How to debug Kylin in IDEA with Hadoop
Background
Why debug Kylin in IDEA using docker
This article aims to introduce a simple and useful way to develop and debug Kylin for developers and provided a similar deployment to the user's real scenario.
Deployment architecture
Following is the architecture of the current deployment.
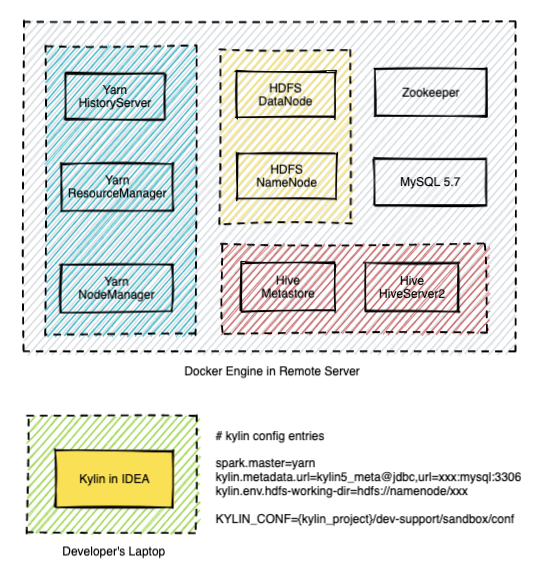
This guide assumes you have prepared the following things:
- A laptop with macOS installed to do development work (Windows is not verified at the moment)
- A remote Linux server for testing and deployment purposes (if you do not prepare a remote Linux server, you will deploy Hadoop on your laptop)
- Kaylin's source code is cloned into some directory on your laptop
For Windows dev machine, setup the Kylin dev env in Windows Subsystem for Linux is the best option. Follow this guide on how to install WSL with GUI, and install both the Kylin code and your favorite IDE (but not the docker) in WSL for best performance.
Prepare IDEA and build source code
Step 1: Check Software Requirement
Please visit software_requirement, and make sure your laptop has met the requirement.
Step 2: Build source code
- Build backend source code before your start debugging.
cd <path-to-kylin-source>
mvn clean install -DskipTests
- Build front-end source code. (Please use node.js v16.20.2, for how to use a specific version of node.js, please check how to switch to a specific node js )
cd kystudio
npm install
Step 3: Install IntelliJ IDEA and build the source
-
Install the IDEA Community edition (the Ultimate edition is ok too).
-
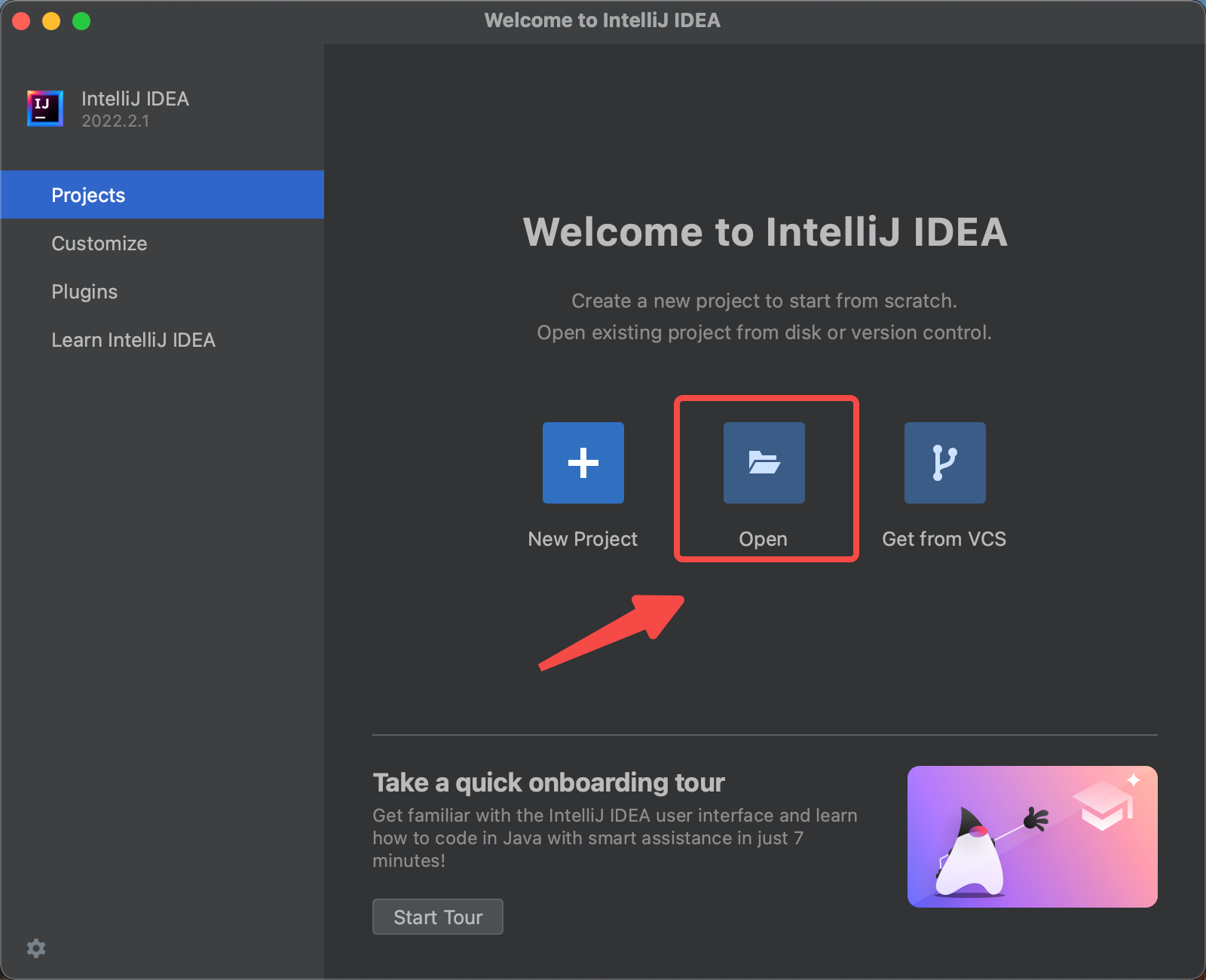
Import the source code into IDEA. Click the Open, and choose the directory of Kylin source code.
