
How Meituan Dominates Online Shopping with Apache Kylin
Let’s face it, online shopping now affects nearly every part of our shopping lives. From ordering groceries to purchasing a car, we’re living in an age of limitless choices when it comes to online commerce. Nowhere is this more the case than with the world’s 2nd largest consumer market: China.
Leading the online shopping revolution in China is Meituan, who since 2016 has grown to support nearly 460 million consumers from over 2,000 industries, regularly processing hundreds of $billions in transactions. To support these staggering operations, Meituan has invested heavily in its data analytics system and employs more than 10,000 engineers to ensure a stable and reliable experience for their customers.
But the driving force behind Meituan’s success is not simply a robust analytics system. While the organization’s executives might think so, its engineers understand that it is the OLAP engine that system is built upon that has empowered the company to move quickly and win in the market.
Meituan’s Secret Weapon: Apache Kylin
Since 2016, Meituan’s technical team has relied on Apache Kylin to power their OLAP engine. Apache Kylin, an open source OLAP engine built on the Hadoop platform, resolves complex queries at sub-second speeds through multidimensional precomputation, allowing for blazing-fast analysis on even the largest datasets.
However, the limitations of this open source solution became apparent as the company’s business grew, becoming less and less efficient as cubes and queries became larger and more complex. To solve this problem, the engineering team leveraged Kylin’s open source foundations to dig into the engine, understand its underlying principles, and develop an implementation strategy that other organizations using Kylin can adopt to greatly improve their data output efficiency.
Meituan’s technical team has graciously shared their story of this process below so that you can apply it toward solving your own big data challenges.
A Global Pandemic and a New Normal for Business
For the last four years, Meituan’s Qingtian sales system has served as the company’s data processing workhorse, handling massive amounts of daily sales data involving a wide range of highly complex technical scenarios. The stability and efficiency of this system is paramount, and it’s why Meituan’s engineers have made significant investments in optimizing the OLAP engine Qingtian is built upon.
After a thorough investigation, the team identified Apache Kylin as the only OLAP engine that could meet their needs and scale with anticipated growth. The engine was rolled out in 2016 and, over the next few years, Kylin played an important role in the company’s evolving data analytics system.
Growth expectations, however, turned out to be severely underestimated, as a global pandemic quickly drove major changes in how consumers shopped and how businesses sold their goods. Such a massive shift in online shopping led to even faster growth for Meituan as well as a nearly untenable amount of new business data.
This caused efficiency bottlenecks that even their Kylin-based system started to struggle with. Cube building and query performance was unable to keep up with these changes in consumer behaviors, slowing down data analysis and decision-making and creating a major obstacle towards addressing user experiences.
Meituan’s technical team would spend the next six months carrying out optimizations and iterations for Kylin, including dimension pruning, model design, resource adaptation, and improving SLA compliance.
Responding to New Consumer Behaviors with Apache Kylin
In order to understand the approach taken when optimizing Meituan’s data architecture, it’s important to understand how the business is managed. The company’s sales force operates with two business models – in-store sales and phone sales – and is then further broken down by various territories and corporate departments. All analytics data must be communicated across both business models.
