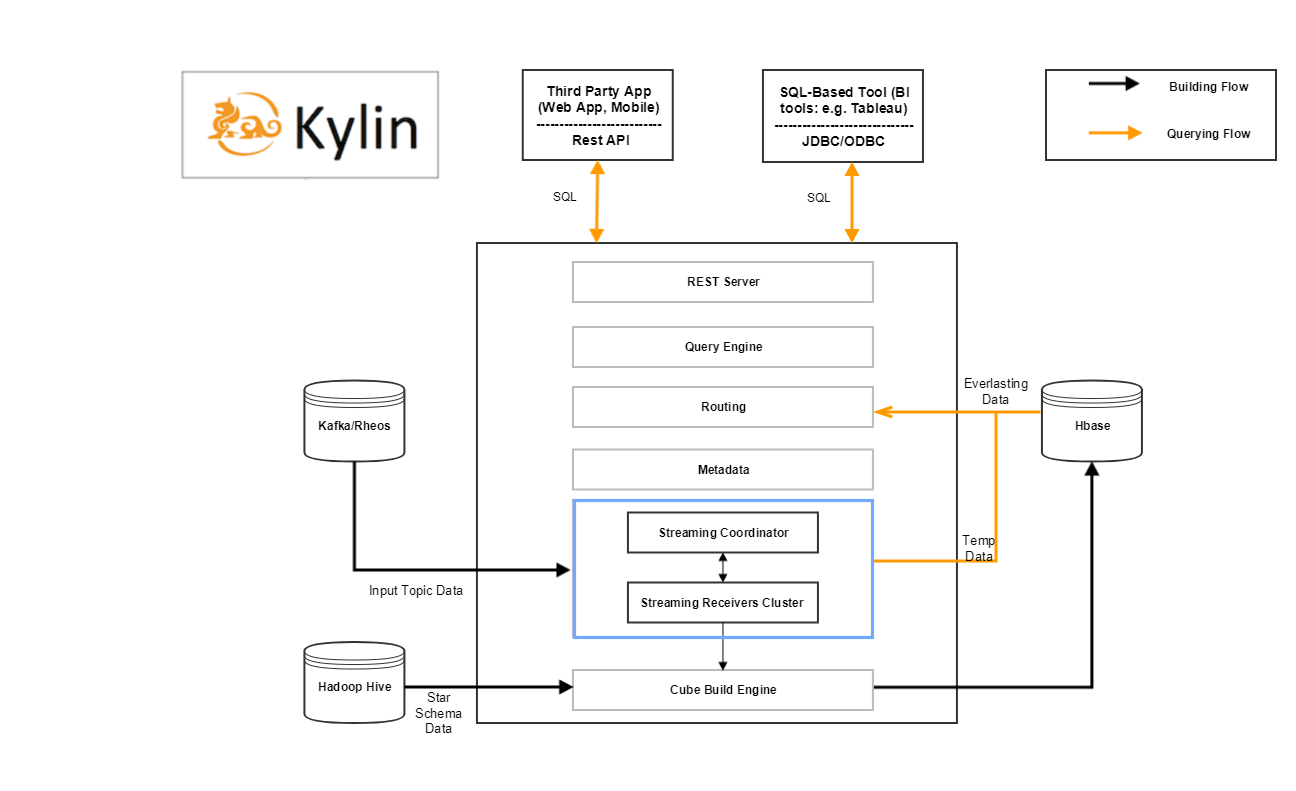
The blue rectangle is streaming components added in current Kylin’s architecture, which is responsible to ingest data from streaming source, and provide query for real-time data.