-
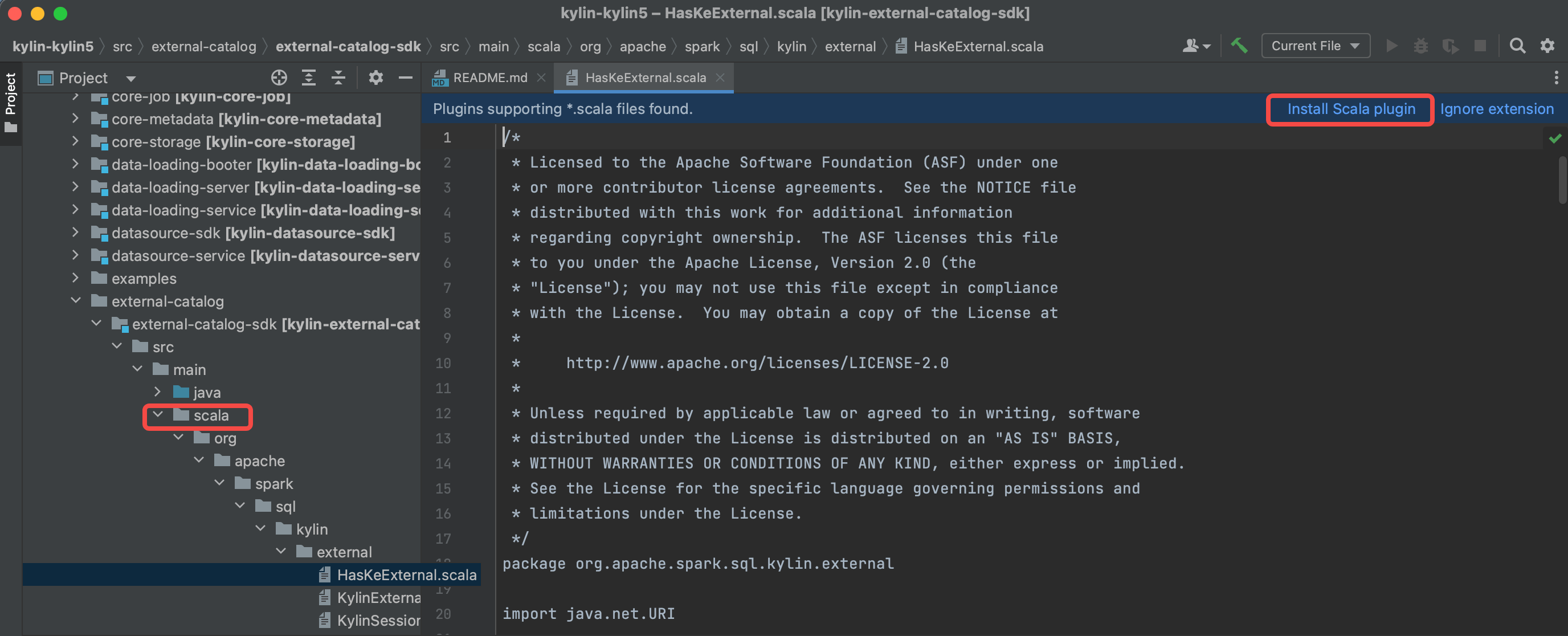
Install the scala plugin and restart
-
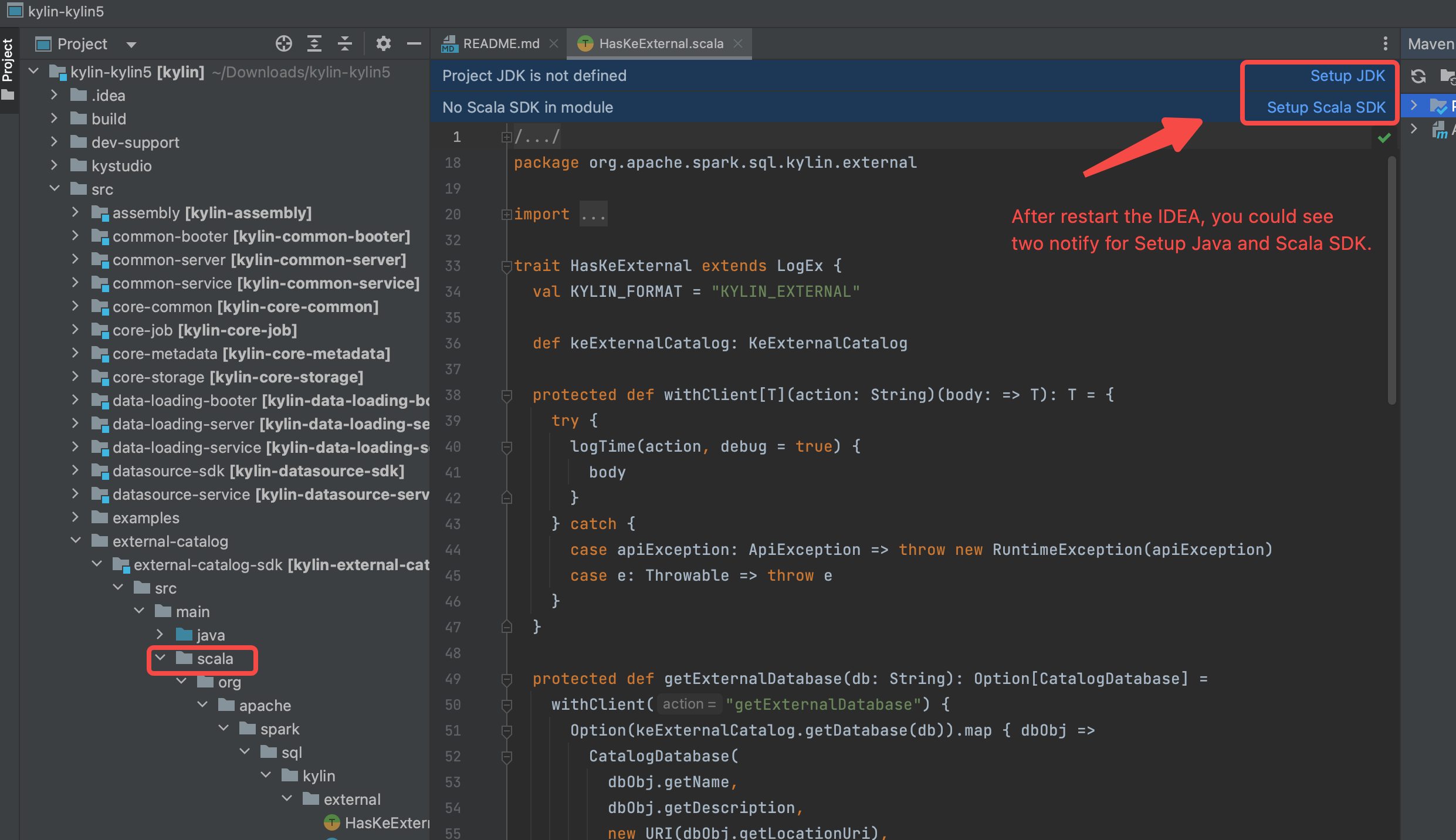
Configure SDK(JDK and Scala), and make sure you use JDK 1.8.X and Scala 2.12.X.