With this in mind, Meituan engineers incorporated Kylin into their design of the data architecture as follows:
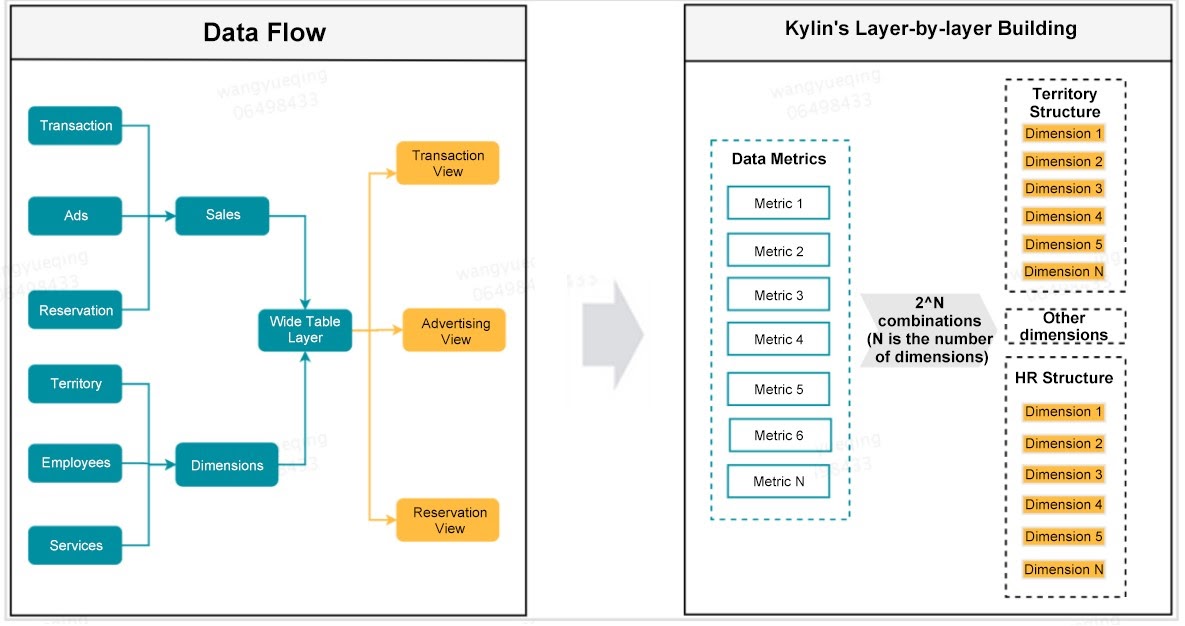
Figure 3. Apache Kylin’s layer-by-layer building data flow
While this design addressed many of Meituan’s initial concerns around scalability and efficiency, continued shifts in consumer behaviors and the organization’s response to dramatic changes in the market put enormous pressure on Kylin when it came to building cubes. This lead to an unsustainable level of consumption of both resources and time.
It became clear that Kylin’s MOLAP model was presenting the following challenges:
- The build process involved many steps that were highly correlated, making it difficult to root cause problems.
- MapReduce - instead of the more efficient Spark - was still being used as the build engine for historical tasks.
- The platform’s default dynamic resource adaption method demanded considerable resources for small tasks. Data was sharded unnecessarily and a large number of small files were generated, resulting in a waste of resources.
- Data volumes Meituan was now having to work with were well beyond the original architectural plan, resulting in two hours of cube building every day.
- The overall SLA fulfillment rate remained lower than expected.
Recognizing these problems, the team set a goal of improving the platform’s efficiency (you can see the quantitative targets below). Finding a solution would involve classifying Kylin’s build process, digging into how Kylin worked under the hood, breaking down that process, and finally implementing a solution.
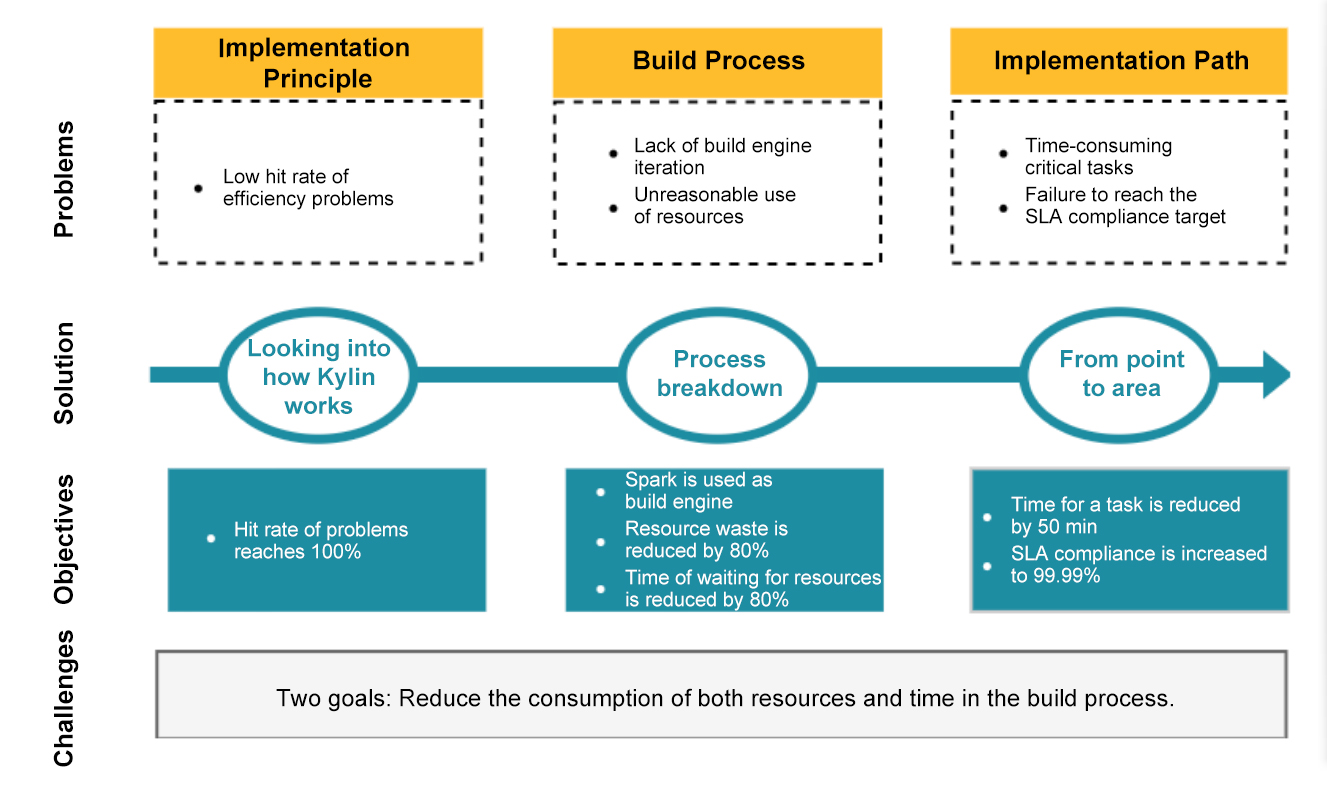
Figure 4. Implementation path diagram
Optimization: Understanding How Apache Kylin Builds Cubes
Understanding the cube building process is critical for pinpointing efficiency and performance issues. In the case of Kylin, a solid grasp of its precomputation approach and its “by layer” cubing algorithm are necessary when formulating a solution.
Precomputation with Apache Kylin
Apache Kylin generates all possible dimensional combinations and pre-calculates the metrics that may be used in future multidimensional analysis, saving the results as a cube. Metric aggregation results are saved on cuboids (a logical branch of the cube), and during queries relevant cuboids are found through SQL statements, and then read and quickly returned as metric values.
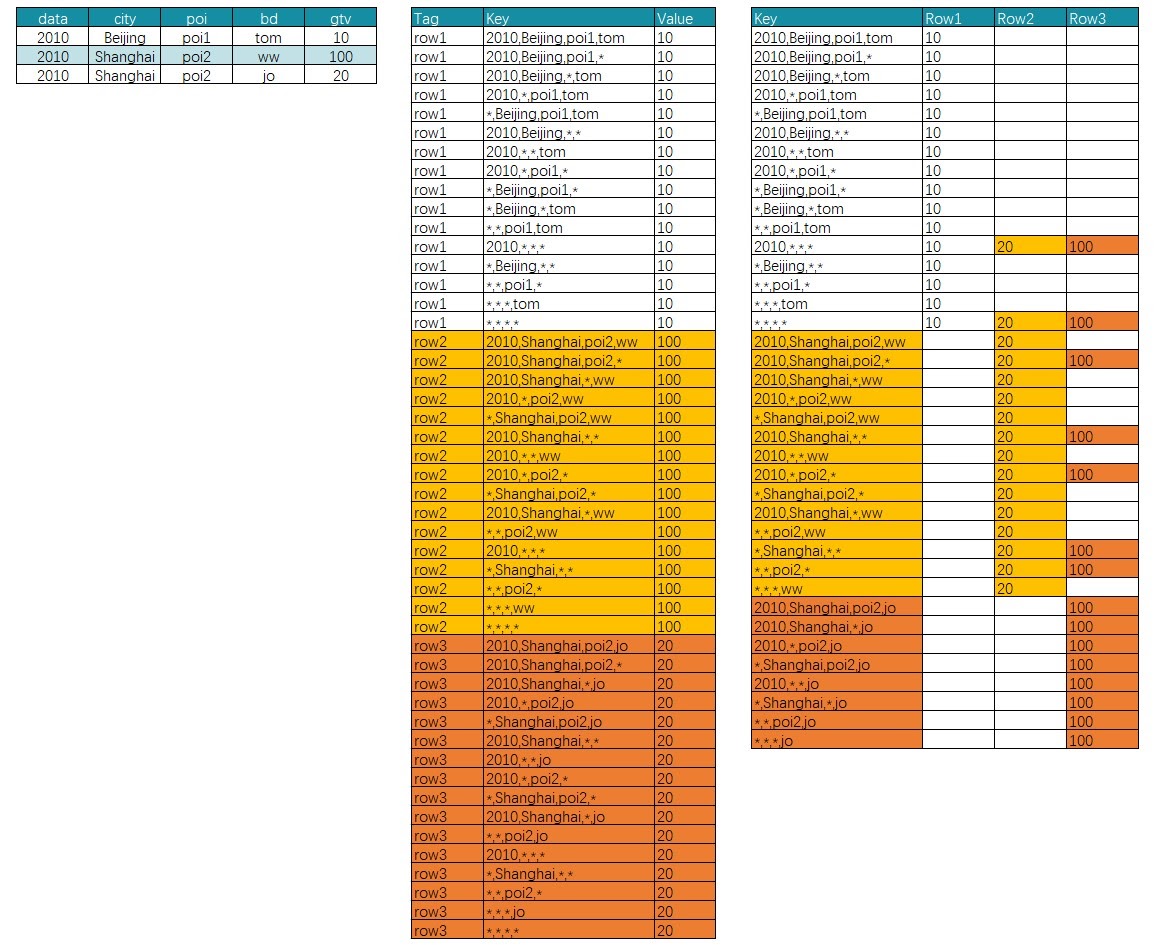
Figure 5. Precomputation across four dimensions example
Apache Kylin’s By-Layer Cubing Algorithm
An N-dimensional cube is composed of 1 N-dimensional sub-cube, N (N-1)-dimensional sub-cubes, N*(N-1)/2 (N-2)-dimensional sub-cubes, …, N 1-dimensional sub-cubes, and one 0-dimensional sub-cube, consisting of a total of 2^N sub-cubes. In Kylin’s by-layer cubing algorithm, the number of dimensions decreases with the calculation of each layer, and each layer’s calculation is based on the calculation result of its parent layer (except the first layer, which bases it on the source data).
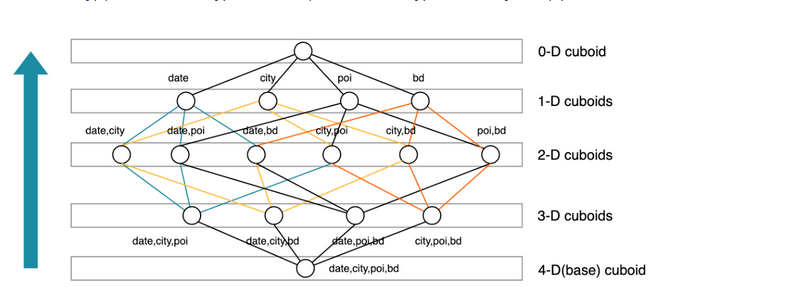
Figure 6. Cuboid example
The Proof Is in the Process
Understanding the principles outlined above, the Meituan team identified five key areas to focus on for optimization: engine selection, data reading, dictionary building, layer-by-layer build, and file conversion. Addressing these areas would lead to the greatest gains in reducing the required resources for calculation and shortening processing time.
The team outlined the challenges, their solutions, and key objectives in the following table:
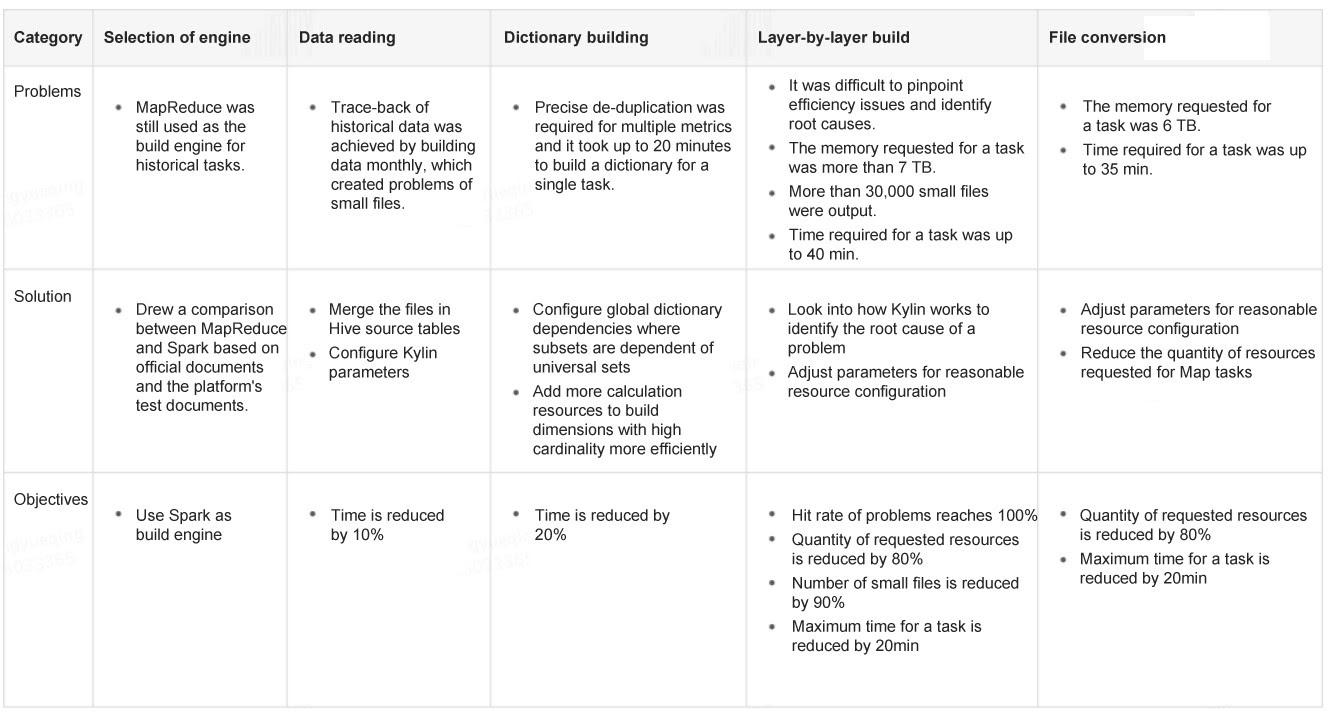
Figure 7. Breakdown of Apache Kylin’s process
Putting Apache Kylin to the Test
With their solutions in place, the next step was to test if Kylin’s build process had actually improved. To do this, the team selected a set of critical sales tasks and ran a pilot (outlined below):
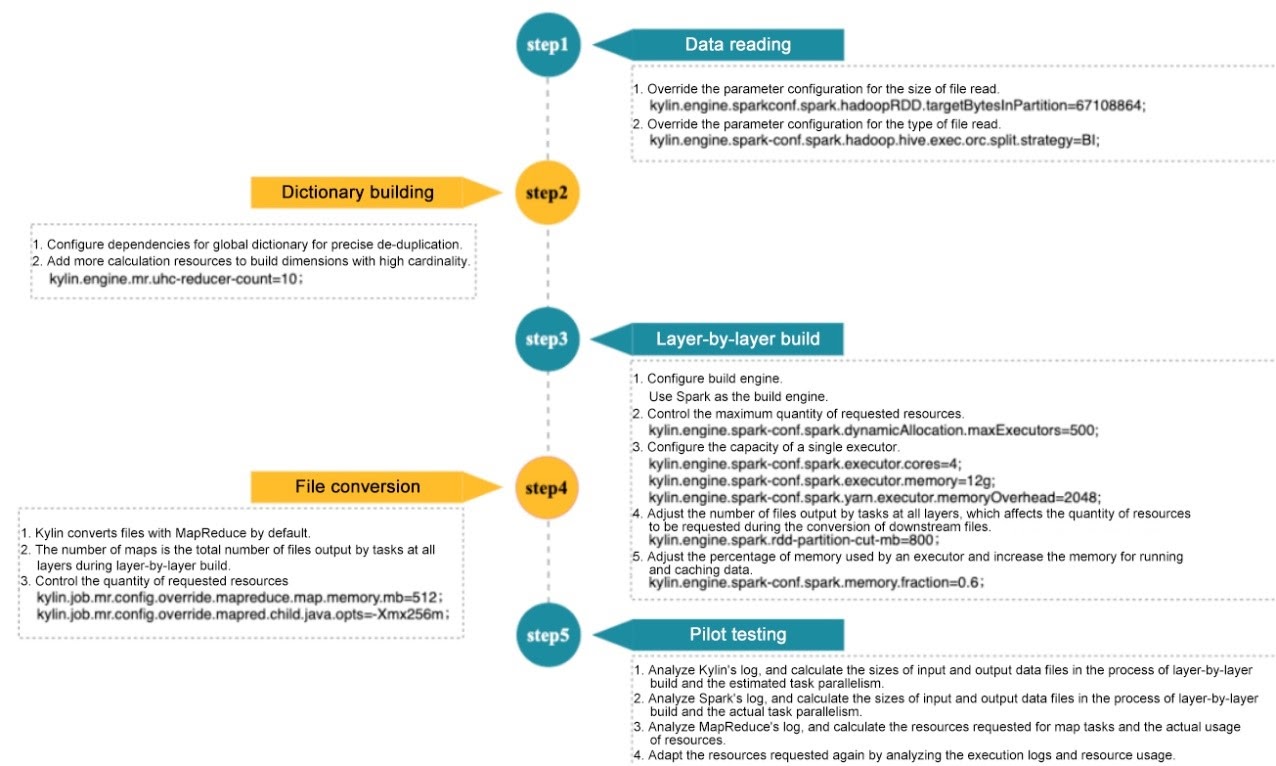
