
Environment
Kylin requires a properly setup Hadoop environment to run. Following are the minimal request to run Kylin, for more detial, please check Hadoop Environment.
It is most common to install Kylin on a Hadoop client machine, from which Kylin can talk with the Hadoop cluster via command lines including hive, hbase, hadoop, etc. The scenario is depicted as:
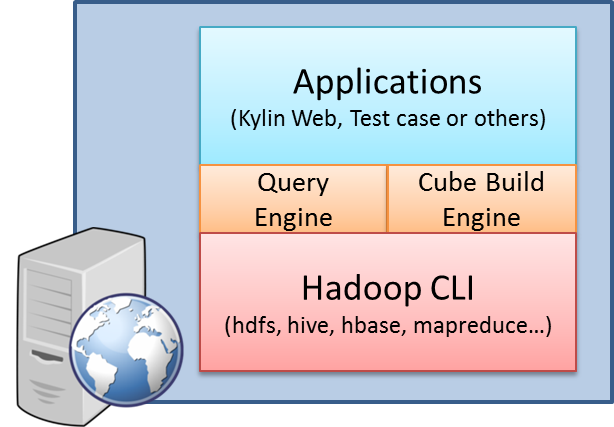
For normal use cases, the application in the above picture means Kylin Web, which contains a web interface for cube building, querying and all sorts of management. Kylin Web launches a query engine for querying and a cube build engine for building cubes. These two engines interact with the Hadoop components, like hive and hbase.
Except for some prerequisite software installations, the core of Kylin installation is accomplished by running a single script. After running the script, you will be able to build sample cube and query the tables behind the cubes via a unified web interface.
Install Kylin
- Download latest Kylin binaries at http://kylin.apache.org/download
- Export KYLIN_HOME pointing to the extracted Kylin folder
- Make sure the user has the privilege to run hadoop, hive and hbase cmd in shell. If you are not so sure, you can run bin/check-env.sh, it will print out the detail information if you have some environment issues.
- To start Kylin, run bin/kylin.sh start, after the server starts, you can watch logs/kylin.log for runtime logs;
- To stop Kylin, run bin/kylin.sh stop
If you want to have multiple Kylin nodes running to provide high availability, please refer to this
After Kylin started you can visit http://hostname:7070/kylin. The default username/password is ADMIN/KYLIN. It’s a clean Kylin homepage with nothing in there. To start with you can: