
This tutorial will guide you to create a cube. It need you have at least 1 sample table in Hive. If you don’t have, you can follow this to create some data.
I. Create a Project
-
Go to
Querypage in top menu bar, then clickManage Projects.
-
Click the
+ Projectbutton to add a new project.
-
Enter a project name, e.g, “Tutorial”, with a description (optional), then click
submitbutton to send the request.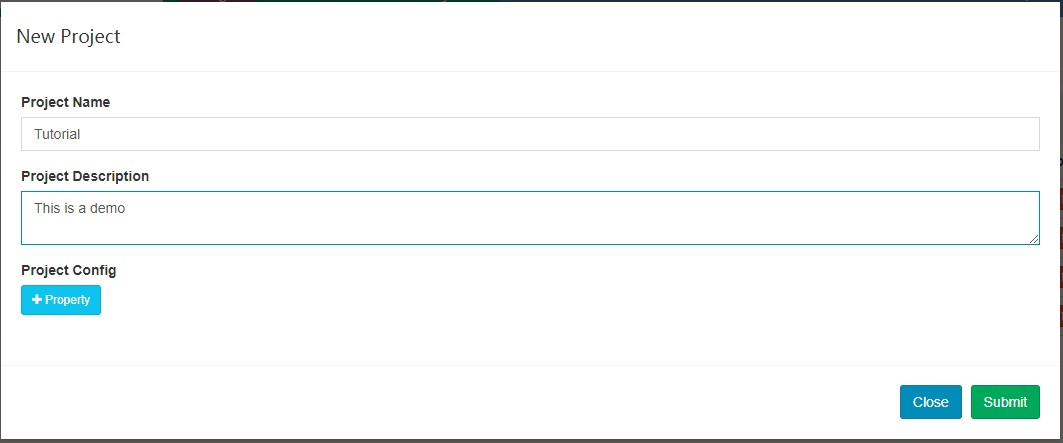
-
After success, the project will show in the table.

II. Sync up Hive Table
-
Click
Modelin top bar and then clickData Sourcetab in the left part, it lists all the tables loaded into Kylin; clickLoad Hive Tablebutton.
-
Enter the hive table names, separated with commad, and then click
Syncto send the request.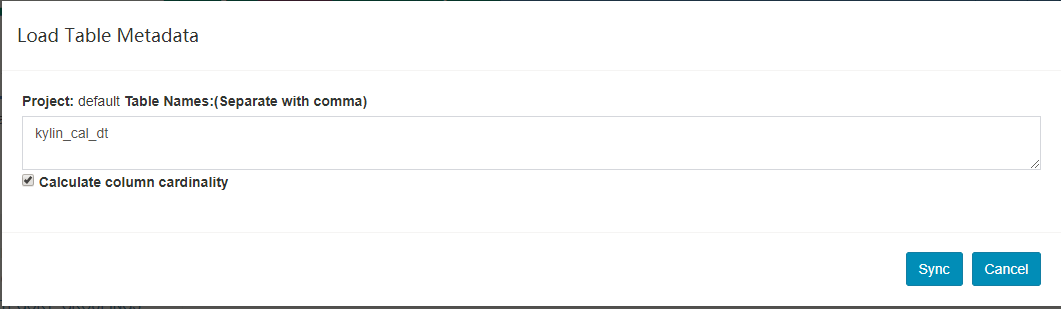
-
[Optional] If you want to browser the hive database to pick tables, click the
Load Hive Table From Treebutton.
