Set Up System Cube
Available since Apache Kylin v2.3.0
Main content of this section:
- [What is System Cube](#What is System Cube)
- [How to Set Up System Cube](#How to Set Up System Cube)
- [Automatically create System Cube](#Automatically create System Cube)
- [Details of System Cube](#Details of System Cube)
What is System Cube
For better supporting self-monitoring, a set of system Cubes are created under the system project, called "KYLIN_SYSTEM". Currently, there are five Cubes. Three are for query metrics, "METRICS_QUERY", "METRICS_QUERY_CUBE", "METRICS_QUERY_RPC". And the other two are for job metrics, "METRICS_JOB", "METRICS_JOB_EXCEPTION".
How to Set Up System Cube
In this section, we will introduce the method of manually enabling the system cube. If you want to automatically enable the system cube through shell scripts, please refer to [Automatically Create System Cube](#Automatically Create System Cube).
1. Prepare
Create a configuration file SCSinkTools.json in KYLIN_HOME directory.
For example:
[
{
"sink": "hive",
"storage_type": 2,
"cube_desc_override_properties": {
"kylin.cube.algorithm": "INMEM",
"kylin.cube.max-building-segments": "1"
}
}
]
2. Generate Metadata
Run the following command in KYLIN_HOME folder to generate related metadata:
./bin/kylin.sh org.apache.kylin.tool.metrics.systemcube.SCCreator \
-inputConfig SCSinkTools.json \
-output <output_folder>
By this command, the related metadata will be generated and its location is under the directory <output_folder>. The details are as follows, system_cube is our <output_folder>:
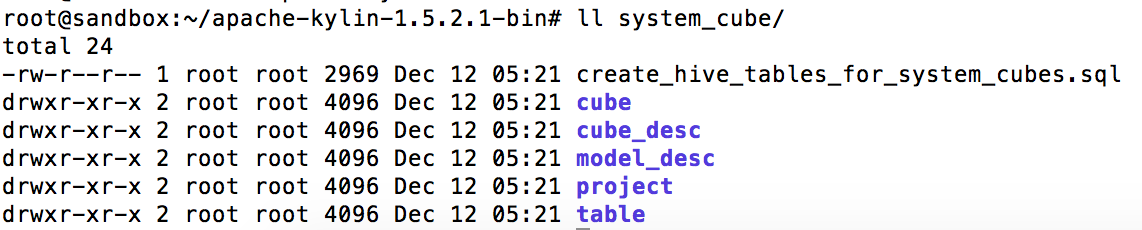
3. Set Up Datasource
Running the following command to create source hive tables:
hive -f <output_folder>/create_hive_tables_for_system_cubes.sql
By this command, the related hive table will be created.
4. Upload Metadata for System Cubes
Then we need to upload metadata to hbase by the following command:
./bin/metastore.sh restore <output_folder>
5. Reload Metadata
Finally, we need to reload metadata in Kylin web UI.
Then, a set of system Cubes will be created under the system project, called "KYLIN_SYSTEM".
6. System Cube build
When the system Cube is created, we need to build the Cube regularly.
Step 1. Create a shell script that builds the system Cube by calling org.apache.kylin.tool.job.CubeBuildingCLI
For example:
#!/bin/bash
dir=$(dirname ${0})
export KYLIN_HOME=${dir}/../
CUBE=$1
INTERVAL=$2
DELAY=$3
CURRENT_TIME_IN_SECOND=`date +%s`
CURRENT_TIME=$((CURRENT_TIME_IN_SECOND * 1000))
END_TIME=$((CURRENT_TIME-DELAY))
END=$((END_TIME - END_TIME%INTERVAL))
ID="$END"
echo "building for ${CUBE}_${ID}" >> ${KYLIN_HOME}/logs/build_trace.log
sh ${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.job.CubeBuildingCLI --cube ${CUBE} --endTime ${END} > ${KYLIN_HOME}/logs/system_cube_${CUBE}_${END}.log 2>&1 &
Step 2. Then run this shell script regularly. For example, add a cron job as follows:
0 */2 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_QUERY_QA 3600000 1200000
20 */2 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_QUERY_CUBE_QA 3600000 1200000
40 */4 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_QUERY_RPC_QA 3600000 1200000
30 */4 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_JOB_QA 3600000 1200000
50 */12 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_JOB_EXCEPTION_QA 3600000 12000
Automatically create System Cube
Kylin provides system-cube.sh from v2.6.0, users can automatically create system cube by executing this script.