-
Reload maven projects, and the
scaladirectory will be marked as source root(in blue color).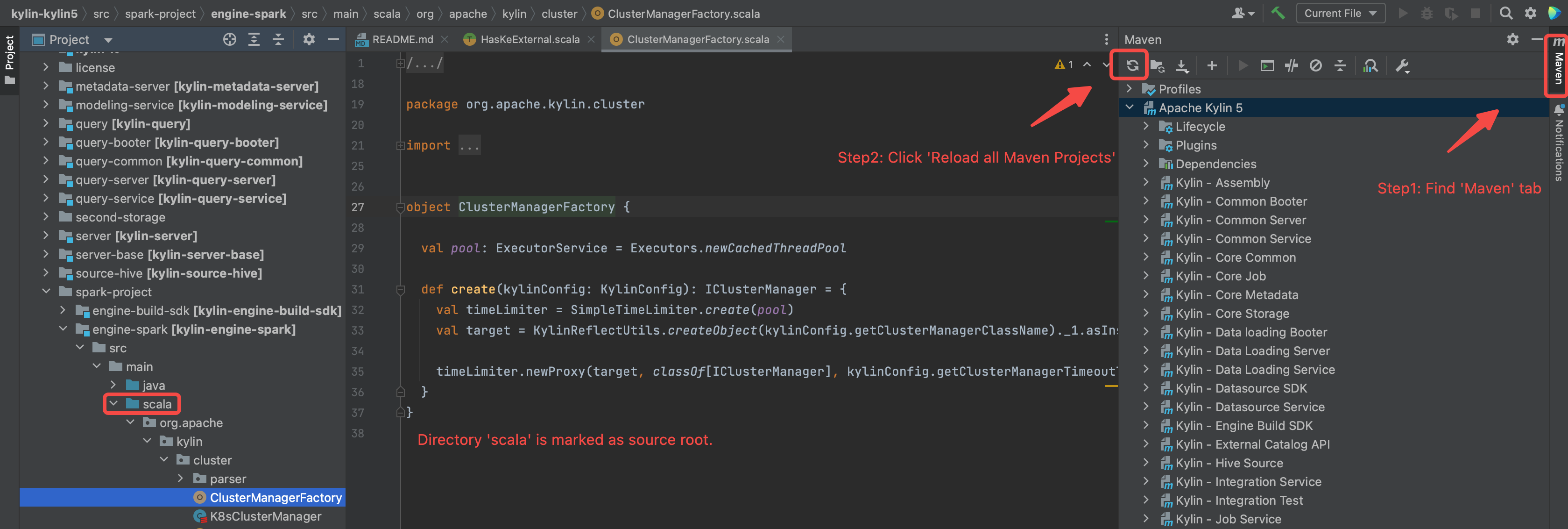
-
Build the projects.(make sure you have executed
mvn clean package -DskipTests, otherwise some source code is not generated by maven javacc plugin)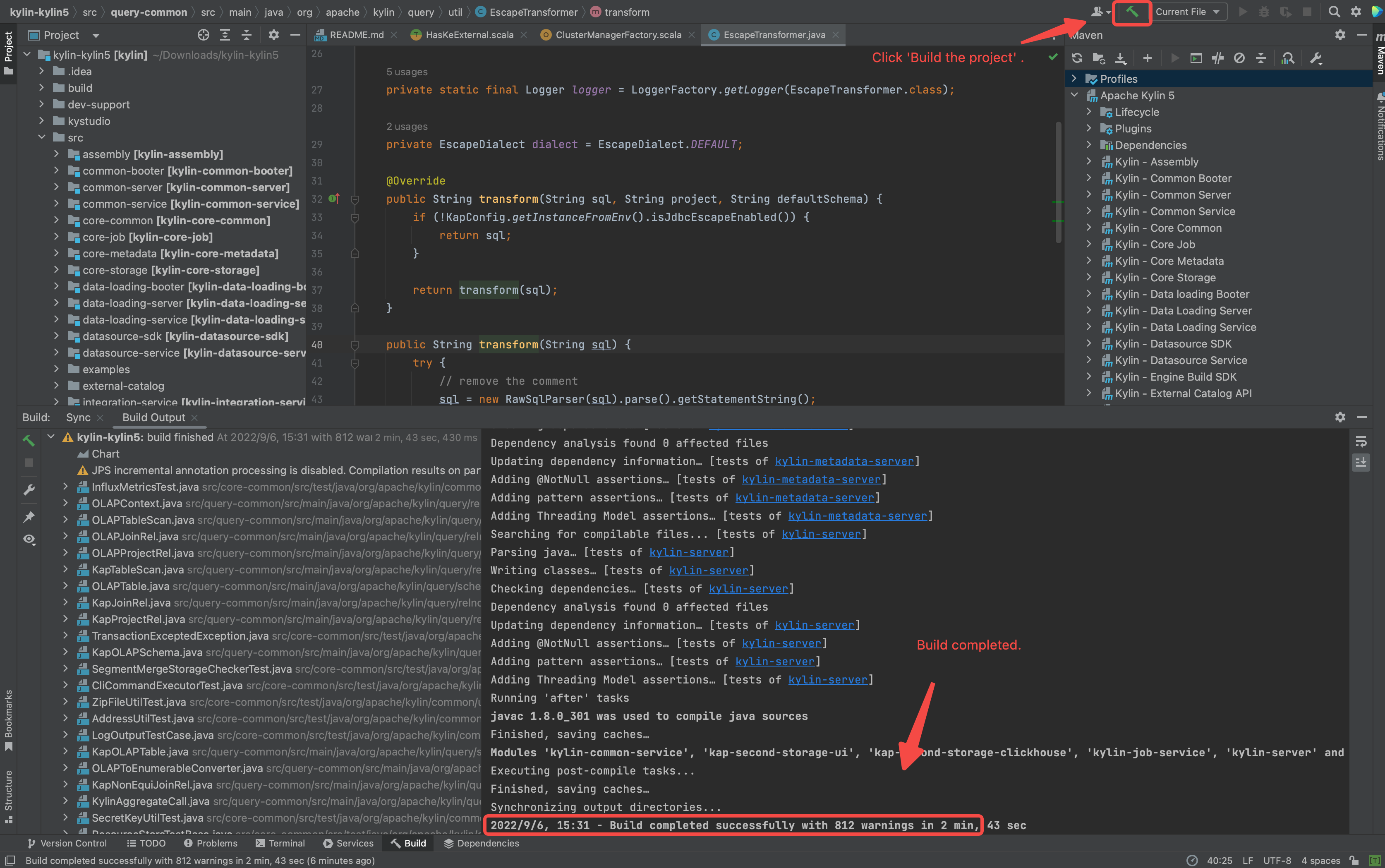
Step 4: Prepare IDEA configuration
- Download spark and create running IDEA configuration for debug purpose.
