Hadoop Queue
In a multi-tenant environment, sharing a large cluster securely requires each tenant to have allocated resources in a timely manner, within the constraints of their allocated capacities. To achieve this, each Kylin instance or project can be configured to utilize a separate YARN queue, enabling efficient computing resource allocation and separation.
Instance-level YARN Queue Setting
To achieve this, first create a new YARN capacity scheduler queue. By default, the job sent out by Kylin will go to the default YARN queue.
In the screenshot below, a new YARN queue learn_kylin has been set up.
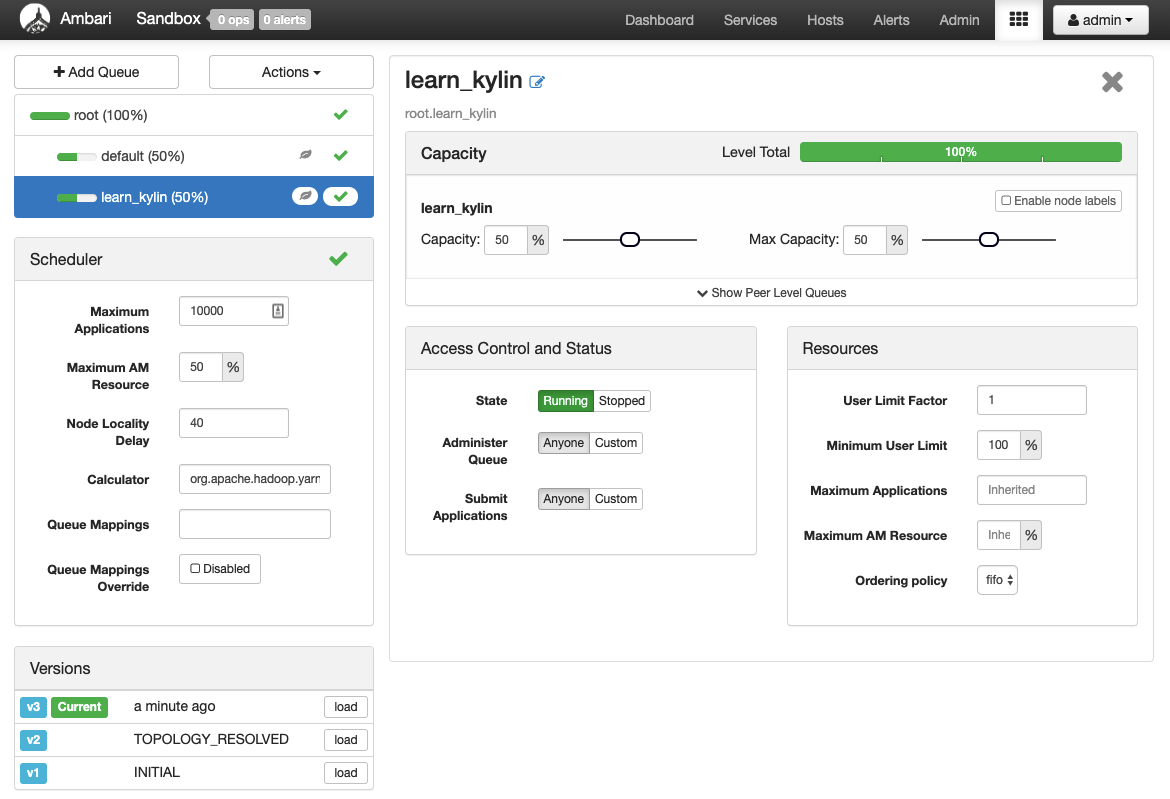
To configure the YARN queue used in Kylin, modify the kylin.properties file by replacing YOUR_QUEUE_NAME with the name of your YARN queue. This setting applies to both building and querying operations.