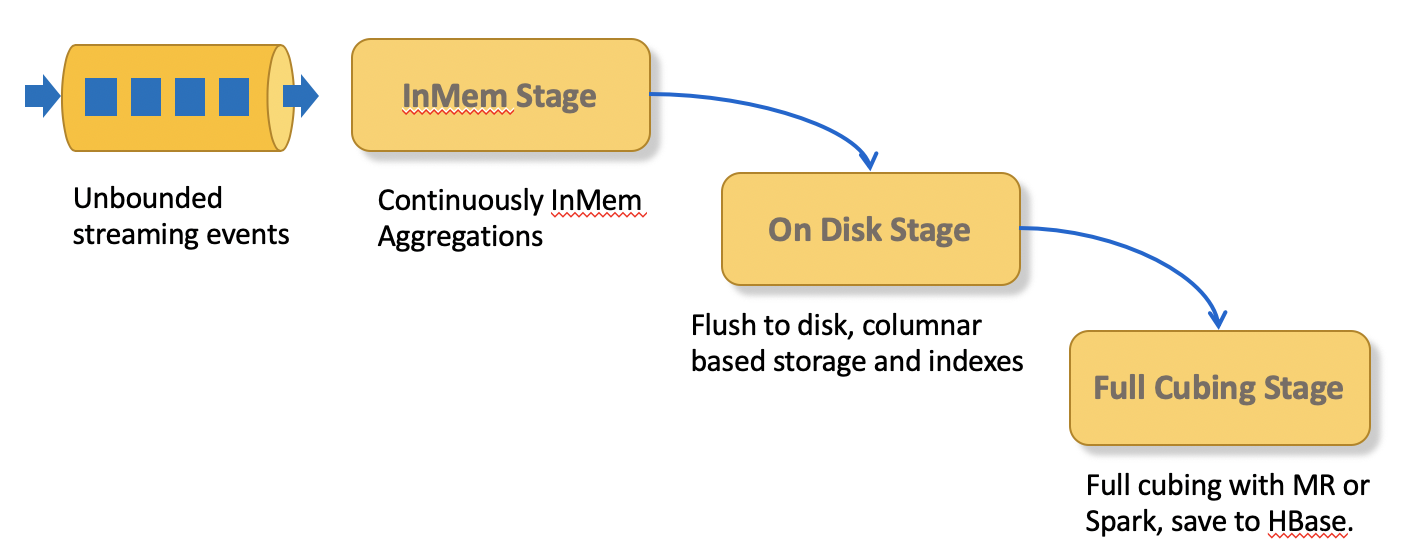
We divide the unbounded incoming streaming data into 3 stages, the data come into different stages are all queryable immediately.
Components
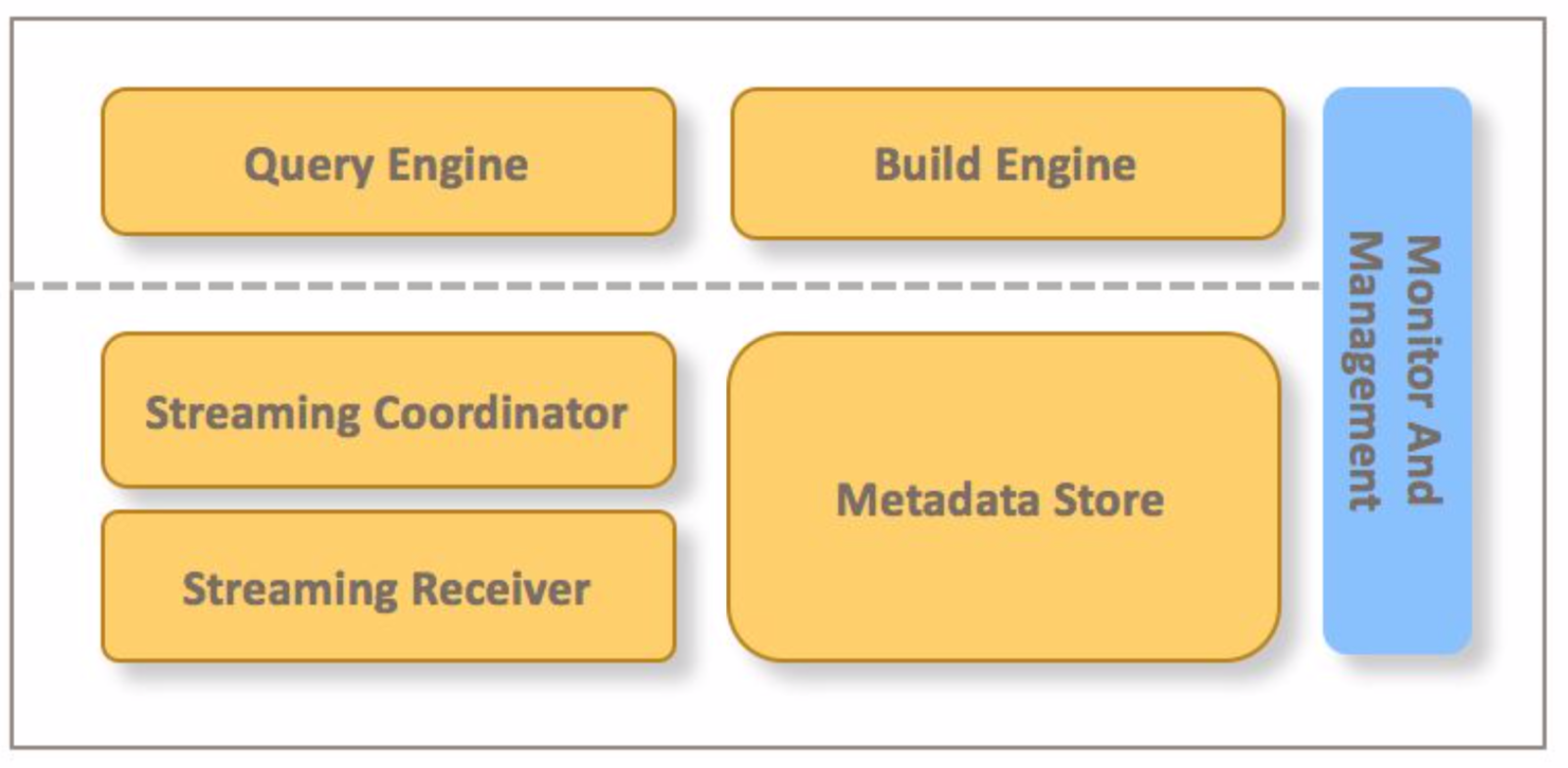
Streaming Receiver: Responsible to ingest data from stream data source, and provide real-time data query.
Streaming Coordinator: Responsible to do coordination works, for example, when new streaming cube is onboard, the coordinator need to decide which streaming receivers can be assigned.
Metadata Store: Used to store streaming related metadata, for example, the cube assignments information, cube build state information.