Figure 8. Meituan’s pilot program for their Apache Kylin optimizations
The results of the pilot were astonishing. Ultimately, the team was able to realize a significant reduction in resource consumption as seen in the following chart:
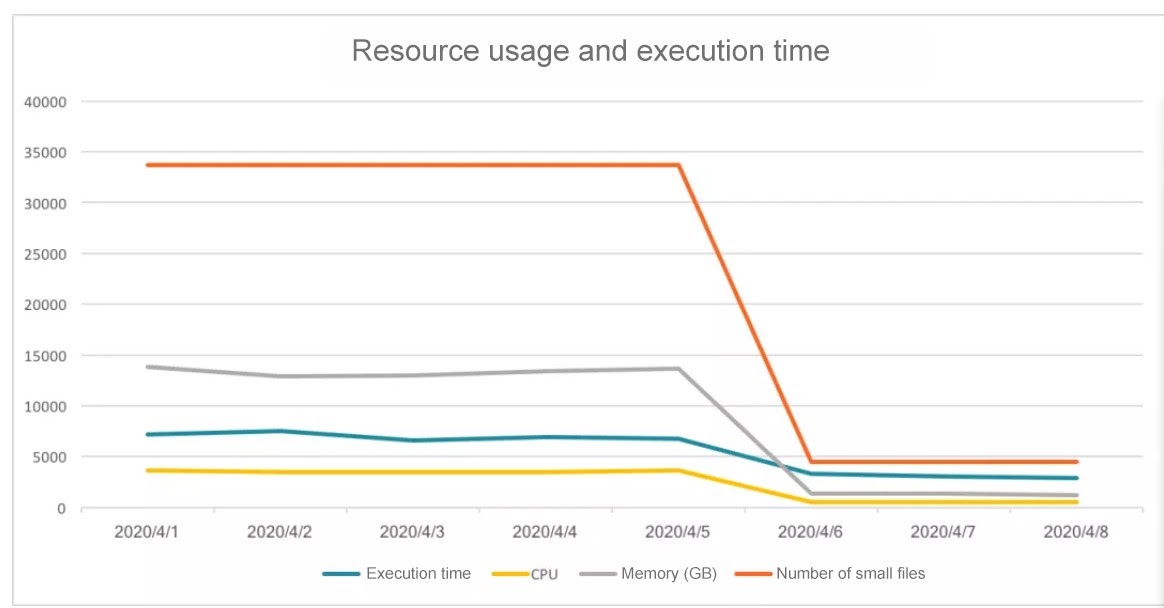
Figure 9. Resource usage and performance of Apache Kylin before and after pilot
Analytics Optimized
