Apache Flink
Introduction
This document describes how to use Kylin as a data source in Apache Flink;
There were several attempts to do this in Scala and JDBC, but none of them works:
We will try use CreateInput and JDBCInputFormat in batch mode and access via JDBC to Kylin. But it isn’t implemented in Scala, is only in Java MailList. This doc will go step by step solving these problems.
Pre-requisites
- Need an instance of Kylin, with a Cube; Sample Cube will be good enough.
- Scala and Apache Flink Installed
- IntelliJ Installed and configured for Scala/Flink (see Flink IDE setup guide )
Used software:
- Apache Flink v1.2-SNAPSHOT
- Apache Kylin v1.5.2 (v1.6.0 also works)
- IntelliJ v2016.2
- Scala v2.11
Starting point:
This can be out initial skeleton:
import org.apache.flink.api.scala._
val env = ExecutionEnvironment.getExecutionEnvironment
val inputFormat = JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("org.apache.kylin.jdbc.Driver")
.setDBUrl("jdbc:kylin://172.17.0.2:7070/learn_kylin")
.setUsername("ADMIN")
.setPassword("KYLIN")
.setQuery("select count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt")
.finish()
val dataset =env.createInput(inputFormat)
The first error is: ![]()
Add to Scala:
import org.apache.flink.api.java.io.jdbc.JDBCInputFormat
Next error is ![]()
We can solve dependencies (mvn repository: jdbc); Add this to your pom.xml:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
Solve dependencies of row
Similar to previous point we need solve dependencies of Row Class (mvn repository: Table) :

- In pom.xml add:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.10</artifactId>
<version>${flink.version}</version>
</dependency>
- In Scala:
import org.apache.flink.api.table.Row
Solve RowTypeInfo property (and their new dependencies)
This is the new error to solve:

-
If check the code of JDBCInputFormat.java, we can see this new property (and mandatory) added on Apr 2016 by FLINK-3750 Manual JDBCInputFormat v1.2 in Java
Add the new Property: setRowTypeInfo
val inputFormat = JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("org.apache.kylin.jdbc.Driver")
.setDBUrl("jdbc:kylin://172.17.0.2:7070/learn_kylin")
.setUsername("ADMIN")
.setPassword("KYLIN")
.setQuery("select count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt")
.setRowTypeInfo(DB_ROWTYPE)
.finish()
-
How can configure this property in Scala? In Attempt4, there is an incorrect solution
We can check the types using the intellisense:

Then we will need add more dependences; Add to scala:
import org.apache.flink.api.table.typeutils.RowTypeInfo
import org.apache.flink.api.common.typeinfo.{BasicTypeInfo, TypeInformation}
Create a Array or Seq of TypeInformation[ ]

Solution:
var stringColum: TypeInformation[String] = createTypeInformation[String]
val DB_ROWTYPE = new RowTypeInfo(Seq(stringColum))
Solve ClassNotFoundException
![]()
Need find the kylin-jdbc-x.x.x.jar and then expose to Flink
-
Find the Kylin JDBC jar
From Kylin Download choose Binary and the correct version of Kylin and HBase
Download & Unpack: in ./lib:

-
Make this JAR accessible to Flink
If you execute like service you need put this JAR in you Java class path using your .bashrc
![]()
Check the actual value: ![]()
Check the permission for this file (Must be accessible for you):
![]()
If you are executing from IDE, need add your class path manually:
On IntelliJ: ![]() >
> ![]() >
> ![]() >
> ![]()
The result, will be similar to: 
Solve "Couldn’t access resultSet" error
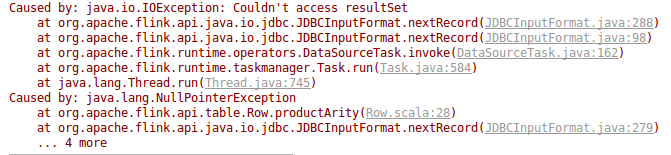
It is related with Flink 4108 (MailList) and Timo Walther make a PR
If you are running Flink <= 1.2 you will need apply this path and make clean install
Solve the casting error

In the error message you have the problem and solution …. nice ;) ¡¡
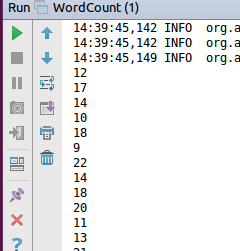
The result
The output must be similar to this, print the result of query by standard output:
Now, more complex
Try with a multi-colum and multi-type query:
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers
from kylin_sales
group by part_dt
order by part_dt
Need changes in DB_ROWTYPE:

And import lib of Java, to work with Data type of Java ![]()
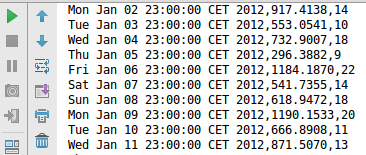
The new result will be:
Error: Reused Connection

Check if your HBase and Kylin is working. Also you can use Kylin UI for it.
Error: java.lang.AbstractMethodError: ….Avatica Connection
See Kylin 1898
It is a problem with kylin-jdbc-1.x.x. JAR, you need use Calcite 1.8 or above; The solution is to use Kylin 1.5.4 or above.

Error: can't expand macros compiled by previous versions of scala
Is a problem with versions of scala, check in with "scala -version" your actual version and choose your correct POM.
Perhaps you will need a IntelliJ > File > Invalidates Cache > Invalidate and Restart.
I added POM for Scala 2.11
Final Words
Now you can read Kylin’s data from Apache Flink, great!
Solved all integration problems, and tested with different types of data (Long, BigDecimal and Dates). The patch has been comited at 15 Oct, then, will be part of Flink 1.2.