Query Engine: Extend the existing query engine, support to query real-time data from streaming receiver
Build Engine: Extend the existing build engine, support to build full cube from the real-time data
How Streaming Cube Engine Works
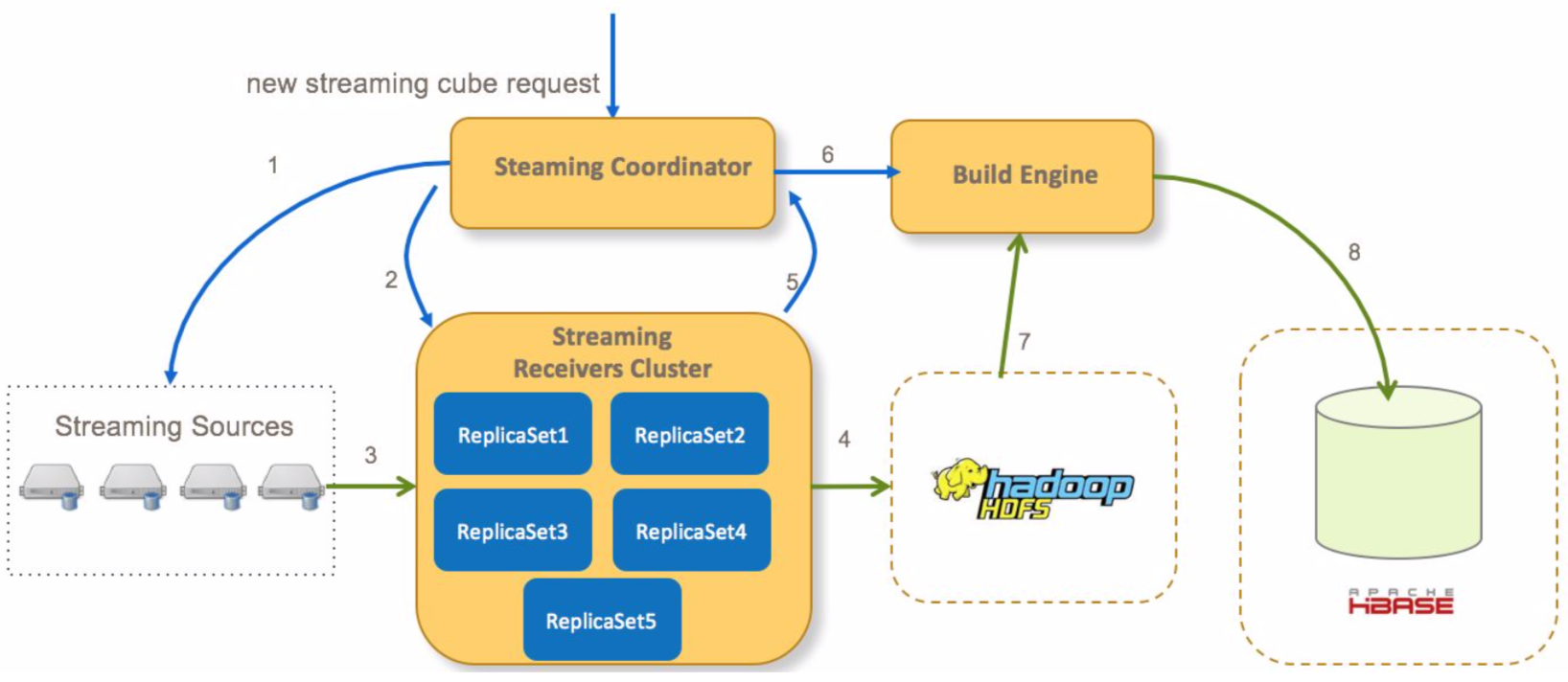
- Coordinator ask streaming source for all partitions of the cube
- Coordinator decide which streaming receivers to assign to consume streaming data, and ask streaming receivers to start consuming data.
- Streaming receiver start to consume and index streaming events
- After sometime, streaming receiver copy the immutable segments from local files to remote HDFS files
