Setup JDBC Data Source
Available since Apache Kylin v2.3.x
Supported JDBC data source
Since v2.3.0 Apache Kylin starts to support JDBC as the third type of data source (after Hive, Kafka). User can integrate Kylin with their SQL database or data warehouses like MySQL, Microsoft SQL Server and HP Vertica directly. Other relational databases are easy to support as well.
Configure JDBC data source
- Prepare Sqoop
Kylin uses Apache Sqoop to load data from relational databases to HDFS. Download and install the latest version of Sqoop in the same machine with Kylin. We will use SQOOP_HOME environment variable to indicate the installation directory of Sqoop in this guide.
- Prepare JDBC driver
You need to download the JDBC Driver of your database to the Kylin server. The JDBC driver jar should be added to $KYLIN_HOME/ext and $SQOOP_HOME/lib folder.
- Configure Kylin
In $KYLIN_HOME/conf/kylin.properties, add the following configurations.
MySQL sample:
kylin.source.default=8
kylin.source.jdbc.connection-url=jdbc:mysql://hostname:3306/employees
kylin.source.jdbc.driver=com.mysql.jdbc.Driver
kylin.source.jdbc.dialect=mysql
kylin.source.jdbc.user=your_username
kylin.source.jdbc.pass=your_password
kylin.source.jdbc.sqoop-home=/usr/hdp/current/sqoop-client/bin
kylin.source.jdbc.filed-delimiter=|
SQL Server sample:
kylin.source.default=8
kylin.source.jdbc.connection-url=jdbc:sqlserver://hostname:1433;database=sample
kylin.source.jdbc.driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
kylin.source.jdbc.dialect=mssql
kylin.source.jdbc.user=your_username
kylin.source.jdbc.pass=your_password
kylin.source.jdbc.sqoop-home=/usr/hdp/current/sqoop-client/bin
kylin.source.jdbc.filed-delimiter=|
Amazon Redshift sample:
kylin.source.default=8
kylin.source.jdbc.connection-url=jdbc:redshift://hostname:5439/sample
kylin.source.jdbc.driver=com.amazon.redshift.jdbc.Driver
kylin.source.jdbc.dialect=default
kylin.source.jdbc.user=user
kylin.source.jdbc.pass=pass
kylin.source.jdbc.sqoop-home=/usr/hdp/current/sqoop-client/bin
kylin.source.default=8
kylin.source.jdbc.filed-delimiter=|
There is another parameter specifing how many splits should be divided. Sqoop would run a mapper for each split.
kylin.source.jdbc.sqoop-mapper-num=4
To make each mapper gets even input, the splitting column is selected by the following rules:
- ShardBy column, if exists;
- Partition date column, if exists;
- High cardinality column, if exists;
- Numeric column, if exists;
- A column at first glance.
Please note, when configure these parameters in conf/kylin.properties, all your projects are using the JDBC as data source.
Load tables from JDBC data source
Restart Kylin to make the changes effective. You can load tables from JDBC data source now. Visit Kylin web and then navigate to the data source panel.
Click Load table button and then input table' name, or click the "Load Table From Tree" button and select the tables to load. Uncheck Calculate column cardinality because this feature is not supported for JDBC data source.
Click "Sync", Kylin will load the tables' definition through the JDBC interface. You can see tables and columns when tables are loaded successfully, similar as Hive.
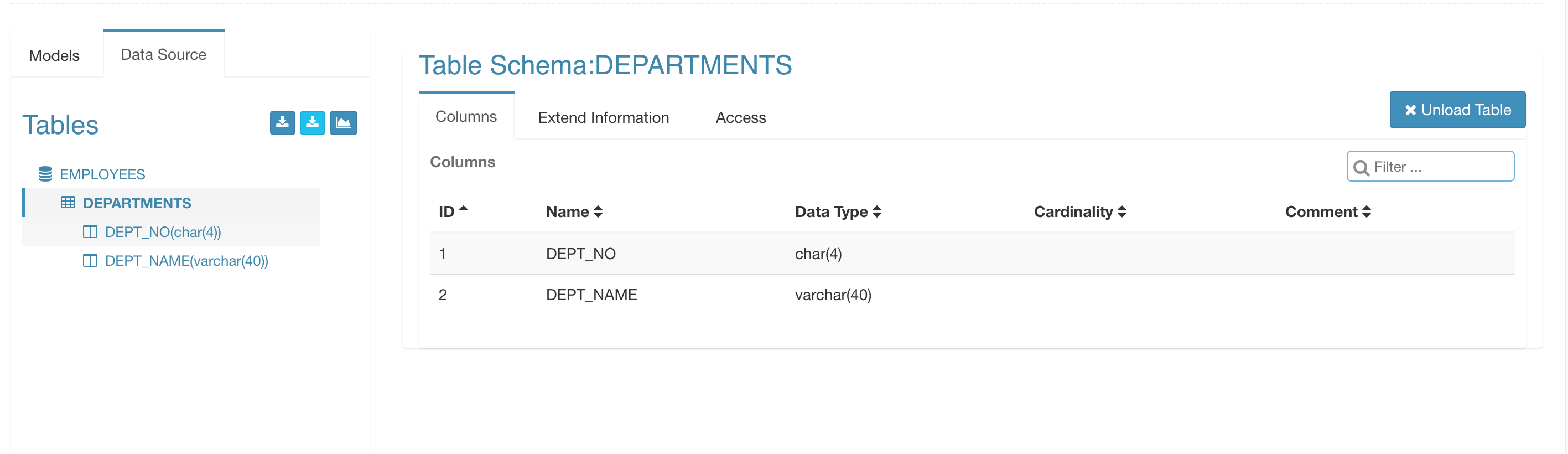
Go ahead and design your model and Cube. When building the Cube, Kylin will use Sqoop to import the data to HDFS, and then run building over it.