./dev-support/sandbox/sandbox.sh init
Following is the shell output.
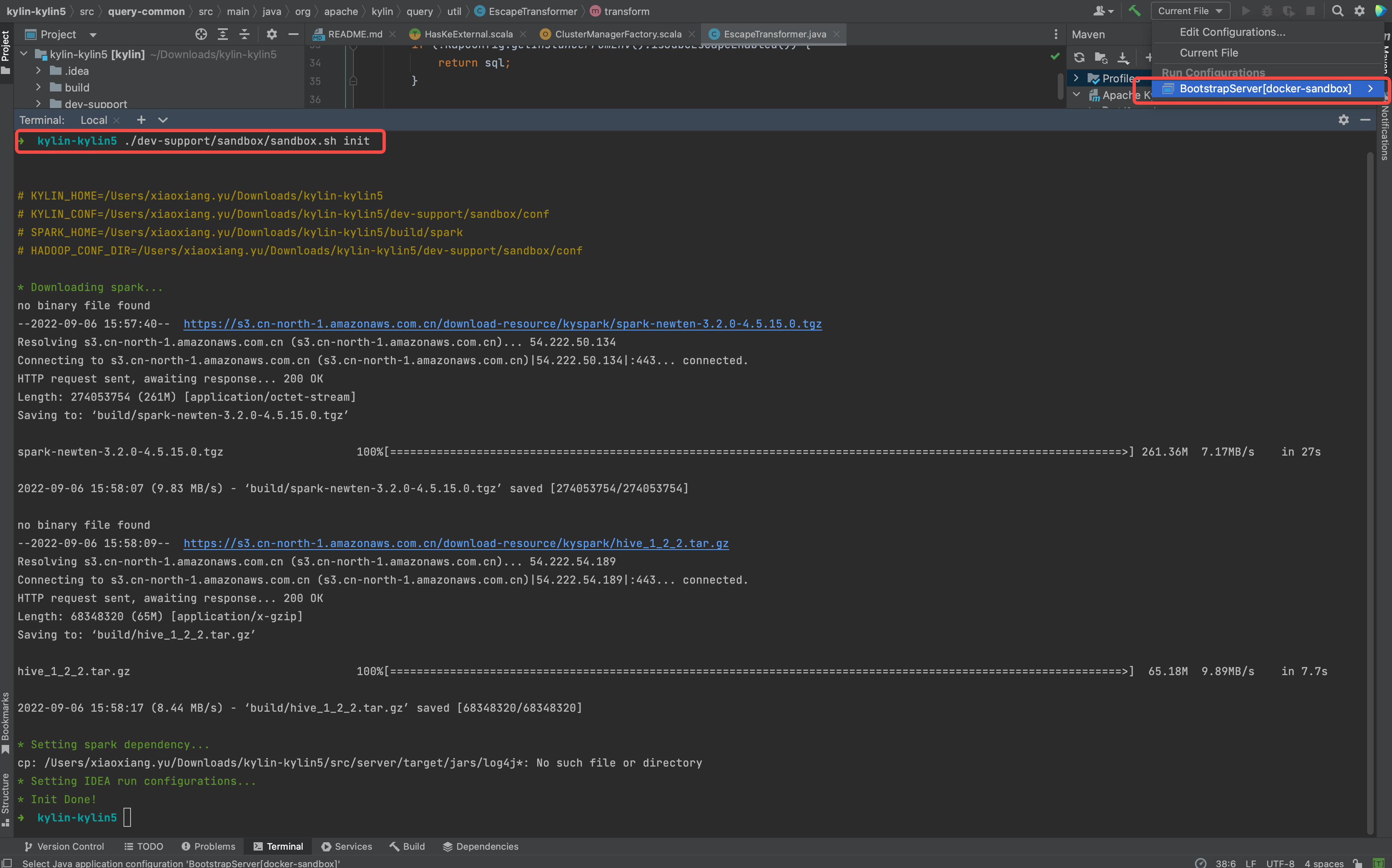
Prepare the Hadoop Cluster
Deploy Hadoop Cluster
- Install latest docker desktop in your laptop
- [Optional] Install docker engine on remote machine (https://docs.docker.com/engine/install/)
It is recommended to use remote server other than laptop to deploy Hadoop Cluster, because 7-8 containers may consume a lot of hardware resources and cause your laptop run slower than before.
- [Optional] If you want to deploy hadoop cluster on remote machine, please set correct
DOCKER_HOST.
If you don't set DOCKER_HOST, you will deploy Hadoop Cluster in your laptop. (Make sure you can log in this server via SSH without input password each time by ssh-copy-id.)
# see more detail at : https://docs.docker.com/compose/reference/envvars/#docker_host
export DOCKER_HOST=ssh://${USER}@${DOCKER_HOST}
- Check available resource of your docker desktop in laptop (or docker engine in remote server, depends on which machine you want to deploy Hadoop Cluster), make sure you leave 6 CPUs and 12 GB memory at least .
Following is the setting page of Docker Desktop of MacBook.
