
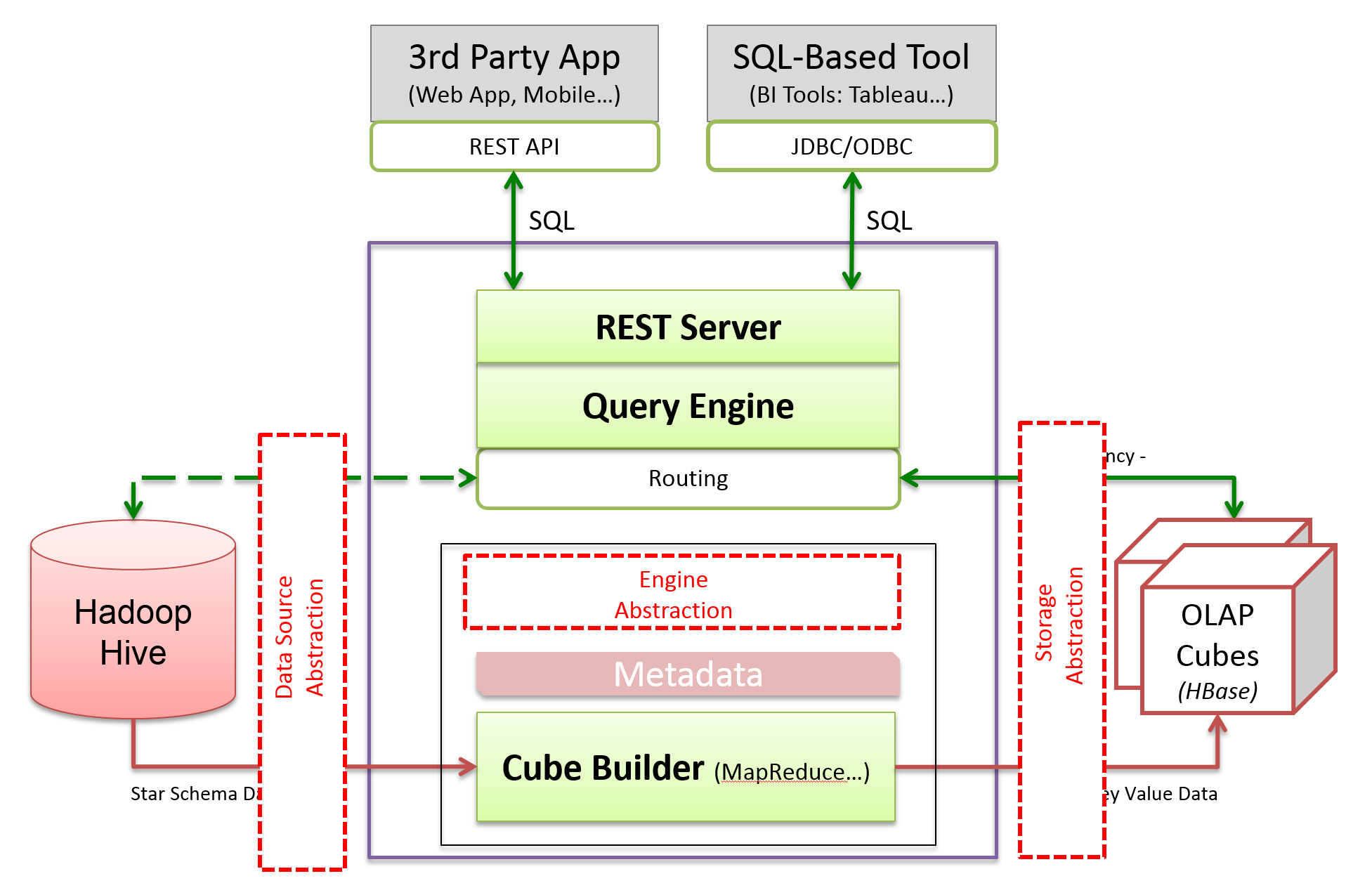
The plugin architecture aims to make Kylin extensible regarding computation framework, data source, and cube storage. As of v1, Kylin tightly couples with Hadoop MapReduce as computation framework, Hive as data source, and HBase as storage. Questions came like: could Kylin use Spark as cube engine, or how about a different storage like Cassandra. We want to be open to different options, and to make sure Kylin evolve with the best tech stacks. That is why the plugin architecture is introduced in Kylin v2.
