
Apache kylin4 新架构分享
这篇文章主要分为以下几个部分:
- Apache Kylin 使用场景
- Apache Kylin 基本原理
- Apache Kylin 查询基本流程
- Kylin On HBase
- Kylin On Parquet
01 Apache Kylin 使用场景
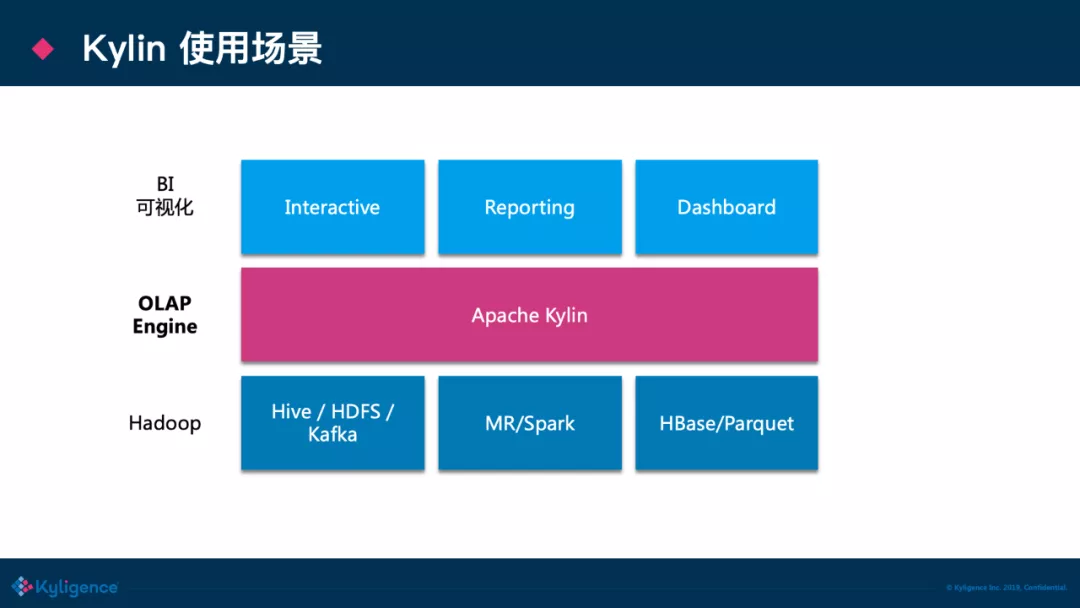
Apache Kylin™ 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay Inc 开发并贡献至开源社区,它能在亚秒内查询巨大的 Hive 表。
作为一个 SQL 加速层,Kylin 可以下接各种数据源,例如 Hive/Kafka,上接各种 BI 系统,比如 Tableau,PowerBI,也可以直接进行 Ad hoc 的查询。
如果你们的产品/业务方找到你,说有一批查询太慢了希望能够加速,要求查询速度要快;查询并发要高;资源占用要少;完整支持 SQL 语法并且能够无缝集成 BI,然后又没有更多的机器给你,那么这个时候你可以考虑使用 Apache Kylin。
02 Apache Kylin 基本原理
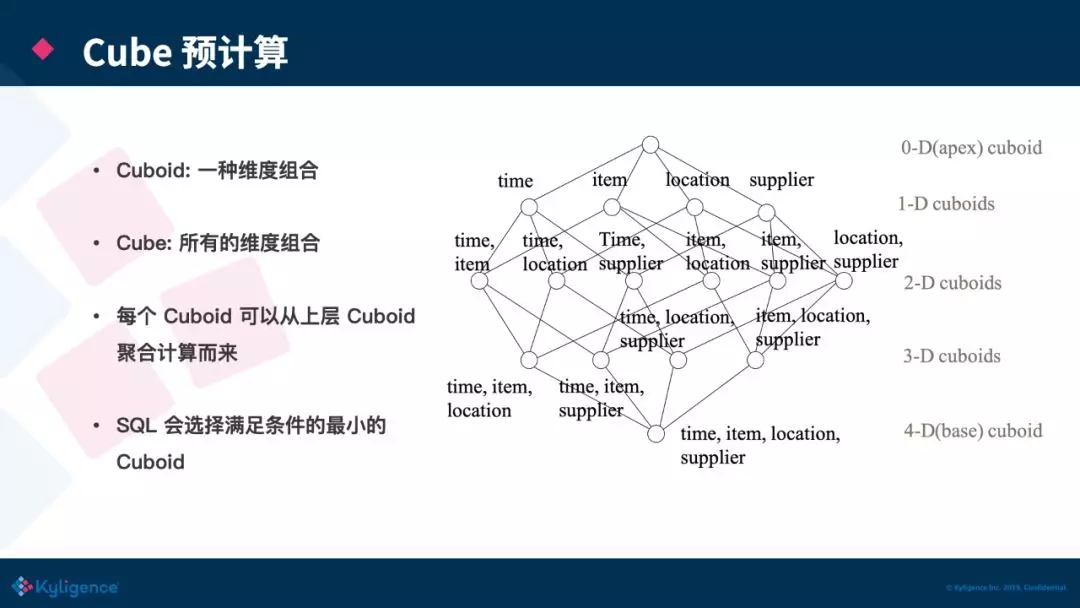
Kylin 的核心思想是预计算,将数据按照指定的维度和指标,预先计算出所有可能的查询结果,利用空间换时间来加速查询模式固定的 OLAP 查询。