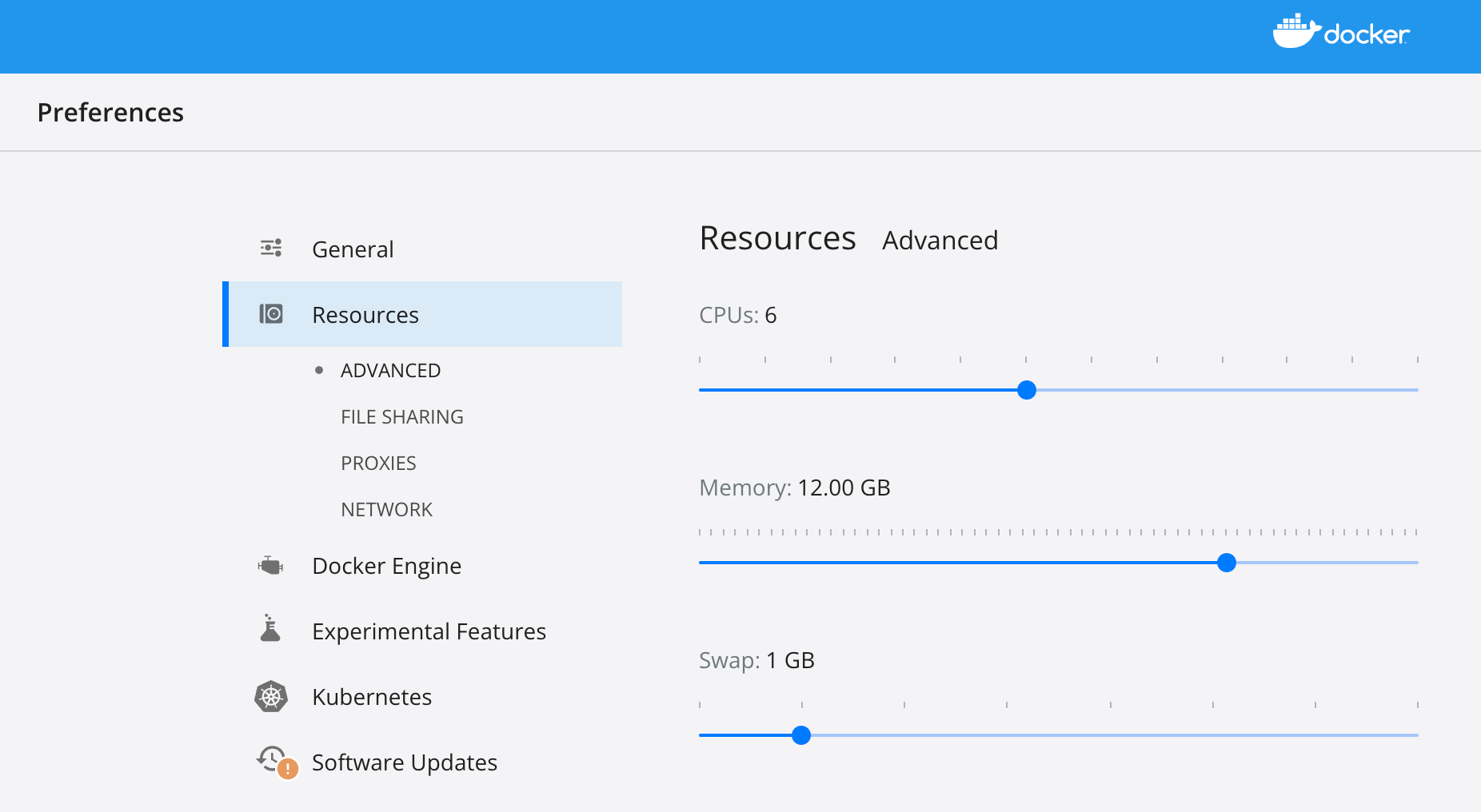
- Deploy hadoop cluster via docker compose on laptop(or on remote machine)
./dev-support/sandbox/sandbox.sh up
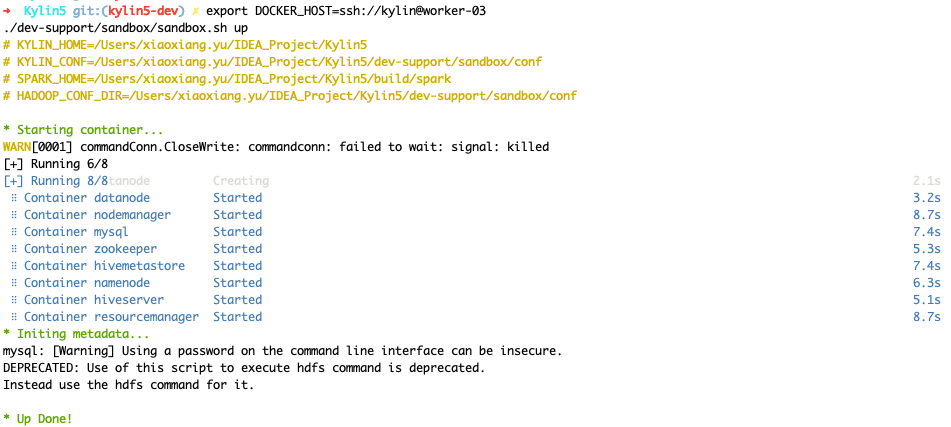
Check status of hadoop cluster
- Wait 2-5 minutes, check health of hadoop, you can use following command to check status
./dev-support/sandbox/sandbox.sh ps
Following output content shows all hadoop component are in health state.
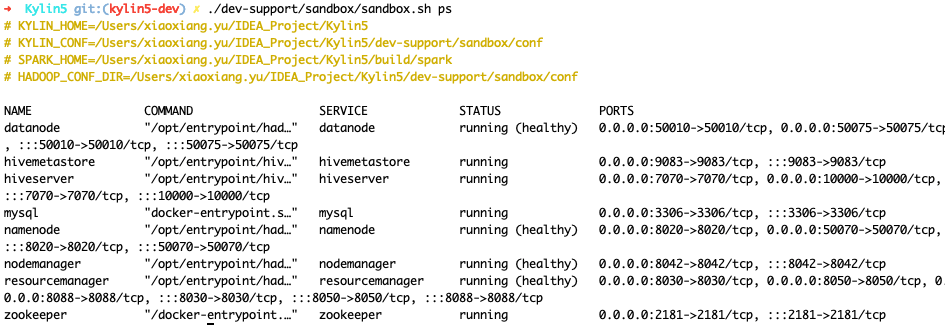
- Edit
/etc/hosts. (if you deployed Hadoop cluster on remote machine, please use correct ip address other than127.0.0.1.)