How it Works
The cube metadata defines the type of engine, source, and storage that a cube depends on. Factory pattern is used to construct instances of each dependency. Adaptor pattern is used to connect the parts together.
For example a cube descriptor may contains:
- fact_table:
SOME_HIVE_TABLE - engine_type:
2(MR Engine v2) - storage_type:
2(HBase Storage v2)
Based on the metadata, factories creates MR engine, Hive data source, and HBase storage.
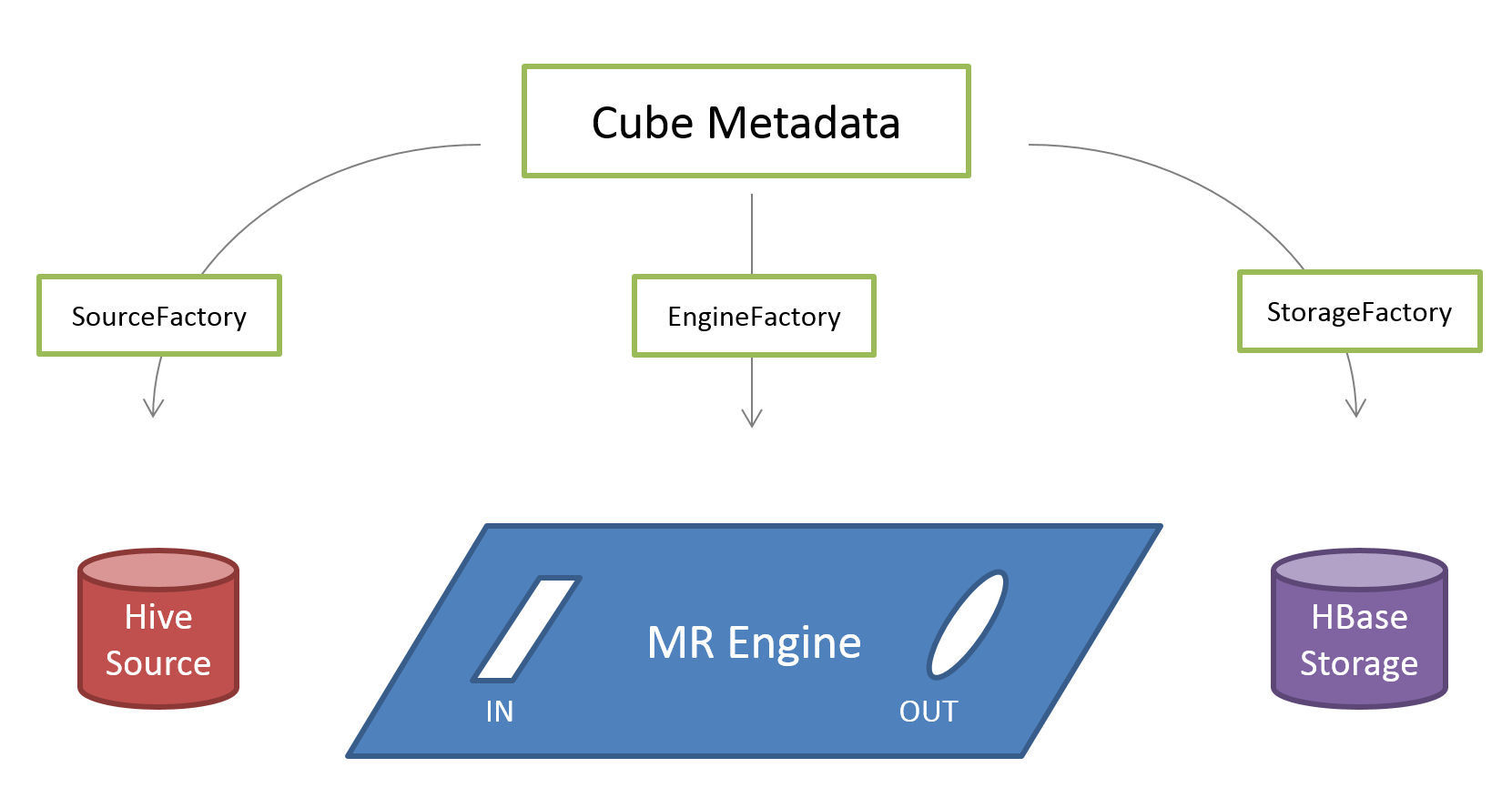
The engine is like a motherboard, on which source and storage must be plugged as defined by the IN and OUT interfaces. Data source and storage must adapt to the interfaces in order to be connected to engine motherboard.