-
[Optional] Expand the database node, click to select the table to load, and then click
Sync.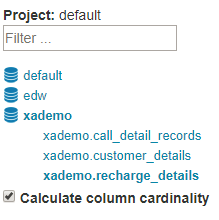
-
A success message will pop up. In the left
Tablessection, the newly loaded table is added. Click the table name will expand the columns.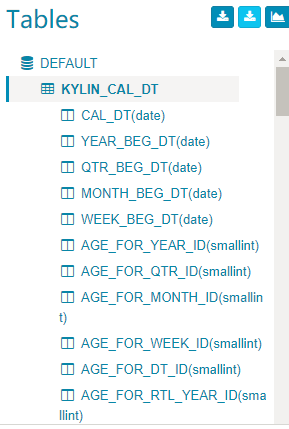
-
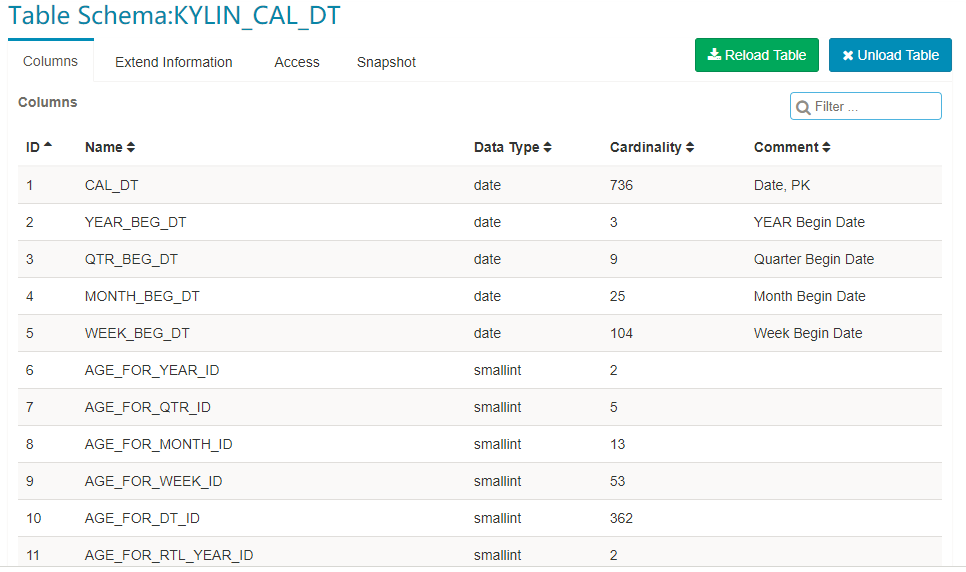
In the background, Kylin will run a MapReduce job to calculate the approximate cardinality for the newly synced table. After the job be finished, refresh web page and then click the table name, the cardinality will be shown in the table info.
III. Create Data Model
Before create a cube, need define a data model. The data model defines the star schema. One data model can be reused in multiple cubes.
-
Click
Modelin top bar, and then clickModelstab. Click+Newbutton, in the drop-down list selectNew Model.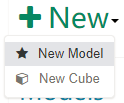
-
Enter a name for the model, with an optional description.
-
In the
Fact Tablebox, select the fact table of this data model.
-
[Optional] Click
Add Lookup Tablebutton to add a lookup table. Select the table name and join type (inner or left).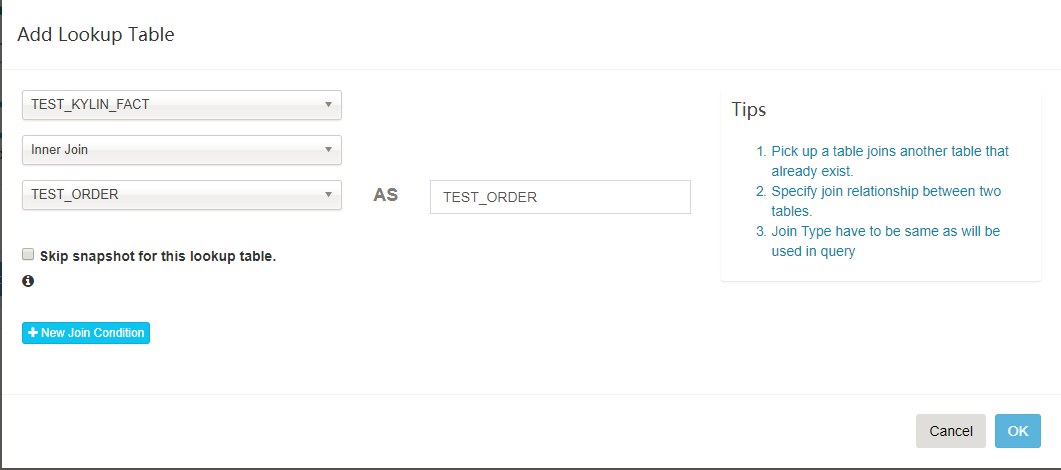
-
[Optional] Click
New Join Conditionbutton, select the FK column of fact table in the left, and select the PK column of lookup table in the right side. Repeat this if have more than one join columns.
