
自 Apache Kylin v2.3.0 起有效
什么是系统 Cube
为了更好的支持自我监控,在系统 project 下创建一组系统 Cubes,叫做 “KYLIN_SYSTEM”。现在,这里有五个 Cubes。三个用于查询指标,”METRICS_QUERY”,”METRICS_QUERY_CUBE”,”METRICS_QUERY_RPC”。另外两个是 job 指标,”METRICS_JOB”,”METRICS_JOB_EXCEPTION”。
如何建立系统 Cube
准备
在 KYLIN_HOME 目录下创建一个配置文件 SCSinkTools.json。
例如:
[
[
"org.apache.kylin.tool.metrics.systemcube.util.HiveSinkTool",
{
"storage_type": 2,
"cube_desc_override_properties": [
"java.util.HashMap",
{
"kylin.cube.algorithm": "INMEM",
"kylin.cube.max-building-segments": "1"
}
]
}
]
]
1. 生成 Metadata
在 KYLIN_HOME 文件夹下运行一下命令生成相关的 metadata:
./bin/kylin.sh org.apache.kylin.tool.metrics.systemcube.SCCreator \
-inputConfig SCSinkTools.json \
-output <output_forder>
通过这个命令,相关的 metadata 将会生成且其位置位于 <output_forder> 下。细节如下,system_cube 就是我们的 <output_forder>:
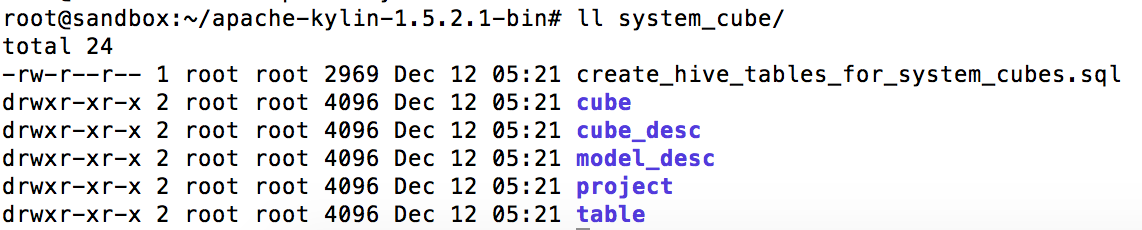
2. 建立数据源
运行下列命令生成 hive 源表:
hive -f <output_forder>/create_hive_tables_for_system_cubes.sql
通过这个命令,相关的 hive 表将会被创建。
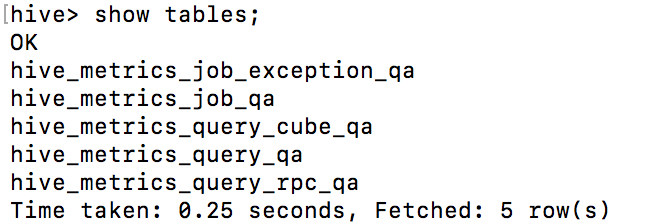
3. 为 System Cubes 上传 Metadata
然后我们需要通过下列命令上传 metadata 到 hbase:
./bin/metastore.sh restore <output_forder>
4. 重载 Metadata
最终,我们需要在 Kylin web UI 重载 metadata。
然后,一组系统 Cubes 将会被创建在系统 project 下,称为 “KYLIN_SYSTEM”。
5. 系统 Cube build
当系统 Cube 被创建,我们需要定期 build Cube。
-
创建一个 shell 脚本其通过调用 org.apache.kylin.tool.job.CubeBuildingCLI 来 build 系统 Cube
例如:
#!/bin/bash
dir=$(dirname ${0})
export KYLIN_HOME=${dir}/../
CUBE=$1
INTERVAL=$2
DELAY=$3
CURRENT_TIME_IN_SECOND=`date +%s`
CURRENT_TIME=$((CURRENT_TIME_IN_SECOND * 1000))
END_TIME=$((CURRENT_TIME-DELAY))
END=$((END_TIME - END_TIME%INTERVAL))
ID="$END"
echo "building for ${CUBE}_${ID}" >> ${KYLIN_HOME}/logs/build_trace.log
sh ${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.job.CubeBuildingCLI --cube ${CUBE} --endTime ${END} > ${KYLIN_HOME}/logs/system_cube_${CUBE}_${END}.log 2>&1 &-
然后定期运行这个 shell 脚本
例如,像接下来这样添加一个 cron job:
0 */2 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_QUERY_QA 3600000 1200000
20 */2 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_QUERY_CUBE_QA 3600000 1200000
40 */4 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_QUERY_RPC_QA 3600000 1200000
30 */4 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_JOB_QA 3600000 1200000
50 */12 * * * sh ${KYLIN_HOME}/bin/system_cube_build.sh KYLIN_HIVE_METRICS_JOB_EXCEPTION_QA 3600000 12000系统 Cube 的细节
普通 Dimension
对于这些 Cube,admins 能够用四个时间粒度查询。从高级别到低级别,如下:
| KYEAR_BEGIN_DATE | year |
| KMONTH_BEGIN_DATE | month |
| KWEEK_BEGIN_DATE | week |
| KDAY_DATE | date |
METRICS_QUERY
这个 Cube 用于在最高级别收集查询 metrics。细节如下:
| Dimension | |
|---|---|
| HOST | the host of server for query engine |
| PROJECT | |
| REALIZATION | in Kylin,there are two OLAP realizations: Cube,or Hybrid of Cubes |
| REALIZATION_TYPE | |
| QUERY_TYPE | users can query on different data sources,CACHE,OLAP,LOOKUP_TABLE,HIVE |
| EXCEPTION | when doing query,exceptions may happen. It's for classifying different exception types |
| Measure | |
|---|---|
| COUNT | |
| MIN,MAX,SUM of QUERY_TIME_COST | the time cost for the whole query |
| MAX,SUM of CALCITE_SIZE_RETURN | the row count of the result Calcite returns |
| MAX,SUM of STORAGE_SIZE_RETURN | the row count of the input to Calcite |
| MAX,SUM of CALCITE_SIZE_AGGREGATE_FILTER | the row count of Calcite aggregates and filters |