-
Create System Cube:
sh bin/system-cube.sh setup -
Build System Cube:
sh bin/system-cube.sh build -
Add crontab job for System Cube:
sh bin/system-cube.sh cron
Note: System-cube.sh will call ${KYLIN_HOME}/bin/build-incremental-cube.sh to submit build job. In build-incremental-cube.sh, the user name and password of ADMIN:KYLIN are used by default as authentication to call kylin's rebuild API. If you have changed the password of the ADMIN user or want to use a user other than ADMIN to submit the build job, please find the ADMIN:KYLIN in build-incremental-cube.sh and replace it with the correct user name and password.
Details of System Cube
Common Dimension
For all of these Cube, admins can query at four time granularities. From higher level to lower, it's as follows:
| KYEAR_BEGIN_DATE | year |
| KMONTH_BEGIN_DATE | month |
| KWEEK_BEGIN_DATE | week |
| KDAY_DATE | date |
METRICS_QUERY
This Cube is for collecting query metrics at the highest level. The details are as follows:
| Dimension | |
|---|---|
| HOST | the host of server for query engine |
| KUSER | the user who executes the query |
| PROJECT | the project where the query executes |
| REALIZATION | the cube which the query hits. In Kylin, there are two OLAP realizations: Cube, or Hybrid of Cubes |
| REALIZATION_TYPE | |
| QUERY_TYPE | users can query on different data sources: CACHE, OLAP, LOOKUP_TABLE, HIVE |
| EXCEPTION | when doing query, exceptions may happen. It's for classifying different exception types |
| Measure | |
|---|---|
| COUNT | |
| MIN, MAX, SUM, PERCENTILE_APPROX of QUERY_TIME_COST | the time cost for the whole query |
| MAX, SUM of CALCITE_SIZE_RETURN | the row count of the result Calcite returns |
| MAX, SUM of STORAGE_SIZE_RETURN | the row count of the input to Calcite |
| MAX, SUM of CALCITE_SIZE_AGGREGATE_FILTER | the row count of Calcite aggregates and filters |
| COUNT DISTINCT of QUERY_HASH_CODE | the number of different queries |
METRICS_QUERY_RPC
This Cube is for collecting query metrics at the lowest level. For a query, the related aggregation and filter can be pushed down to each rpc target server. The robustness of rpc target servers is the foundation for better serving queries. The details are as follows:
| Dimension | |
|---|---|
| HOST | the host of server for query engine |
| PROJECT | the project where the query executes |
| REALIZATION | the cube which the query hits |
| RPC_SERVER | the rpc related target server |
| EXCEPTION | the exception of a rpc call. If no exception,"NULL" is used |
| Measure | |
|---|---|
| COUNT | |
| MAX, SUM, PERCENTILE_APPROX of CALL_TIME | the time cost of a rpc all |
| MAX, SUM of COUNT_SKIP | based on fuzzy filters or else, a few rows will be skiped. This indicates the skipped row count |
| MAX, SUM of SIZE_SCAN | the row count actually scanned |
| MAX, SUM of SIZE_RETURN | the row count actually returned |
| MAX, SUM of SIZE_AGGREGATE | the row count actually aggregated |
| MAX, SUM of SIZE_AGGREGATE_FILTER | the row count actually aggregated and filtered, = SIZE_SCAN - SIZE_RETURN |
METRICS_QUERY_CUBE
This Cube is for collecting query metrics at the Cube level. The most important are cuboids related, which will serve for Cube planner. The details are as follows:
| Dimension | |
|---|---|
| CUBE_NAME | |
| SEGMENT_NAME | |
| CUBOID_SOURCE | source cuboid parsed based on query and Cube design |
| CUBOID_TARGET | target cuboid already precalculated and served for source cuboid |
| IF_MATCH | whether source cuboid and target cuboid are equal |
| IF_SUCCESS | whether a query on this Cube is successful or not |
| Measure | |
|---|---|
| COUNT | |
| WEIGHT_PER_HIT | |
| MAX, SUM of STORAGE_CALL_COUNT | the number of rpc calls for a query hit on this Cube |
| MAX, SUM of STORAGE_CALL_TIME_SUM | sum of time cost for the rpc calls of a query |
| MAX, SUM of STORAGE_CALL_TIME_MAX | max of time cost among the rpc calls of a query |
| MAX, SUM of STORAGE_COUNT_SKIP | the sum of row count skipped for the related rpc calls |
| MAX, SUM of STORAGE_COUNT_SCAN | the sum of row count scanned for the related rpc calls |
| MAX, SUM of STORAGE_COUNT_RETURN | the sum of row count returned for the related rpc calls |
| MAX, SUM of STORAGE_COUNT_AGGREGATE | the sum of row count aggregated for the related rpc calls |
| MAX, SUM of STORAGE_COUNT_AGGREGATE_FILTER | the sum of row count aggregated and filtered for the related rpc calls, = STORAGE_SIZE_SCAN - STORAGE_SIZE_RETURN |
METRICS_JOB
In Kylin, there are mainly three types of job:
- "BUILD", for building Cube segments from HIVE.
- "MERGE", for merging Cube segments in HBASE.
- "OPTIMIZE", for dynamically adjusting the precalculated cuboid tree base on the base cuboid in HBASE.
This Cube is for collecting job metrics. The details are as follows:
| Dimension | |
|---|---|
| HOST | the host of server for job engine |
| KUSER | the user who run the job |
| PROJECT | the project where the job runs |
| CUBE_NAME | the cube with which the job is related |
| JOB_TYPE | build, merge or optimize |
| CUBING_TYPE | in kylin, there are two cubing algorithms, Layered & Fast(InMemory) |
| Measure | |
|---|---|
| COUNT | |
| MIN, MAX, SUM, PERCENTILE_APPROX of DURATION | the duration from a job start to finish |
| MIN, MAX, SUM of TABLE_SIZE | the size of data source in bytes |
| MIN, MAX, SUM of CUBE_SIZE | the size of created Cube segment in bytes |
| MIN, MAX, SUM of PER_BYTES_TIME_COST | = DURATION / TABLE_SIZE |
| MIN, MAX, SUM of WAIT_RESOURCE_TIME | a job may includes serveral MR(map reduce) jobs. Those MR jobs may wait because of lack of Hadoop resources. |
| MAX, SUM of step_duration_distinct_columns | |
| MAX, SUM of step_duration_dictionary | |
| MAX, SUM of step_duration_inmem_cubing | |
| MAX, SUM of step_duration_hfile_convert | |
METRICS_JOB_EXCEPTION
This Cube is for collecting job exception metrics. The details are as follows:
| Dimension | |
|---|---|
| HOST | the host of server for job engine |
| KUSER | the user who run a job |
| PROJECT | the project where the job runs |
| CUBE_NAME | the cube with which the job is related |
| JOB_TYPE | build, merge or optimize |
| CUBING_TYPE | in kylin, there are two cubing algorithms, Layered & Fast(InMemory) |
| EXCEPTION | when running a job, exceptions may happen. It's for classifying different exception types |
| Measure |
|---|
| COUNT |