
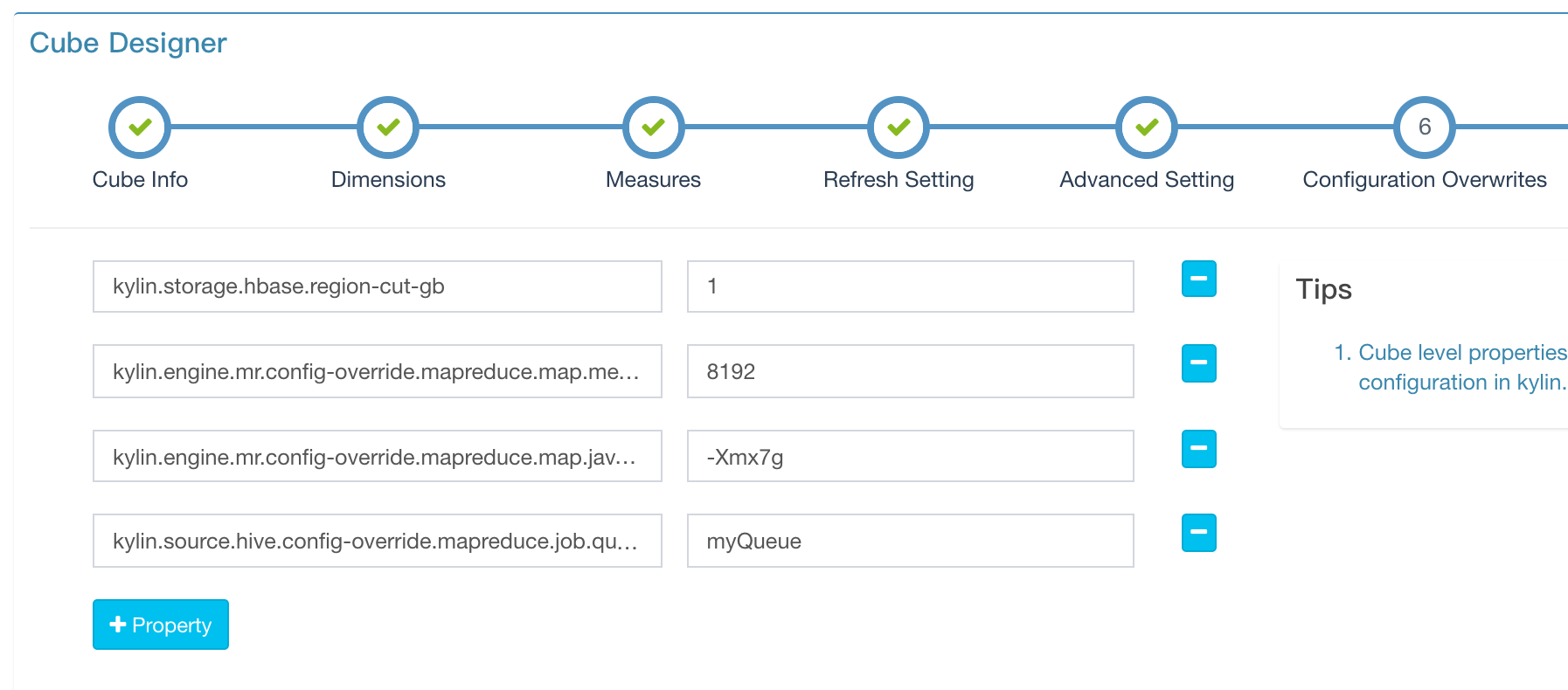
Overwrite default kylin.properties at Cube level
In conf/kylin.properties there are many parameters, which control/impact on Kylin’s behaviors; Most parameters are global configs like security or job related; while some are Cube related; These Cube related parameters can be customized at each Cube level, so you can control the behaviors more flexibly. The GUI to do this is in the “Configuration Overwrites” step of the Cube wizard, as the screenshot below.
Overwrite default Spark conf at Cube level
The configurations for Spark are managed in conf/kylin.properties with prefix kylin.engine.spark-conf.. For example, if you want to use job queue “myQueue” to run Spark, setting “kylin.engine.spark-conf.spark.yarn.queue=myQueue” will let Spark get “spark.yarn.queue=myQueue” feeded when submitting applications. The parameters can be configured at Cube level, which will override the default values in conf/kylin.properties.