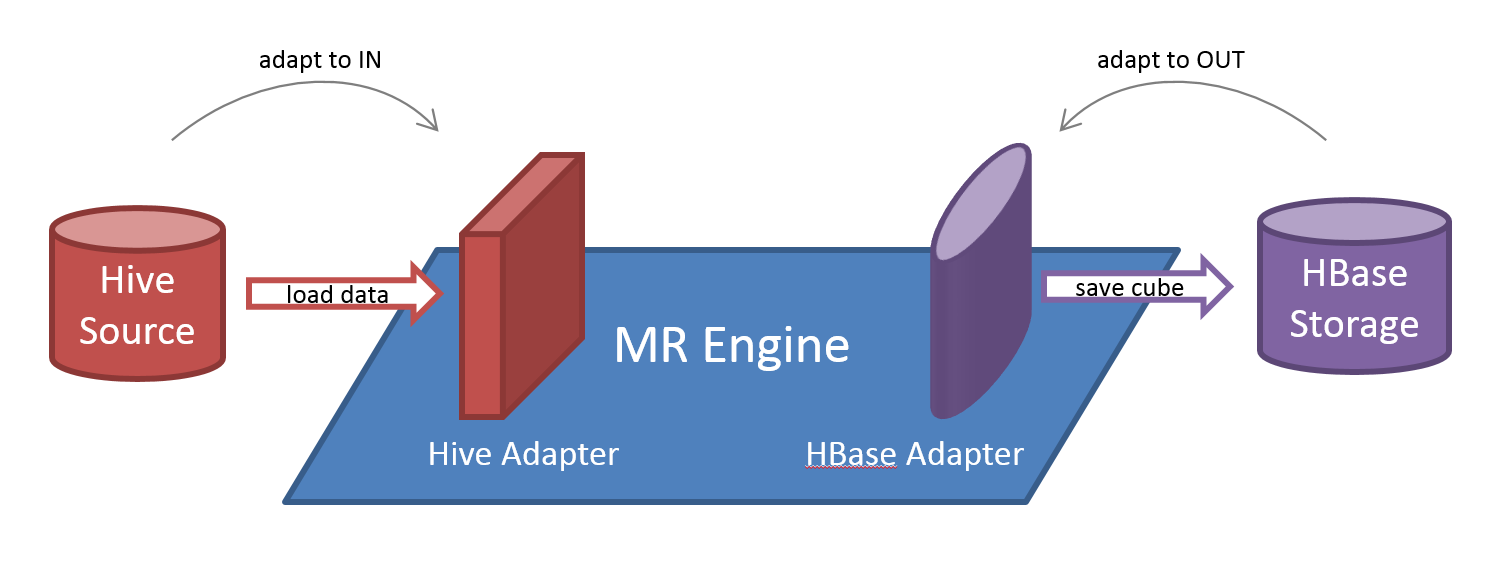
Once the above object graph is created and connected, engine can drive the cube build process.
The Benefits of Plugin Architecture
- Freedom
- Zoo break, not bound to Hadoop any more
- Free to go to a better engine or storage
- Extensibility
- Accept any input, e.g. Kafka
- Embrace next-gen distributed platform, e.g. Spark
- Flexibility
- Choose different engine for different data set