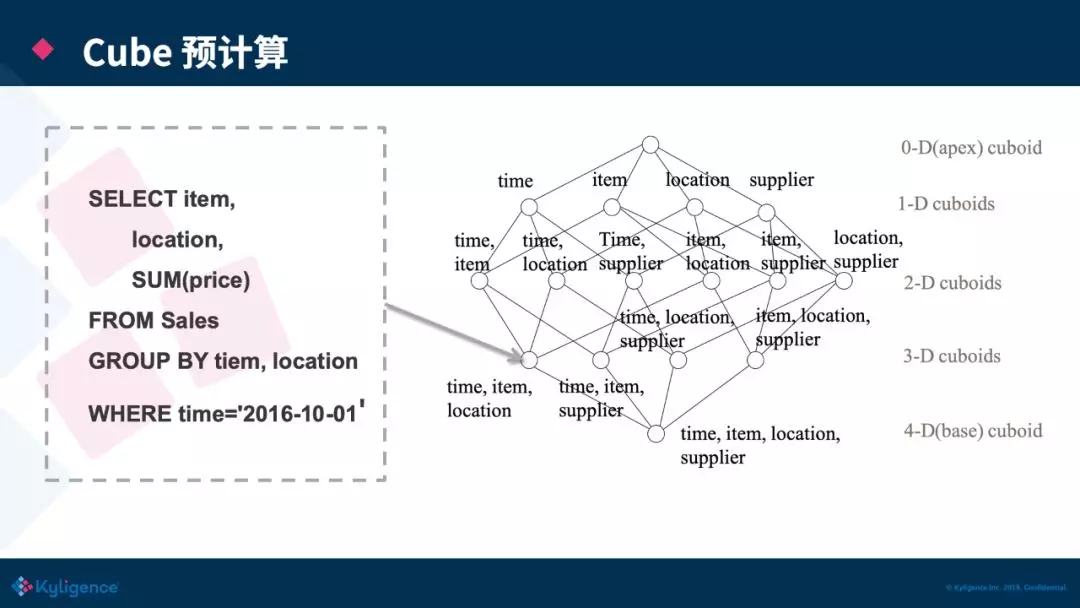
Kylin 的理论基础是 Cube 理论,每一种维度组合称之为 Cuboid,所有 Cuboid 的集合是 Cube。其中由所有维度组成的 Cuboid 称为 Base Cuboid,图中(time,item,location,supplier)即为 Base Cuboid,所有的 Cuboid 都可以基于 Base Cuboid 计算出来。Cuboid 我们可以理解为就是一张预计算过后的大宽表,在查询时,Kylin 会自动选择满足条件的最合适的 Cuboid,比如上图的查询就会去找Cuboid(time,item,location),相比于从用户的原始表进行计算,从 Cuboid 取数据进行计算能极大的降低扫描的数据量和计算量。
03 Apache Kylin 查询基本流程

下面来简单介绍下 Kylin 查询的基本原理,前三步是所有 Query engine 的常规操作,我们这边借助了 Apache Calcite 框架来完成这个操作,网上相关的资料有很多这里不做过多展开,感兴趣的读者可以自行查阅。
这边介绍重点在最后两步:Kylin 适配和 Query 执行。为什么要做 Kylin 适配?因为我们前面得到的查询计划是直接根据用户的查询转化来的,这个查询计划不能直接查询预计算过的数据,这里需要 rewrite 这个执行计划,使得它可以查询预计算过后的数据(也就是Cube数据),来看下面的例子:

用户有一张商品访问表(stock),其中 Item 商品,user_id 表示商品被哪个用户访问过,用户希望分析商品的 PV。用户定义了一个 Cube,维度是 item,度量是COUNT(user_id),用户如果想分析商品的 PV,会发出如下的 SQL:
SELECT item,COUNT(user_id) FROM stock GROUP BY item;
这条 SQL 发给 Kylin 后,Kylin 不能直接的用它原始的语义去查我们的 Cube 数据,这是因为的数据经过预计算后,每个 item 的 key 只会存在一行数据,原始表中相同 item key 的行已经被提前聚合掉了,生成了一列新的 measure 列,存放每个 item key 有多少 user_id 访问,所以 rewrite 的 SQL 会类似这样:
SELECT item,SUM(M_C) FROM stockGROUP BY item;
为什么这里还会有一步 SUM/ GROUP BY 的操作,而不是直接取出数据直接返回就 OK 了呢?因为可能查询击中的 Cuboid 不止 item 一个维度,即击中的不是最精确的 Cuboid,所以还需从这些维度中再聚合一次,但是部分聚合的数据量相比起用户原始表中的数据,还是减少了非常多的数据量和计算。并且如果查询精确的命中Cuboid,我们是可以直接跳过 Agg/GROUP BY 的流程,如下图:
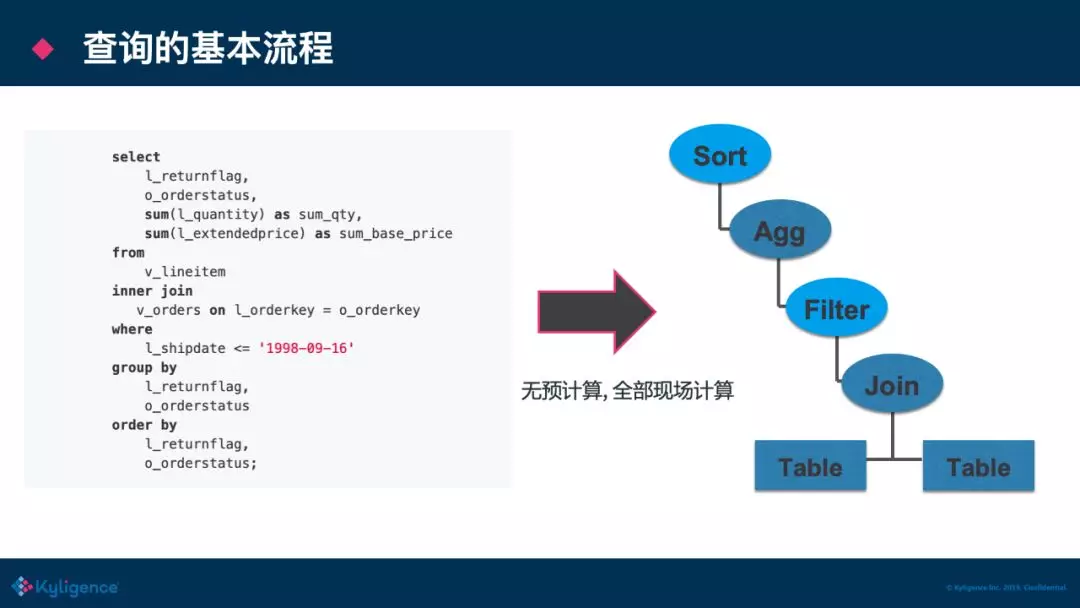