127.0.0.1 namenode datanode resourcemanager nodemanager historyserver mysql zookeeper hivemetastore hiveserver
- Load sample SSB data into HDFS and Hive
./dev-support/sandbox/sandbox.sh sample
- Check hive table
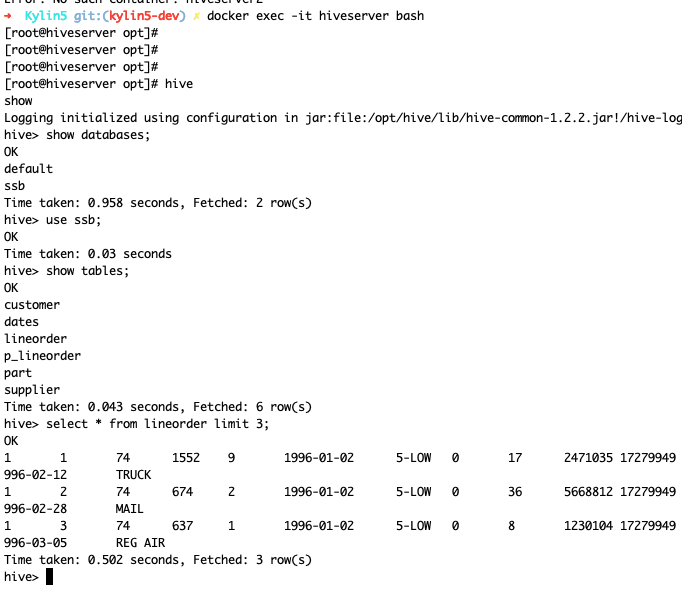
Debug Kylin in IDEA
Start backend in IDEA
- Select "BootstrapServer[docker-sandbox]" on top of IDEA and click Run .
![click BootstrapServer[docker-sandbox]](/assets/images/RUN_KYLIN_IN_IDEA-d961f3f345c5f8bb3267d3f30f6e23ac.png)
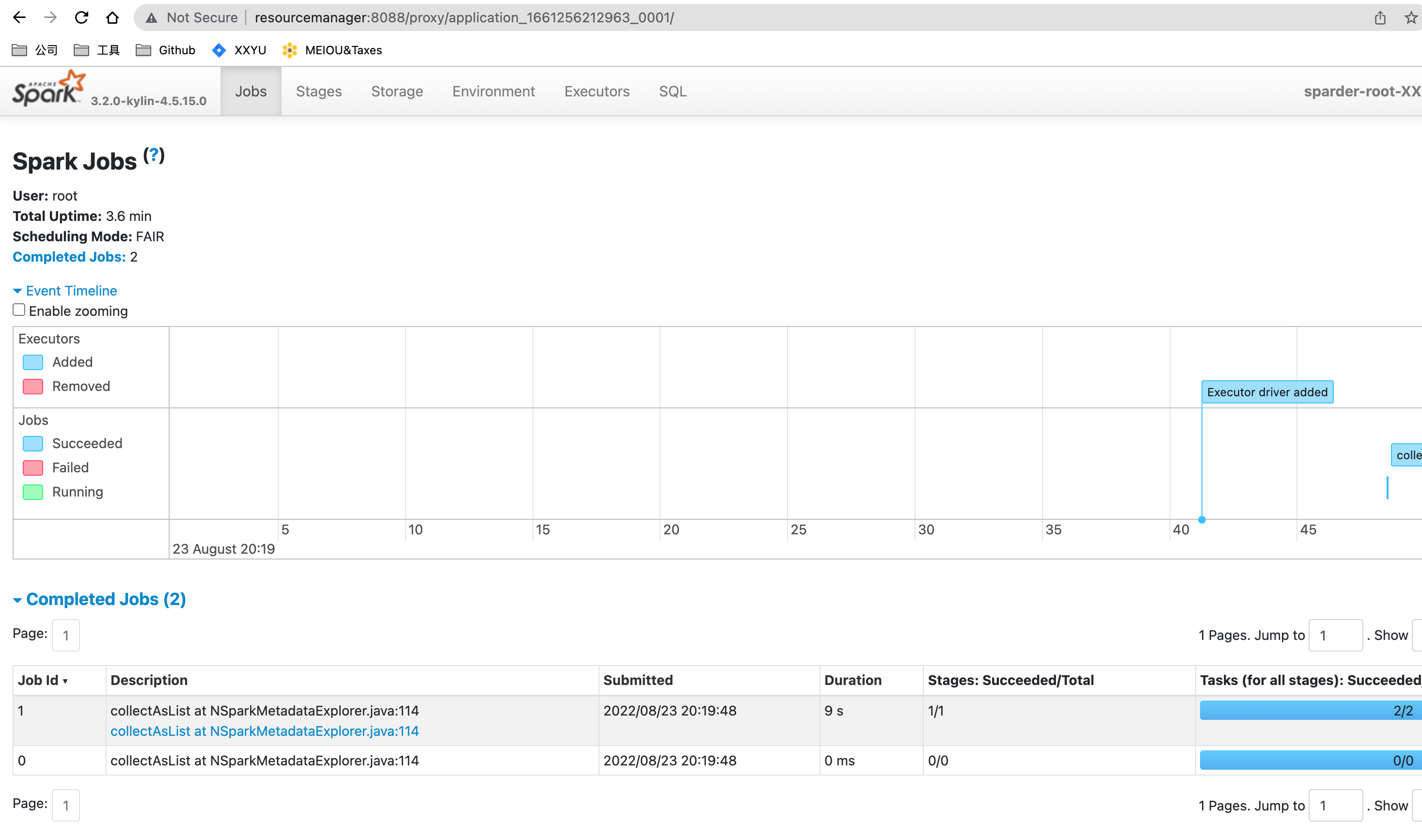
- Wait and check if Sparder is start succeed.
