
自 Apache Kylin v2.3.x 起有效
支持 JDBC 数据源
自 v2.3.0 Apache Kylin 开始支持 JDBC 作为第三种数据源(继 Hive,Kafka)。用户可以直接集成 Kylin 和他们的 SQL 数据库或数据仓库如 MySQL,Microsoft SQL Server 和 HP Vertica。其他相关的数据库也很容易支持。
配置 JDBC 数据源
- 准备 Sqoop
Kylin 使用 Apache Sqoop 从关系型数据库加载数据到 HDFS。在与 Kylin 同一个机器上下载并安装最新版本的 Sqoop。我们使用 SQOOP_HOME 环境变量指出在本指南中 Sqoop 的安装路径。
- 准备 JDBC driver
需要下载您数据库的 JDBC Driver 到 Kylin server。JDBC driver jar 需要被加到 $KYLIN_HOME/ext 和 $SQOOP_HOME/lib 文件夹下。
- 配置 Kylin
在 $KYLIN_HOME/conf/kylin.properties 中,添加以下配置。
MySQL 样例:
kylin.source.default=8
kylin.source.jdbc.connection-url=jdbc:mysql://hostname:3306/employees
kylin.source.jdbc.driver=com.mysql.jdbc.Driver
kylin.source.jdbc.dialect=mysql
kylin.source.jdbc.user=your_username
kylin.source.jdbc.pass=your_password
kylin.source.jdbc.sqoop-home=/usr/hdp/current/sqoop-client
kylin.source.jdbc.filed-delimiter=|
SQL Server 样例:
kylin.source.default=8
kylin.source.jdbc.connection-url=jdbc:sqlserver://hostname:1433;database=sample
kylin.source.jdbc.driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
kylin.source.jdbc.dialect=mssql
kylin.source.jdbc.user=your_username
kylin.source.jdbc.pass=your_password
kylin.source.jdbc.sqoop-home=/usr/hdp/current/sqoop-client
kylin.source.jdbc.filed-delimiter=|
Amazon Redshift 样例:
kylin.source.default=8
kylin.source.jdbc.connection-url=jdbc:redshift://hostname:5439/sample
kylin.source.jdbc.driver=com.amazon.redshift.jdbc.Driver
kylin.source.jdbc.dialect=default
kylin.source.jdbc.user=user
kylin.source.jdbc.pass=pass
kylin.source.jdbc.sqoop-home=/usr/hdp/current/sqoop-client
kylin.source.default=8
kylin.source.jdbc.filed-delimiter=|
这里有另一个参数指定应该分为多少个切片。Sqoop 将为每一个切片运行一个 mapper。
kylin.source.jdbc.sqoop-mapper-num=4
为了使每个 mapper 都能够输入,分割列按以下规则进行选择:
* ShardBy 列,如果存在;
* Partition date 列,如果存在;
* High cardinality 列,如果存在;
* Numeric 列,如果存在;
* 随便选一个。
请注意,当在 conf/kylin.properties 中配置这些参数时,您所有的 projects 使用 JDBC 作为数据源。
从 JDBC 数据源加载表
重启 Kylin 让改变生效。您现在可以从 JDBC 数据源加载表。访问 Kylin web 然后导航到数据源面板。
点击 Load table 按钮然后输入表名,或点击 “Load Table From Tree” 按钮然后选择要加载的表。不检查 Calculate column cardinality 因为对于 JDBC 数据源这个功能并不支持。
点击 “Sync”,Kylin 通过 JDBC 接口加载表定义。当表加载成功后您可以查看表和列,和 Hive 相似。
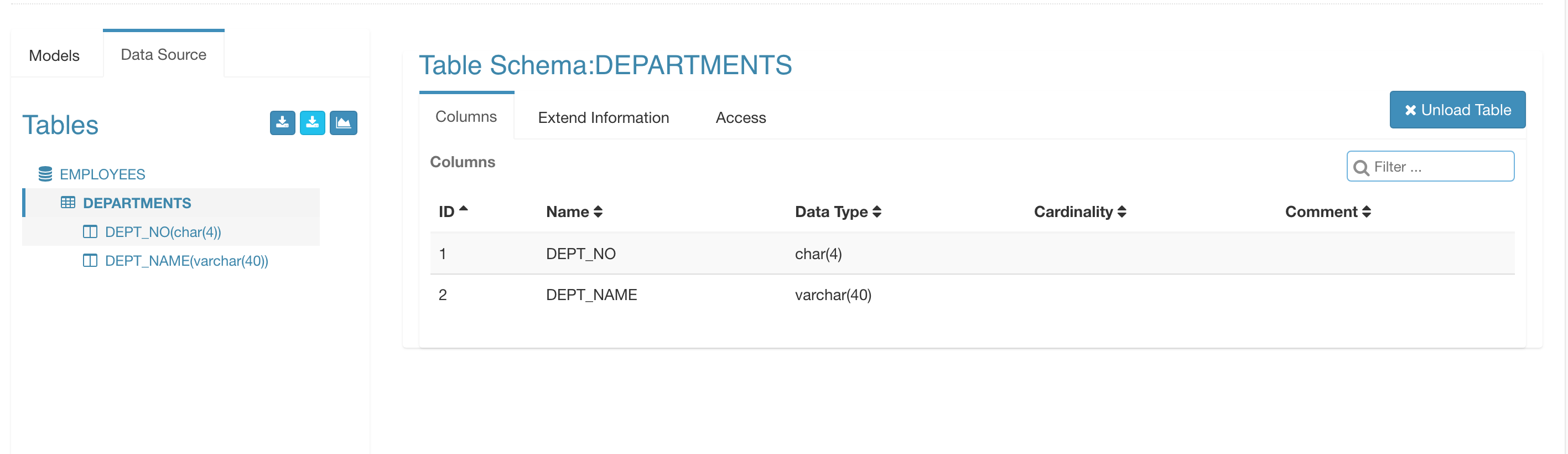
继续向前设计您的 model 和 Cube。当 building Cube 时,Kylin 将会使用 Sqoop 从 HDFS 中引入数据,然后在其上运行 building。