| COUNT DISTINCT of QUERY_HASH_CODE | the number of different queries |
METRICS_QUERY_RPC
这个 Cube 用于在最低级别收集查询 metrics。对于一个查询,相关的 aggregation 和 filter 能够下推到每一个 rpc 目标服务器。Rpc 目标服务器的健壮性是更好查询性能的基础。细节如下:
| Dimension | |
|---|---|
| HOST | the host of server for query engine |
| PROJECT | |
| REALIZATION | |
| RPC_SERVER | the rpc related target server |
| EXCEPTION | the exception of a rpc call. If no exception,"NULL" is used |
| Measure | |
|---|---|
| COUNT | |
| MAX,SUM of CALL_TIME | the time cost of a rpc all |
| MAX,SUM of COUNT_SKIP | based on fuzzy filters or else,a few rows will be skiped. This indicates the skipped row count |
| MAX,SUM of SIZE_SCAN | the row count actually scanned |
| MAX,SUM of SIZE_RETURN | the row count actually returned |
| MAX,SUM of SIZE_AGGREGATE | the row count actually aggregated |
| MAX,SUM of SIZE_AGGREGATE_FILTER | the row count actually aggregated and filtered,= SIZE_SCAN - SIZE_RETURN |
METRICS_QUERY_CUBE
这个 Cube 用于在 Cube 级别收集查询 metrics。最重要的是 cuboids 相关的,其为 Cube planner 提供服务。细节如下:
| Dimension | |
|---|---|
| CUBE_NAME | |
| CUBOID_SOURCE | source cuboid parsed based on query and Cube design |
| CUBOID_TARGET | target cuboid already precalculated and served for source cuboid |
| IF_MATCH | whether source cuboid and target cuboid are equal |
| IF_SUCCESS | whether a query on this Cube is successful or not |
| Measure | |
|---|---|
| COUNT | |
| MAX,SUM of STORAGE_CALL_COUNT | the number of rpc calls for a query hit on this Cube |
| MAX,SUM of STORAGE_CALL_TIME_SUM | sum of time cost for the rpc calls of a query |
| MAX,SUM of STORAGE_CALL_TIME_MAX | max of time cost among the rpc calls of a query |
| MAX,SUM of STORAGE_COUNT_SKIP | the sum of row count skipped for the related rpc calls |
| MAX,SUM of STORAGE_SIZE_SCAN | the sum of row count scanned for the related rpc calls |
| MAX,SUM of STORAGE_SIZE_RETURN | the sum of row count returned for the related rpc calls |
| MAX,SUM of STORAGE_SIZE_AGGREGATE | the sum of row count aggregated for the related rpc calls |
| MAX,SUM of STORAGE_SIZE_AGGREGATE_FILTER | the sum of row count aggregated and filtered for the related rpc calls,= STORAGE_SIZE_SCAN - STORAGE_SIZE_RETURN |
METRICS_JOB
在 Kylin 中,主要有三种类型的 job:
- “BUILD”,为了从 HIVE 中 building Cube segments。
- “MERGE”,为了在 HBASE 中 merging Cube segments。
- “OPTIMIZE”,为了在 HBASE 中基于 base cuboid 动态调整预计算 cuboid tree。
这个 Cube 是用来收集 job 指标。细节如下:
| Dimension | |
|---|---|
| PROJECT | |
| CUBE_NAME | |
| JOB_TYPE | |
| CUBING_TYPE | in kylin,there are two cubing algorithms,Layered & Fast(InMemory) |
| Measure | |
|---|---|
| COUNT | |
| MIN,MAX,SUM of DURATION | the duration from a job start to finish |
| MIN,MAX,SUM of TABLE_SIZE | the size of data source in bytes |
| MIN,MAX,SUM of CUBE_SIZE | the size of created Cube segment in bytes |
| MIN,MAX,SUM of PER_BYTES_TIME_COST | = DURATION / TABLE_SIZE |
| MIN,MAX,SUM of WAIT_RESOURCE_TIME | a job may includes serveral MR(map reduce) jobs. Those MR jobs may wait because of lack of Hadoop resources. |
METRICS_JOB_EXCEPTION
这个 Cube 是用来收集 job exception 指标。细节如下:
| Dimension | |
|---|---|
| PROJECT | |
| CUBE_NAME | |
| JOB_TYPE | |
| CUBING_TYPE | |
| EXCEPTION | when running a job,exceptions may happen. It's for classifying different exception types |
| Measure |
|---|
| COUNT |