Today, Meituan’s Qingtian system is processing over 20 different Kylin tasks, and after six months of constant optimization, the monthly CU usage for Kylin’s resource queue and the CU usage for pending tasks have seen significant reductions.
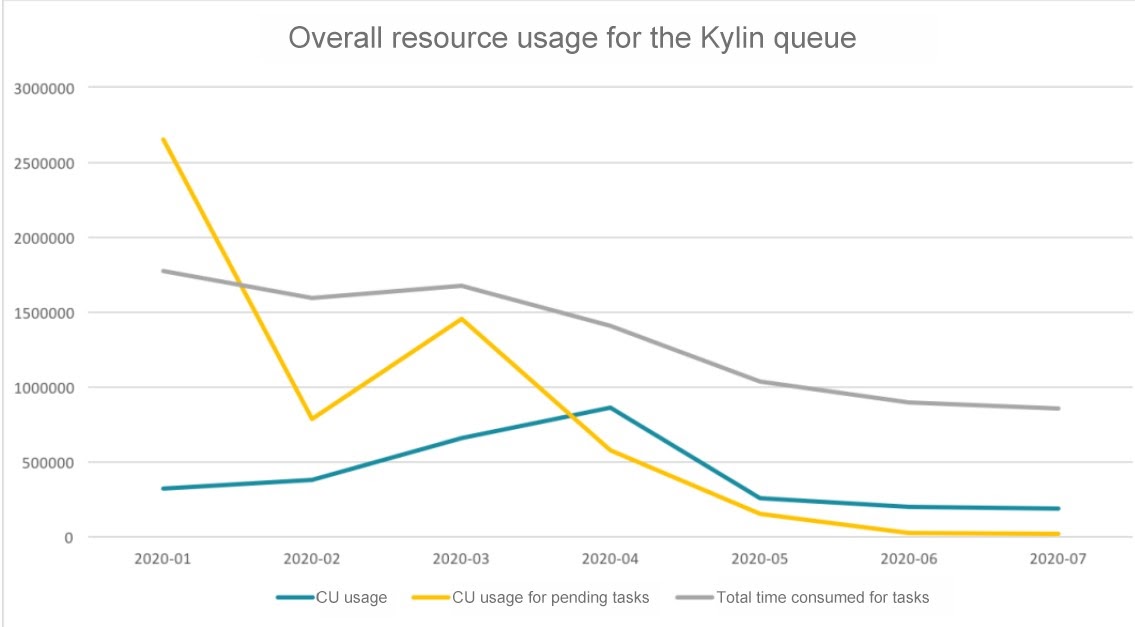
Figure 10. Current performance of Apache Kylin after solution implementation
Resource usage isn’t the only area of impressive improvement. The Qingtian system’s SLA compliance also was able to reach 100% as of June 2020.