-
Click “OK”, repeat step 4 and 5 to add more lookup tables if any. After finished, click “Next”.
-
The “Dimensions” page allows to select the columns that will be used as dimension in the child cubes. Click the
Columnscell of a table, in the drop-down list select the column to the list.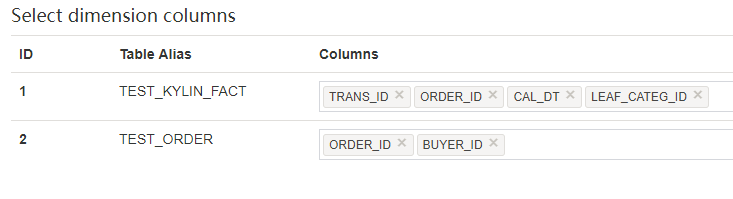
-
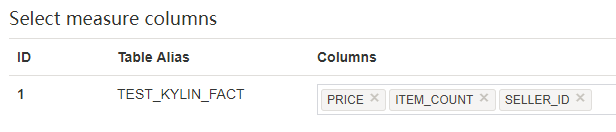
Click “Next” go to the “Measures” page, select the columns that will be used in measure/metrics. The measure column can only from fact table.
-
Click “Next” to the “Settings” page. If the data in fact table increases by day, select the corresponding date column in the
Partition Date Column, and select the date format, otherwise leave it as blank. -
[Optional] Select
Cube Size, which is an indicator on the scale of the cube, by default it isMEDIUM. -
[Optional] If some records want to excluded from the cube, like dirty data, you can input the condition in
Filter.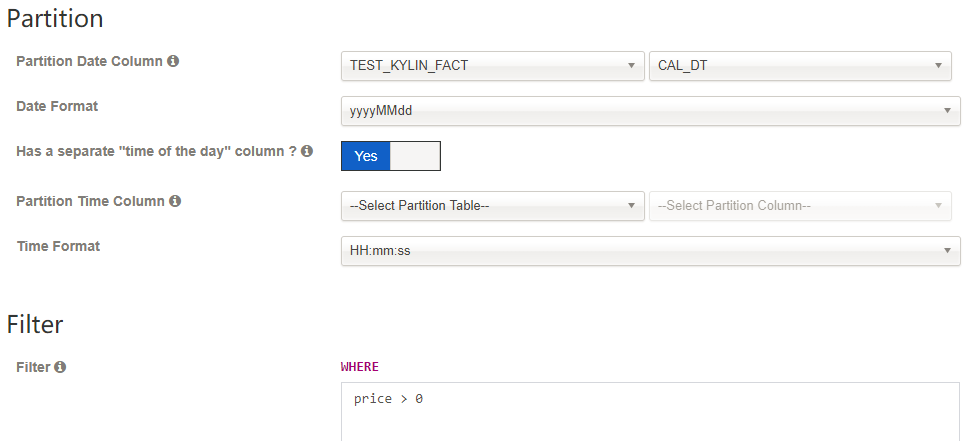
-
Click
Saveand then selectYesto save the data model. After created, the data model will be shown in the leftModelslist.
IV. Create Cube
After the data model be created, you can start to create cube.
Click Model in top bar, and then click Models tab. Click +New button, in the drop-down list select New Cube.