### Building configuration
kylin.engine.spark-conf.spark.yarn.queue=YOUR_QUEUE_NAME
### Querying configuration
kylin.storage.columnar.spark-conf.spark.yarn.queue=YOUR_QUEUE_NAME

In this example, the queue for querying has been changed to learn_kylin (as shown above). You can test this change by triggering a querying job.
Now, go to YARN Resource Manager on the cluster. You will see this job has been submitted under queue learn_kylin.
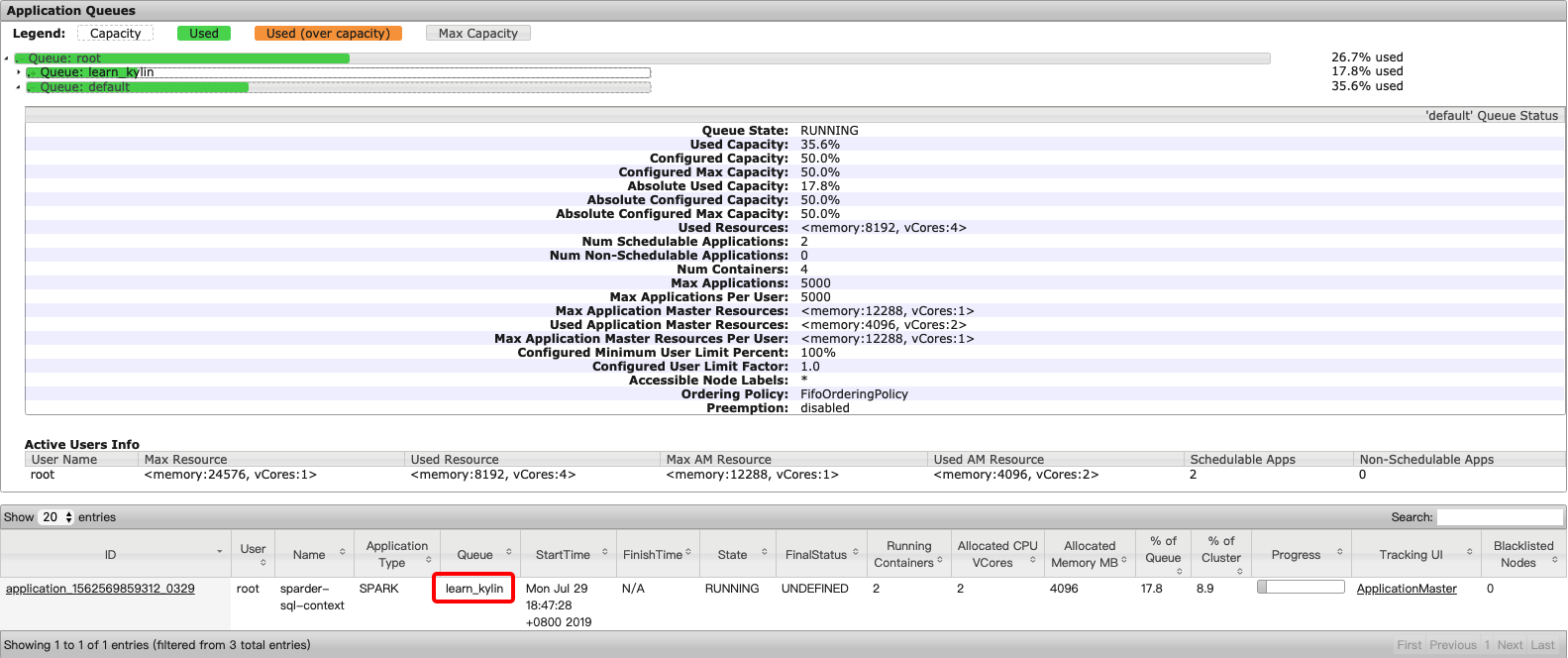
Similarly, you may set up YARN queue for other Kylin instances to achieve computing resource separation.
Project-level YARN Queue Setting
The system admin user can set the YARN Application Queue of the project in Setting -> Advanced Settings -> YARN Application Queue, please refer to the Project Settings for more information.