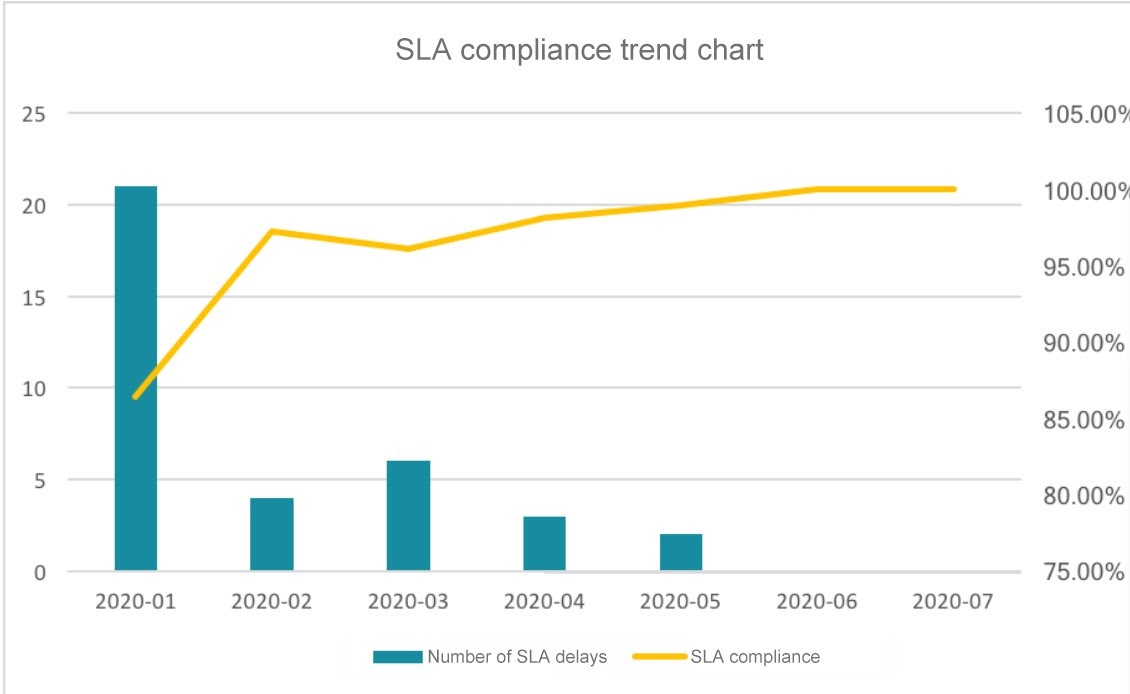
Figure 11. Meituan SLA compliance after Apache Kylin optimization
Taking on the Future with Apache Kylin
Over the past four years, Meituan’s technical team has accumulated a great deal of experience in optimizing query performance and build efficiency with Apache Kylin. But Meituan’s success is also the story of open source’s success.
The Apache Kylin community has many active and outstanding code contributors (including Kyligence), who are relentlessly working to expand the Kylin ecosystem and add more new features. It’s in sharing success stories like this that Apache Kylin is able to remain the leading open source solution for analytics on massive datasets.
Together, with the entire Apache Kylin community, Meituan is making sure critical analytics work can remain unburdened by growing datasets, and that when the next major shift in business takes place, industry leaders like Meituan will be able to analyze what’s happening and quickly take action.