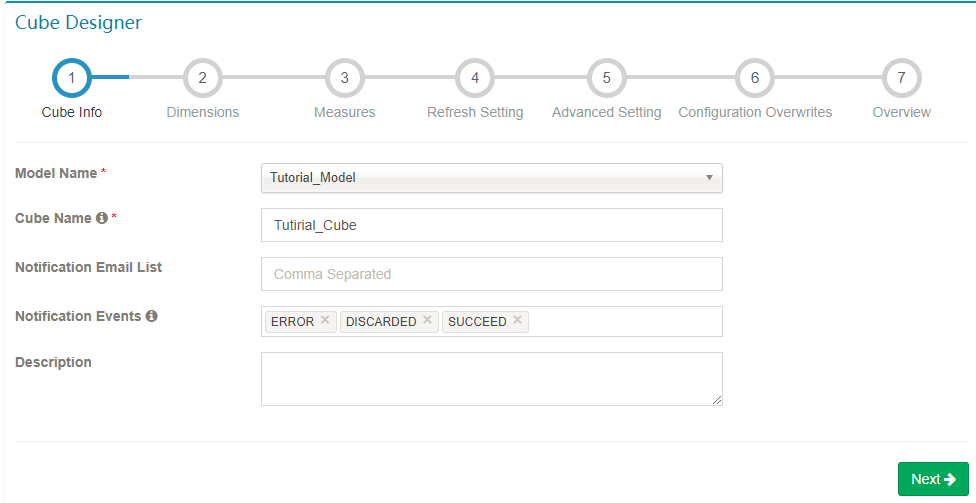
Step 1. Cube Info
Select the data model, enter the cube name; Click Next to enter the next step.
You can use letters, numbers and ‘_’ to name your cube (blank space in name is not allowed). Notification List is a list of email addresses which be notified on cube job success/failure.
Step 2. Dimensions
-
Click
Add Dimension, it popups two option: “Normal” and “Derived”: “Normal” is to add a normal independent dimension column, “Derived” is to add a derived dimension column. Read more in How to optimize cubes. -
Click “Normal” and then select a dimension column, give it a meaningful name.
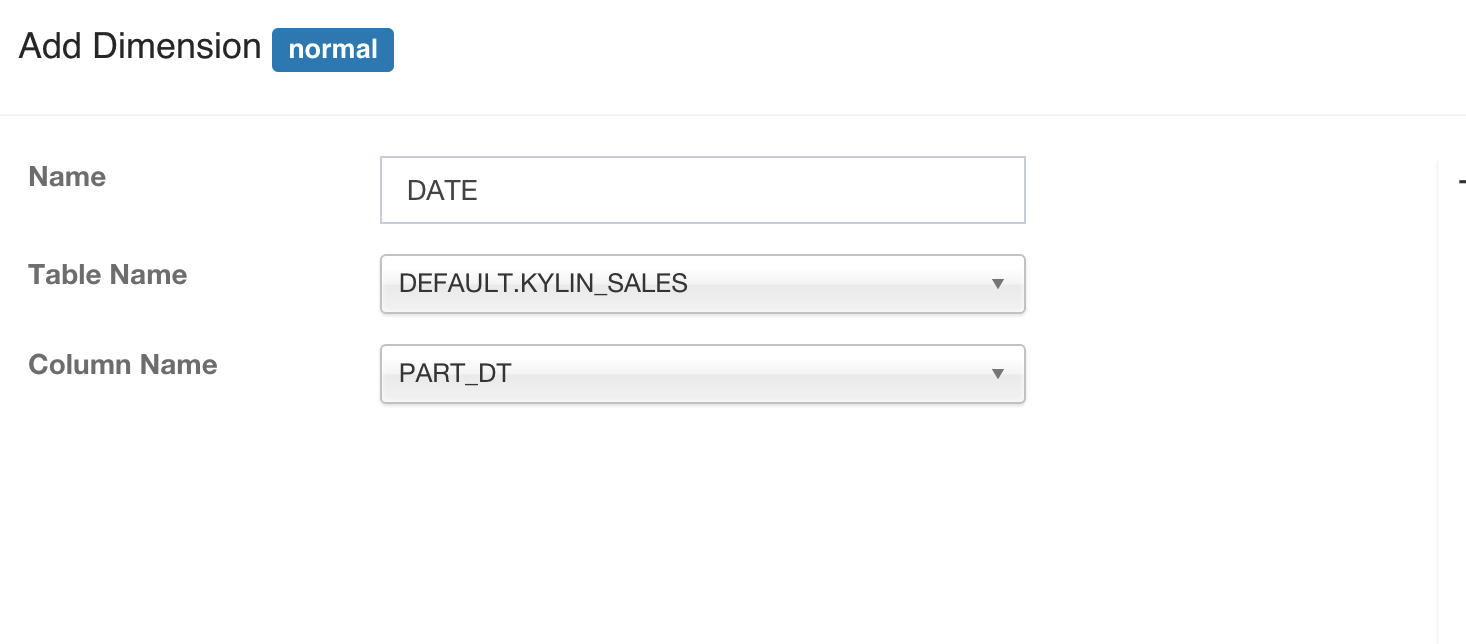
-
[Optional] Click “Derived” and then pickup 1 more multiple columns on lookup table, give them a meaningful name.