- Streaming receiver notify the coordinator that a segment has been persisted to HDFS
- Coordinator submit a cube build job to Build Engine to triger cube full building after all receivers have submitted their segments
- Build Engine build all cuboids from the streaming HDFS files
- Build Engine store cuboid data to Hbase, and then the coordinator will ask the streaming receivers to remove the related local real-time data.
How Streaming Query Engine Works
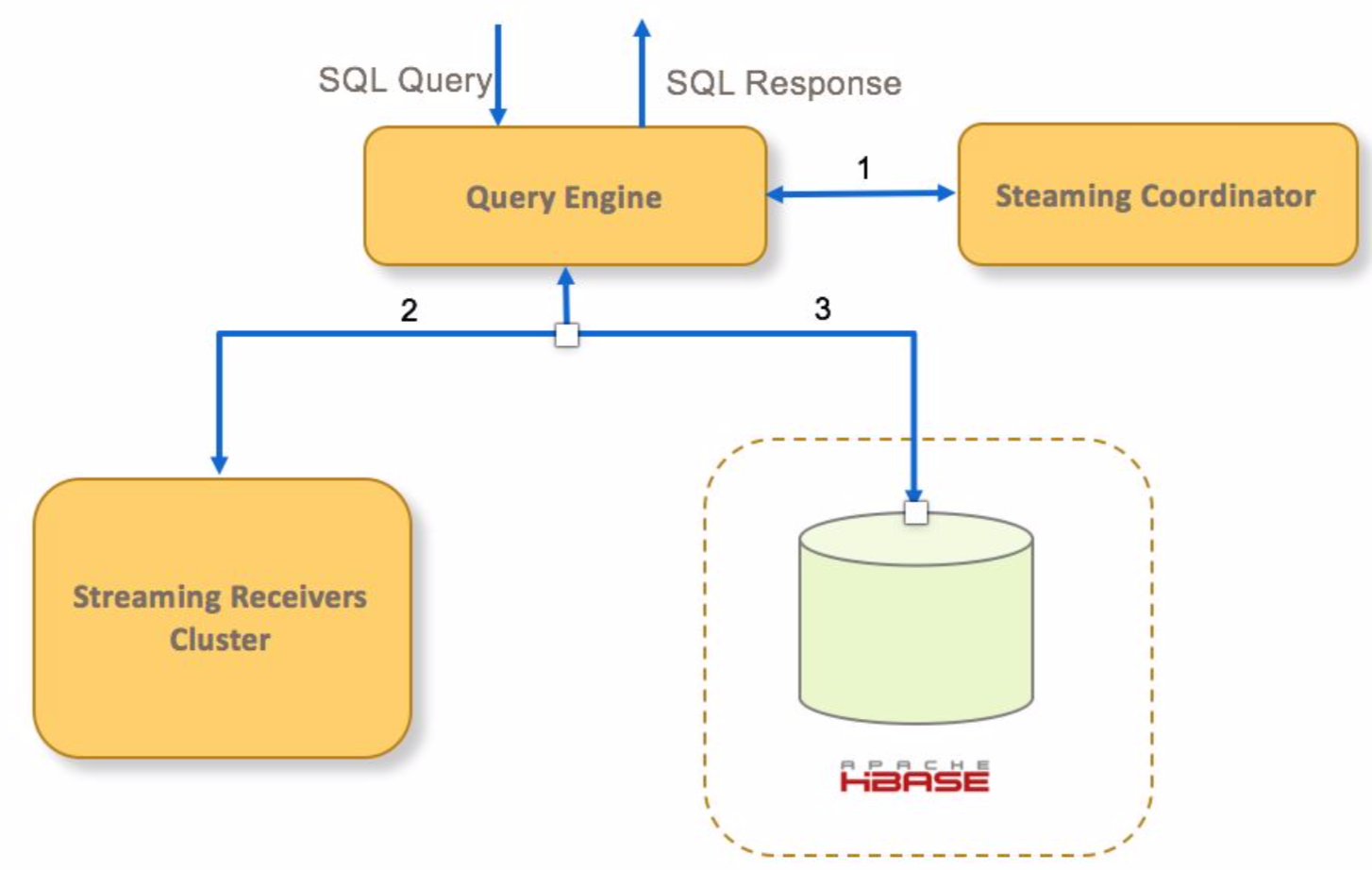
- If Query hits a streaming cube, Query Engine ask Streaming Coordinator what streaming receivers are assigned for the cube
- Query Engine send query request to related streaming receivers to query realtime segments
- Query Engine send query request to Hbase to query historical segments
- Query Engine aggregate the query results, and send response back to client
Detail Design
Real-time Segment Store
Real-time segments are divided by event time, when new event comes, it will be calculated which segment it will be located, if the segment doesn’t exist, create a new one.
The new created segment is in ‘Active’ state first, if no further events coming into the segment after some preconfigured period, the segment state will be changed to ‘Immutable’, and then write to remote HDFS.