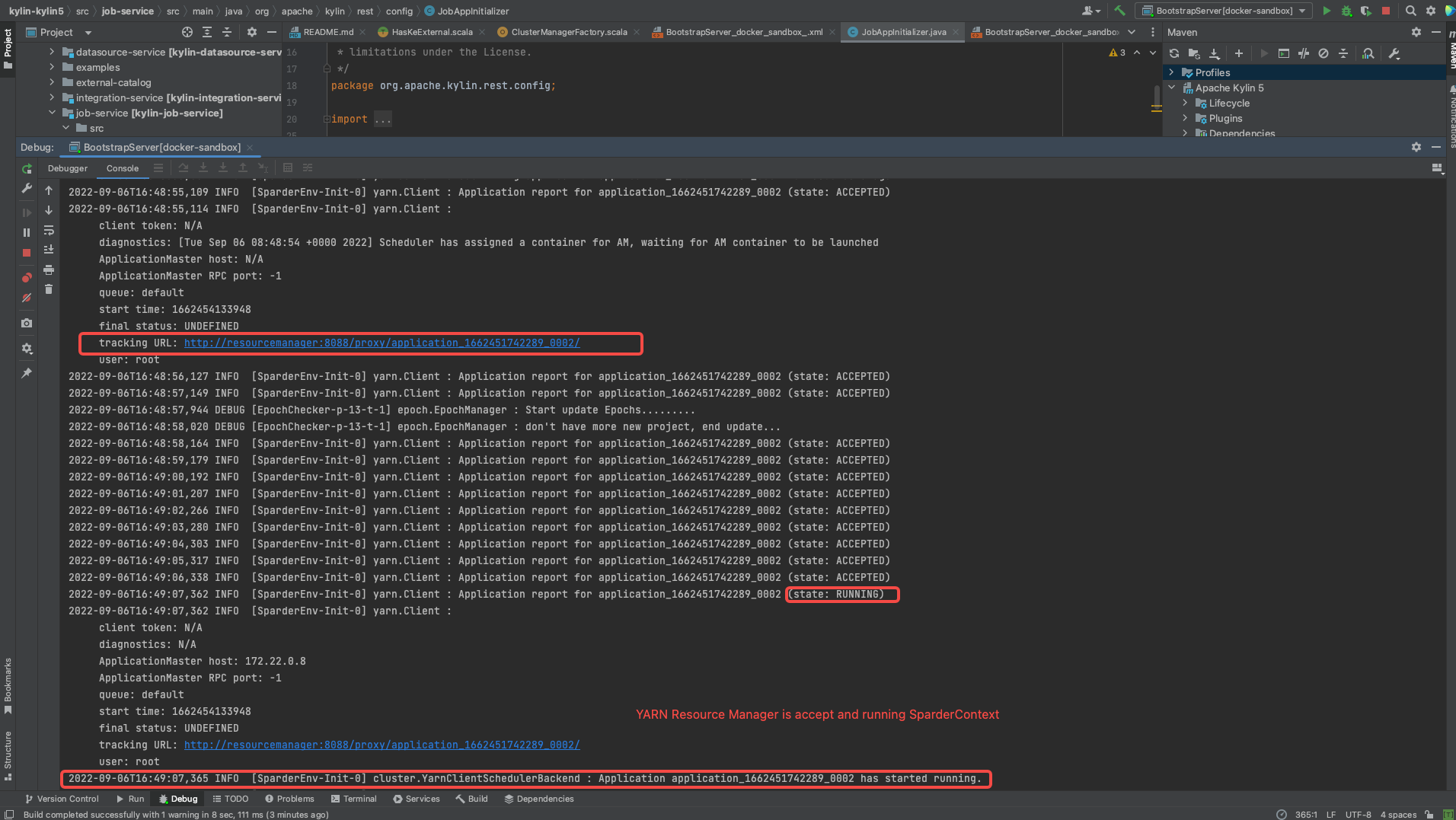
- Check if SparkUI of Sparder is started.
Start frontend in IDEA
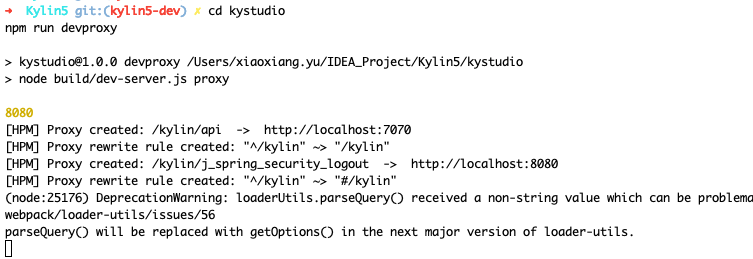
- Set up dev proxy
cd kystudio
npm run devproxy
Validate Kylin's core functions
- Visit Kylin WEB UI in your laptop
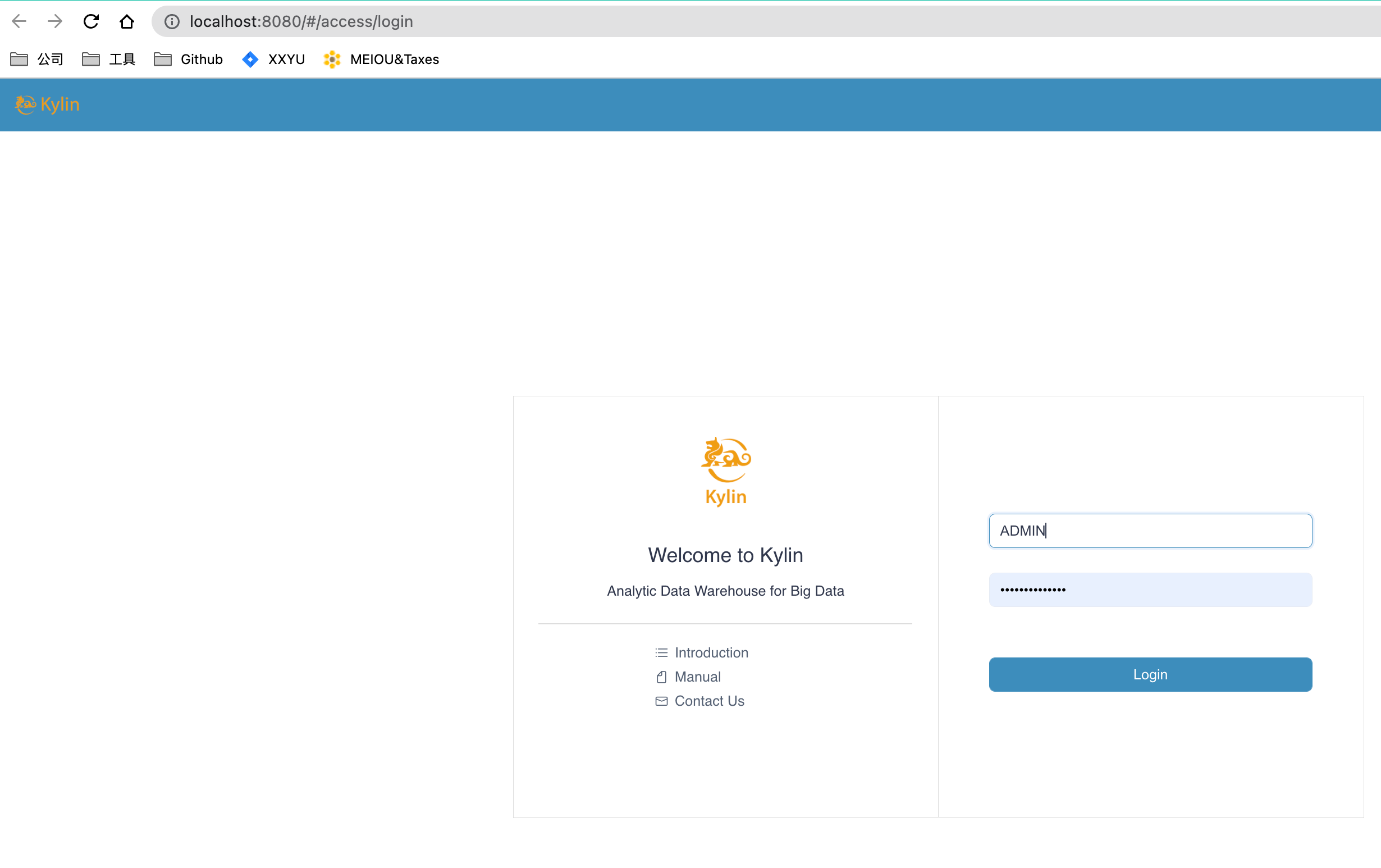
-
Create a new project, load table and create model
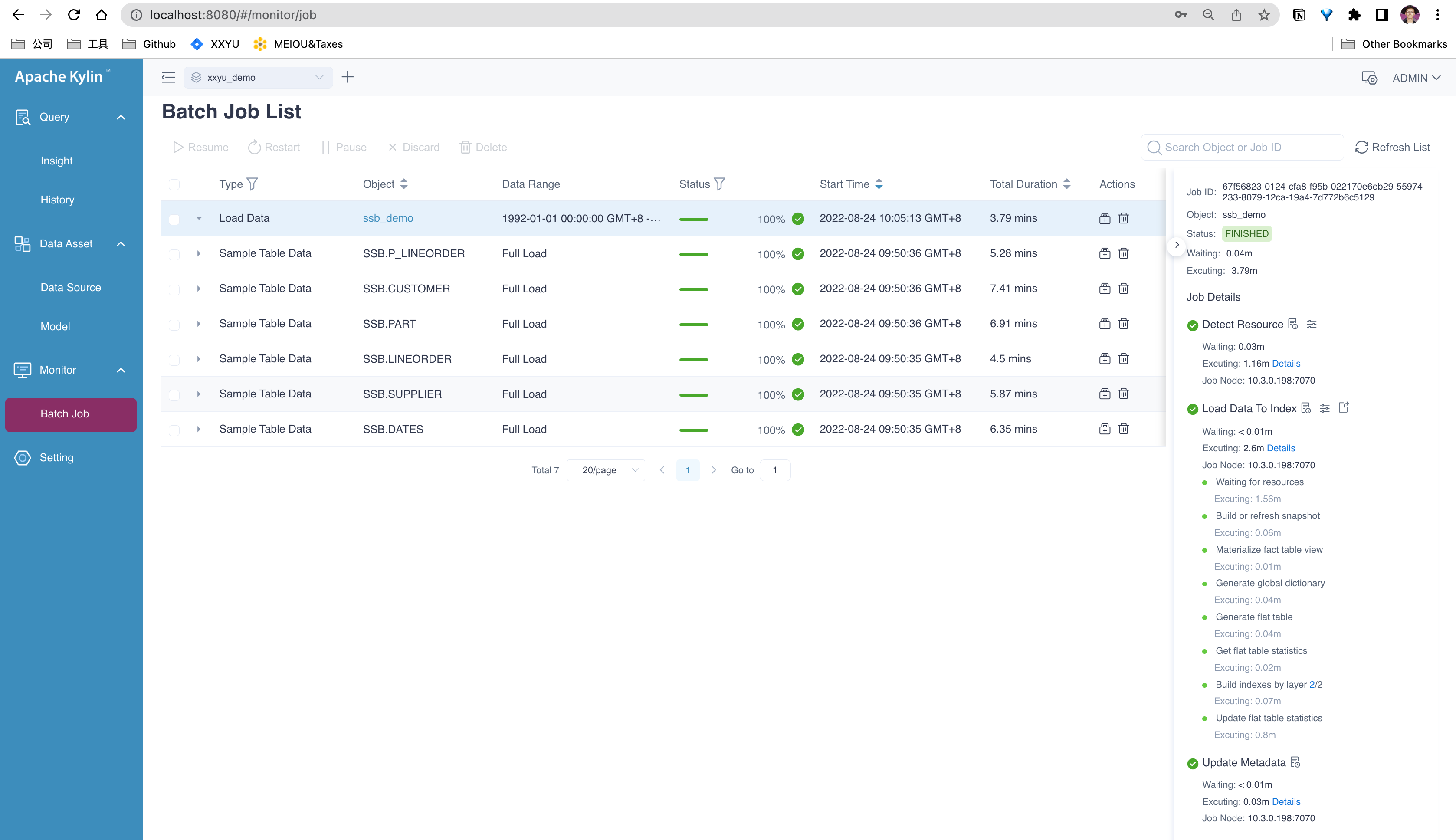
-
Validate Cube Build and Query function
Command manual
- Use
./dev-support/sandbox/sandbox.sh stopto stop all containers - Use
./dev-support/sandbox/sandbox.sh startto start all containers - Use
./dev-support/sandbox/sandbox.sh psto check status of all containers - Use
./dev-support/sandbox/sandbox.sh downto stop all containers and delete them
Q&A
// todo