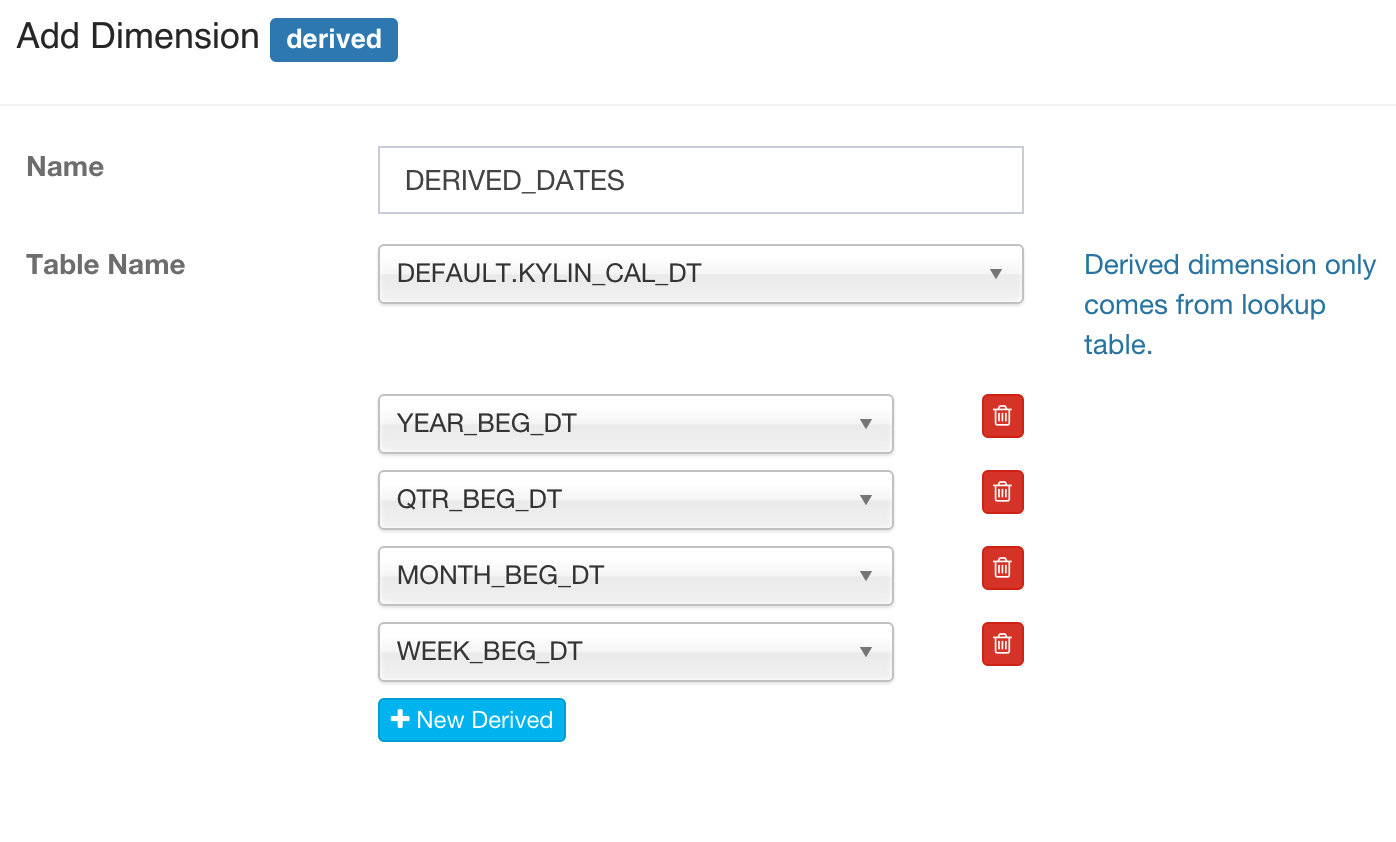
-
Repeate 2 and 3 to add all dimension columns; you can do this in batch for “Normal” dimension with the button
Auto Generator.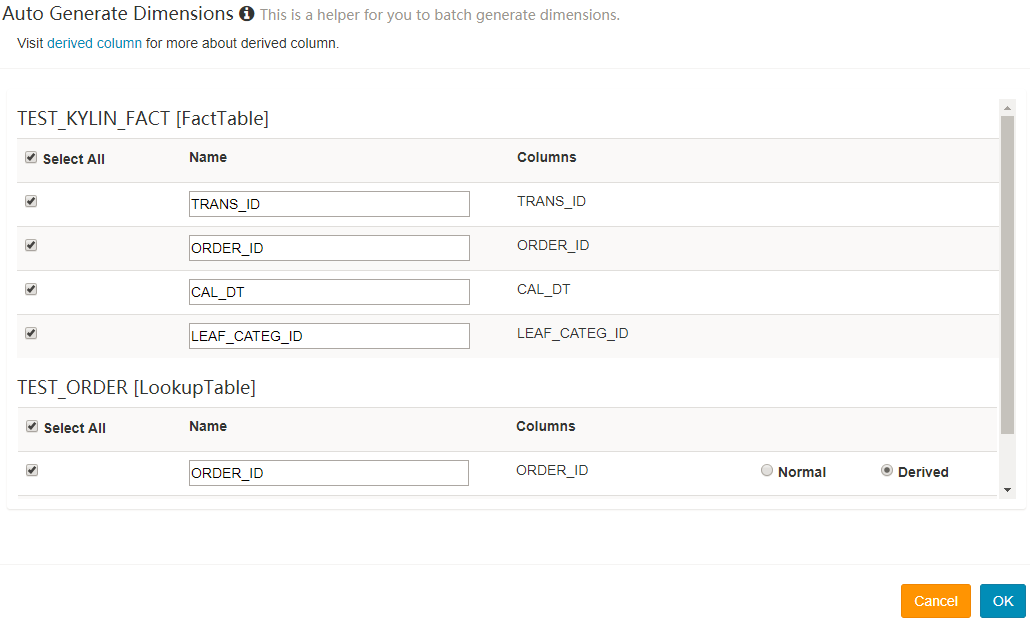
-
Click “Next” after select all dimensions.
Step 3. Measures
-
Click the
+Measureto add a new measure.

-
There are 6 types of measure according to its expression:
SUM,MAX,MIN,COUNT,COUNT_DISTINCTandTOP_N. Properly select the return type forCOUNT_DISTINCTandTOP_N, as it will impact on the cube size.-
SUM
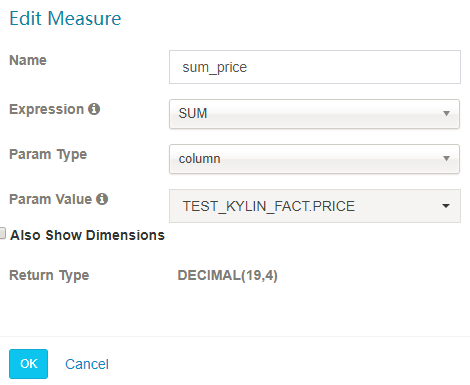
-
MIN
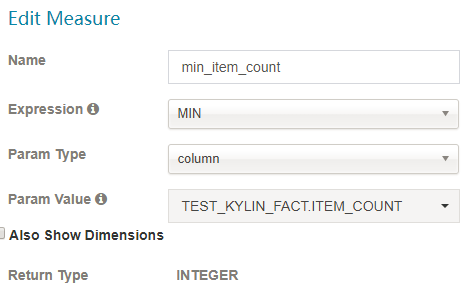
-
MAX
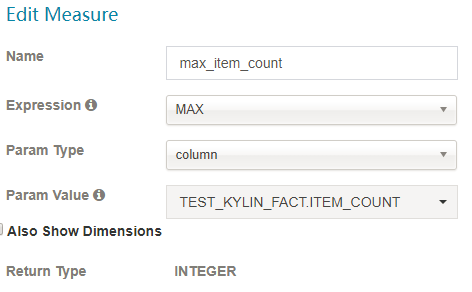
-
COUNT
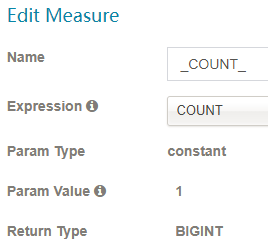
-
DISTINCT_COUNT
This measure has two implementations:
a) approximate implementation with HyperLogLog, select an acceptable error rate, lower error rate will take more storage.