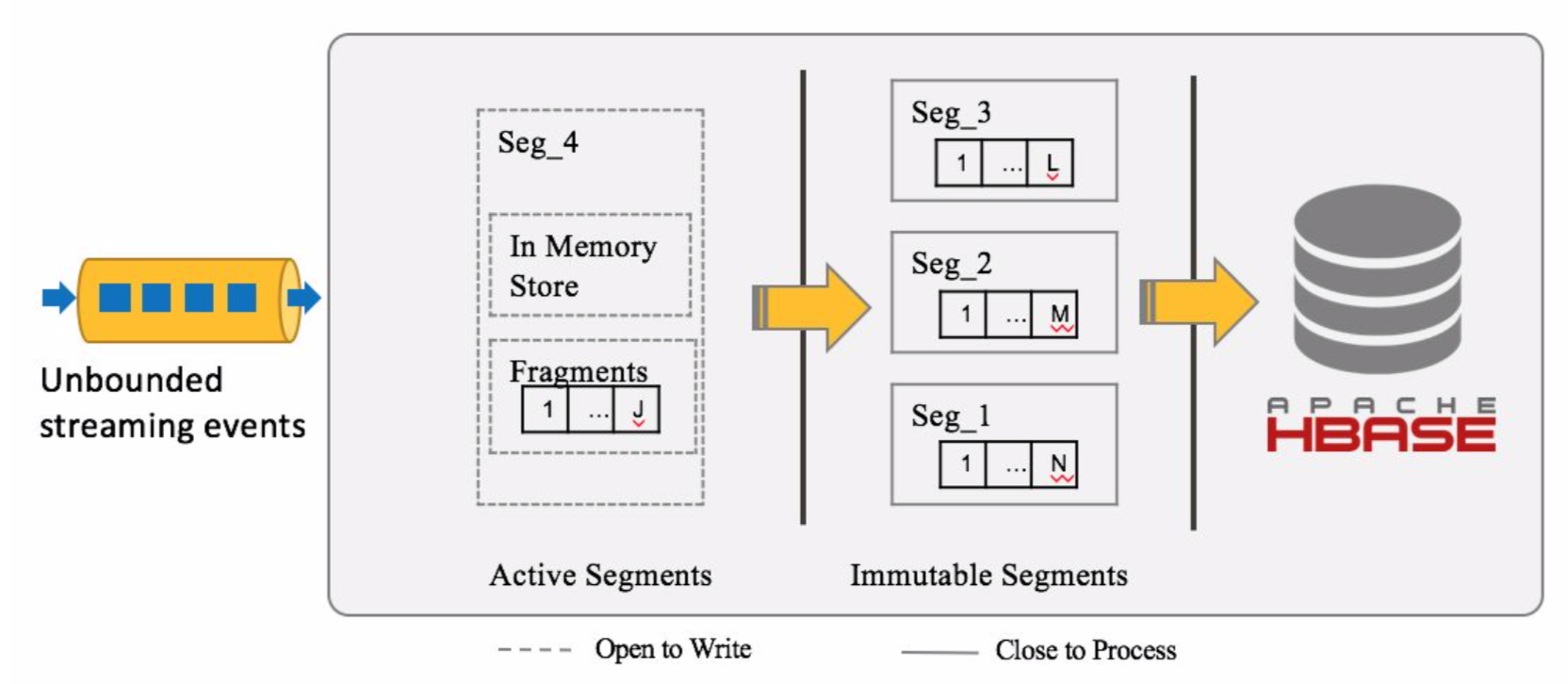
Each real-time segment has a memory store, new event will first goes into the memory store to do aggregation, when the memory store size reaches the configured threshold, it will be then be flushed to local disk as a fragment file.
Not all cuboids are built in the receiver side, only basic cuboid and some specified cuboids are built.
The data is stored as columnar format on disk, and when there are too many fragments on disk, the fragment files will be merged by a background thread automatically.