Allocate more memory to Kylin instance
Open bin/setenv.sh, which has two sample settings for KYLIN_JVM_SETTINGS environment variable; The default setting is small (4GB at max.), you can comment it and then un-comment the next line to allocate 16GB:
export KYLIN_JVM_SETTINGS="-Xms1024M -Xmx4096M -Xss1024K -XX:MaxPermSize=128M -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:$KYLIN_HOME/logs/kylin.gc.$$ -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=64M"
# export KYLIN_JVM_SETTINGS="-Xms16g -Xmx16g -XX:MaxPermSize=512m -XX:NewSize=3g -XX:MaxNewSize=3g -XX:SurvivorRatio=4 -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:CMSInitiatingOccupancyFraction=70 -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError"Enable multiple job engines (HA)
Since Kylin 2.0, Kylin support multiple job engines running together, which is more extensible, available and reliable than the default job scheduler.
To enable the distributed job scheduler, you need to set or update the configs in the kylin.properties:
kylin.job.scheduler.default=2
kylin.job.lock=org.apache.kylin.storage.hbase.util.ZookeeperJobLock
Please add all job servers and query servers to the kylin.server.cluster-servers.
Enable LDAP or SSO authentication
Check How to Enable Security with LDAP and SSO
Enable email notification
Kylin can send email notification on job complete/fail; To enable this, edit conf/kylin.properties, set the following parameters:
mail.enabled=true
mail.host=your-smtp-server
mail.username=your-smtp-account
mail.password=your-smtp-pwd
mail.sender=your-sender-address
kylin.job.admin.dls=adminstrator-addressRestart Kylin server to take effective. To disable, set mail.enabled back to false.
Administrator will get notifications for all jobs. Modeler and Analyst need enter email address into the “Notification List” at the first page of cube wizard, and then will get notified for that cube.
Enable MySQL as Kylin metadata storage
Kylin can use MySQL as the metadata storage, for the scenarios that HBase is not the best option; To enable this, you can perform the following steps:
- Install a MySQL server, e.g, v5.1.17;
- Create a new MySQL database for Kylin metadata, for example “kylin_metadata”;
- Download and copy MySQL JDBC connector “mysql-connector-java-
.jar" to $KYLIN_HOME/ext (if the folder does not exist, create it yourself); - Edit
conf/kylin.properties, set the following parameters:
kylin.metadata.url={your_metadata_tablename}@jdbc,url=jdbc:mysql://localhost:3306/kylin,username={your_username},password={your_password},driverClassName=com.mysql.jdbc.Driver
kylin.metadata.jdbc.dialect=mysql
kylin.metadata.jdbc.json-always-small-cell=true
kylin.metadata.jdbc.small-cell-meta-size-warning-threshold=100mb
kylin.metadata.jdbc.small-cell-meta-size-error-threshold=1gb
kylin.metadata.jdbc.max-cell-size=1mbIn “kylin.metadata.url” more configuration items can be added; The url, username, and password are required items. If not configured, the default configuration items will be used:
url: the JDBC connection URL;
username: JDBC user name
password: JDBC password, if encryption is selected, please put the encrypted password here;
driverClassName: JDBC driver class name, the default value is com.mysql.jdbc.Driver
maxActive: the maximum number of database connections, the default value is 5;
maxIdle: the maximum number of connections waiting, the default value is 5;
maxWait: The maximum number of milliseconds to wait for connection. The default value is 1000.
removeAbandoned: Whether to automatically reclaim timeout connections, the default value is true;
removeAbandonedTimeout: the number of seconds in the timeout period, the default is 300;
passwordEncrypted: Whether the JDBC password is encrypted or not, the default is false;- You can encrypt your password:
cd $KYLIN_HOME/tomcat/webapps/kylin/WEB-INF/lib
java -classpath kylin-server-base-\<version\>.jar:kylin-core-common-\<version\>.jar:spring-beans-4.3.10.RELEASE.jar:spring-core-4.3.10.RELEASE.jar:commons-codec-1.7.jar org.apache.kylin.rest.security.PasswordPlaceholderConfigurer AES <your_password>- Start Kylin