b) precise implementation with bitmap (see limitation in https://issues.apache.org/jira/browse/KYLIN-1186).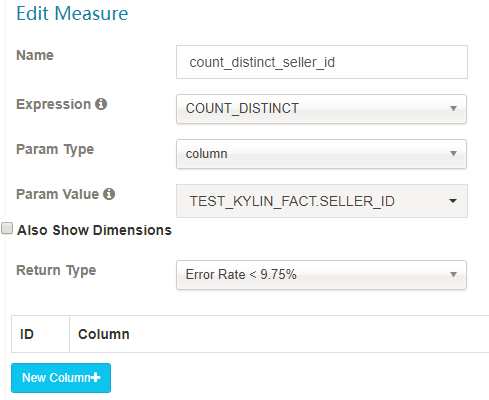
Pleaste note: distinct count is a very heavy data type, it is slower to build and query comparing to other measures.
- TOP_N
Approximate TopN measure pre-calculates the top records in each dimension combination, it will provide higher performance in query time than no pre-calculation; Need specify two parameters here: the first is the column will be used as metrics for Top records (aggregated with SUM and then sorted in descending order); the second is the literal ID, represents the record like seller_id;
Properly select the return type, depends on how many top records to inspect: top 10, top 100 or top 1000.

-
Step 4. Refresh Setting
This step is designed for incremental cube build.
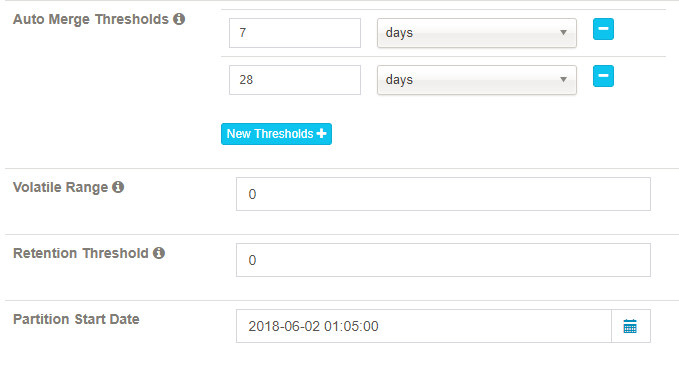
Auto Merge Time Ranges (days): merge the small segments into medium and large segment automatically. If you don’t want to auto merge, remove the default two ranges.
Retention Range (days): only keep the segment whose data is in past given days in cube, the old segment will be automatically dropped from head; 0 means not enable this feature.
Partition Start Date: the start date of this cube.
Step 5. Advanced Setting
Aggregation Groups: by default Kylin put all dimensions into one aggregation group; you can create multiple aggregation groups by knowing well about your query patterns. For the concepts of “Mandatory Dimensions”, “Hierarchy Dimensions” and “Joint Dimensions”, read this blog: New Aggregation Group
Rowkeys: the rowkeys are composed by the dimension encoded values. “Dictionary” is the default encoding method; If a dimension is not fit with dictionary (e.g., cardinality > 10 million), select “false” and then enter the fixed length for that dimension, usually that is the max. length of that column; if a value is longer than that size it will be truncated. Please note, without dictionary encoding, the cube size might be much bigger.
You can drag & drop a dimension column to adjust its position in rowkey; Put the mandantory dimension at the begining, then followed the dimensions that heavily involved in filters (where condition). Put high cardinality dimensions ahead of low cardinality dimensions.
Step 6. Overview & Save
You can overview your cube and go back to previous step to modify it. Click the Save button to complete the cube creation.
Cheers! now the cube is created, you can go ahead to build and play it.