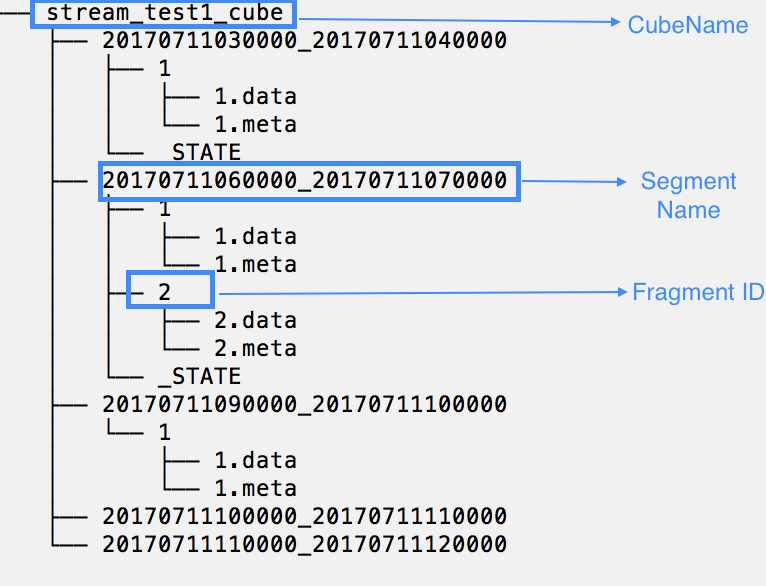
The directory structure in receiver side is like:
To improve the query performance, the data is stored in columnar format, the data format is like:
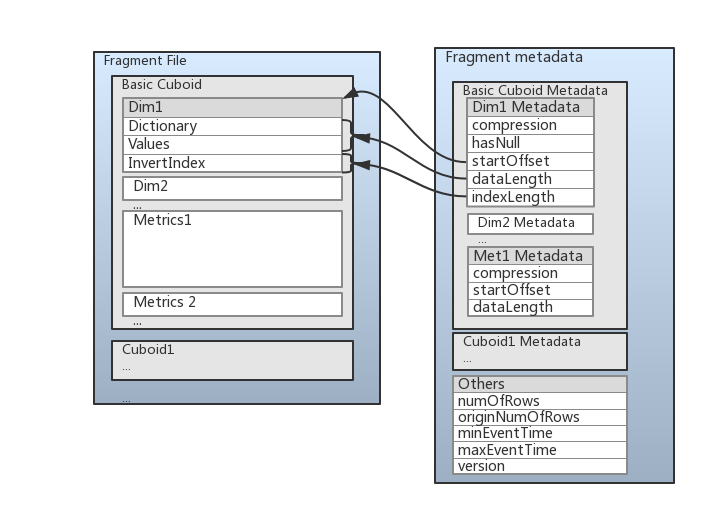
Each cuboid data is stored together, and in each cuboid the data is stored column by column, the metadata is stored in json format.
The dimension data is divided into 3 parts:
The first part is Dictionary part, this part exists when the dimension encoding is set to ‘Dict’ in cube design, by default we use tri-tree dictionary to minimize the memory footprints and preserve the original order.
The second part is dictionary encoded values, additional compression mechanism can be applied to these values, since the values for the same column are usually similar, so the compression rate will be very good.
The third part is invert-index data, use Roaring Bitmap to store the invert-index info, the following picture shows how invert-index data is stored, there are two types of format, the first one is dictionary encoding dimension’s index data format, the second is other fix-len encoding dimension’s index data format.

Real-time data is stored in compressed format, currently support two type compression: Run Length Encoding and LZ4.
- Use RLE compression for time-related dim and first dim
- Use LZ4 for other dimensions by default
- Use LZ4 Compression for simple-type measure(long, double)
- No compression for complex measure(count distinct, topn, etc.)
High Availability
Streaming receivers are group into replica-sets, all receivers in the same replica-set share the same assignments, so that when one receiver is down, the query and event consuming will not be impacted.
In each replica-set, there is a lead responsible to upload real-time segments to HDFS, and zookeeper is used to do leader election
Failure Recovery
We do checkpoint periodically in receiver side, so that when the receiver is restarted, the data can be restored correctly.
There are two parts in the checkpoint: the first part is the streaming source consume info, for Kafka it is {partition:offset} pairs, the second part is disk states {segment:framentID} pairs, which means when do the checkpoint what’s the max fragmentID for each segment.
When receiver is restarted, it will check the latest checkpoint, set the Kafka consumer to start to consume data from specified partition offsets, and remove the fragment files that the fragmentID is larger than the checkpointed fragmentID on the disk.
Besides the local checkpoint, we also have remote checkpoint, to restore the state when the disk is crashed, the remote checkpoint is saved to Cube Segment metadata after HBase segment build, like:
”segments”:[{…,
"stream_source_checkpoint": {"0":8946898241, “1”: 8193859535, ...}
},
]
The checkpoint info is the smallest partition offsets on the streaming receiver when real-time segment is sent to full build.
Future
- Star Schema Support
- Streaming Receiver On Kubernetes/Yarn