
Introduction
If a query can not be answered by any cube, Kylin supports pushing down such query to backup query engines like Hive, SparkSQL, Impala through JDBC. In the following, Hive is used as an example, as it is one of Kylin’s data sources and be convenient to configure.
Query Pushdown config
-
In Kylin’s installation directory, uncomment configuration item
kylin.query.pushdown.runner-class-nameof config filekylin.properties, and set it toorg.apache.kylin.query.adhoc.PushDownRunnerJdbcImpl -
Add configuration items below in config file
kylin.properties.-
kylin.query.pushdown.jdbc.url: Hive JDBC’s URL.
-
kylin.query.pushdown.jdbc.driver: Hive Jdbc’s driver class name.
-
kylin.query.pushdown.jdbc.username: Hive Jdbc’s user name.
-
kylin.query.pushdown.jdbc.password: Hive Jdbc’s password.
-
kylin.query.pushdown.jdbc.pool-max-total: Hive Jdbc’s connection pool’s max connected connection number, default value is 8
-
kylin.query.pushdown.jdbc.pool-max-idle: Hive Jdbc’s connection pool’s max waiting connection number, default value is 8
-
kylin.query.pushdown.jdbc.pool-min-idle: Hive Jdbc’s connection pool’s min connected connection number, default value is 0
-
Here is a sample configuration; remember to change host “hiveserver” and port “10000” with your cluster configuraitons.
kylin.query.pushdown.runner-class-name=org.apache.kylin.query.adhoc.PushDownRunnerJdbcImpl
kylin.query.pushdown.jdbc.url=jdbc:hive2://hiveserver:10000/default
kylin.query.pushdown.jdbc.driver=org.apache.hive.jdbc.HiveDriver
kylin.query.pushdown.jdbc.username=hive
kylin.query.pushdown.jdbc.password=
kylin.query.pushdown.jdbc.pool-max-total=8
kylin.query.pushdown.jdbc.pool-max-idle=8
kylin.query.pushdown.jdbc.pool-min-idle=0- Restart Kylin
Do Query Pushdown
After Query Pushdown is configured, user is allowed to do flexible queries to the imported tables without avaible cubes.
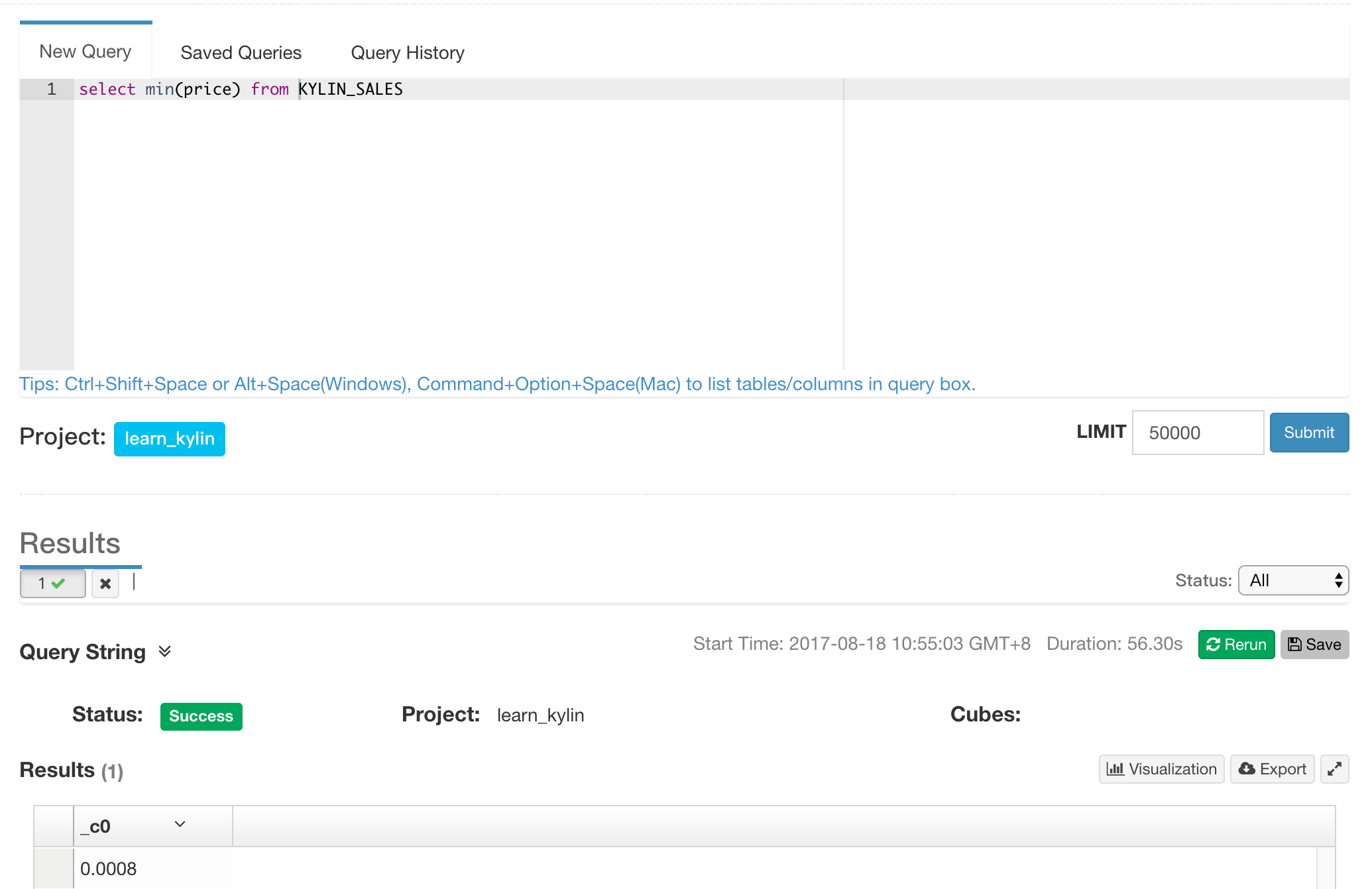
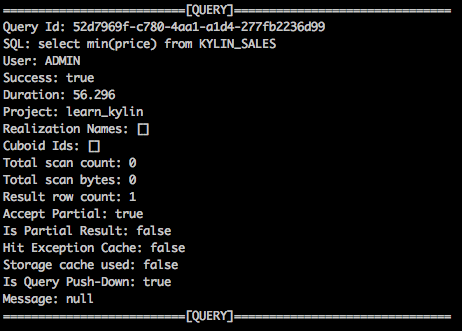
If query is answered by backup engine, Is Query Push-Down is set to true in the log.
#