
Kylin Server modes
Kylin instances are stateless, the runtime state is saved in its metadata store in HBase (specified by kylin.metadata.url in conf/kylin.properties). For load balance considerations it is recommended to run multiple Kylin instances sharing the same metadata store, thus they share the same state on table schemas, job status, Cube status, etc.
Each of the Kylin instance has a “kylin.server.mode” entry in conf/kylin.properties specifying the runtime mode, it has three options:
- job : run job engine in this instance; Kylin job engine manages the jobs to cluster;
- query : run query engine only; Kylin query engine accepts and answers your SQL queries;
- all : run both job engine and query engines in this instance.
By default only one instance can run the job engine (“all” or “job” mode), the others should be in the “query” mode.
If you want to run multiple job engines to get high availability or handle heavy concurrent jobs, please check “Enable multiple job engines” in Advanced settings page.
A typical scenario is depicted in the following chart:
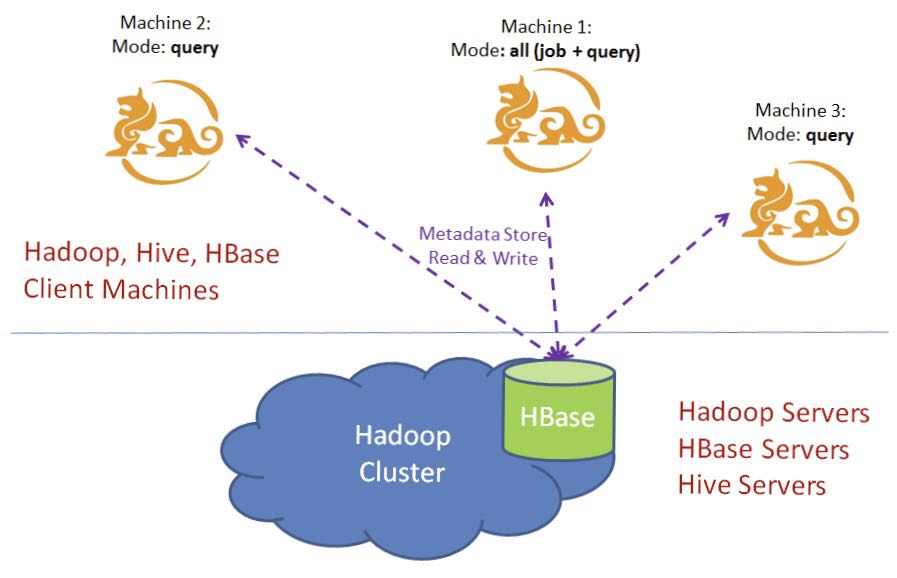
Configure Multiple Kylin Servers
If you are running Kylin in a cluster where you have multiple Kylin server instances, please make sure you have the following property correctly configured in conf/kylin.properties for EVERY instance.
kylin.rest.servers
List of servers in use, this enables one instance to notify other servers when there is event change. For example:
kylin.rest.servers=host1:7070,host2:7070
kylin.server.mode
Make sure there is only one instance whosekylin.server.modeis set to “all” or “job”, others should be “query”
kylin.server.mode=all
Setup Load Balancer
To enable Kylin service high availability, you need setup a load balancer in front of these servers, letting it routes the incoming requests to the cluster. Client side communicates with the load balancer, instead of with a specific Kylin instance. The setup of load balancer is out of the scope; you may select an implementation like Nginx, F5 or cloud LB service.
Configure Read/Write separated deployment
Kylin can work with two clusters to gain better stability and performance:
- A Hadoop cluster for Cube building; This can be a shared, large cluster.
- A HBase cluster for SQL queries; Usually this is a dedicated cluster with less nodes. The HBase configurations can be tuned for better read performance as Cubes are immutable after built.
This deployment has been adopted and verified by many large companies. It is the best solution for production deployment as we know. For how to do this, please refer to Deploy Apache Kylin with Standalone HBase Cluster