上图是无预计算的场景,全部需要现场计算,Agg 和 Join 因为都会牵涉到 shuffle 操作,故当数据量很大的时候,性能就会比较差,同时也会占用更多的资源,这也会影响查询的并发。
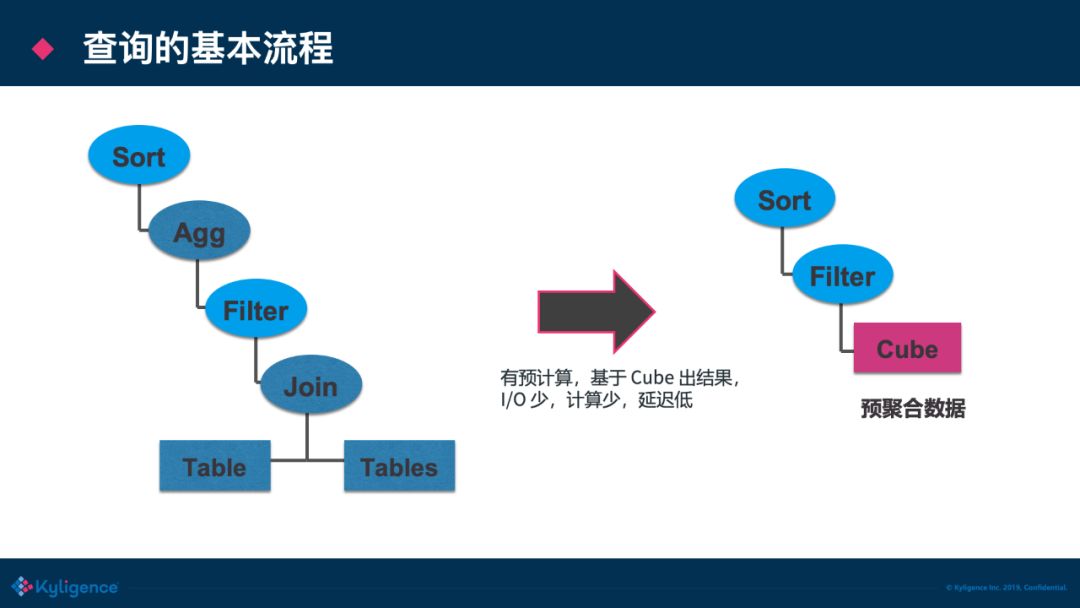
而进行了预计算过后,原来最耗时的两步操作 Agg/Join 在后面改写过的执行计划上都消失了(Cuboid 精准匹配),甚至更进一步,我们在定义 cube 的时候还可以选择按 order by 的列进行排序,那么 Sort 操作也不用计算,整个的计算只是一个 stage,没有一次 shuffle,启动很少的 task 就可以完成计算,查询的并发度也能够提高。
04 Kylin On HBase
#### 基本原理
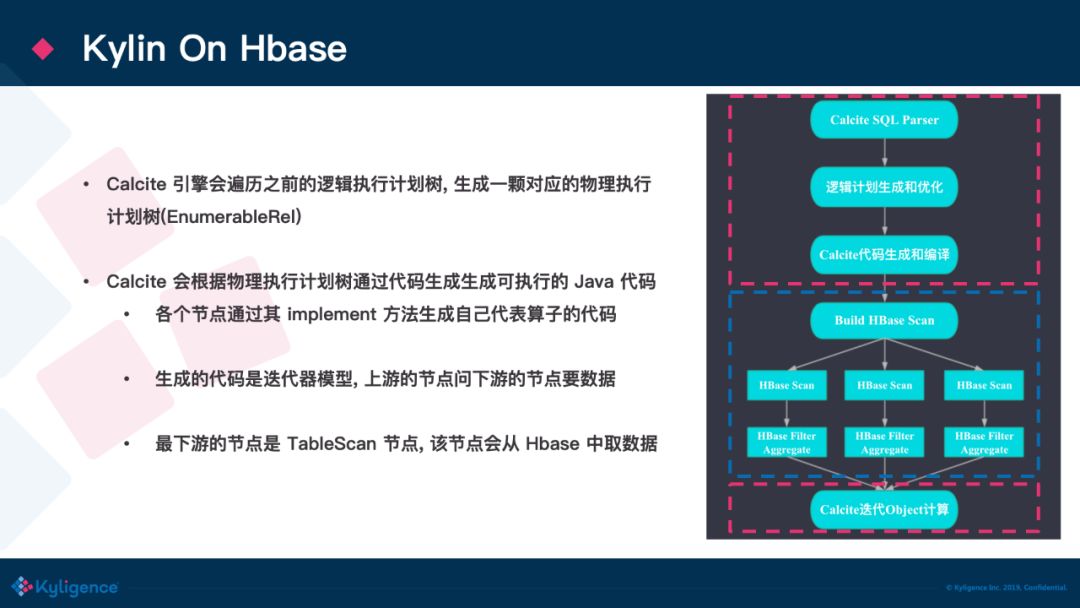
在目前开源版本的实现中,构建完的数据是存储在 HBase 中的,在上面小节中,我们得到了一个能够查询 Cube 数据的逻辑执行计划,Calcite 框架会根据这个逻辑执行计划生成对应的物理执行计划,最终每个算子都会通过代码生成生成自己算子的可执行代码,这个过程是一个迭代器模型,数据从最底层的 TableScan 算子向上游算子流动,整个过程就像火山喷发一样,故又名 Volcano Iterator Mode。而这个 TableScan 生成的代码会从 HBase 中取出 Cube 数据,当数据返回到 Kylin 的 Query Server 端之后,再被上层的算子一层层消费。
Kylin On HBase 瓶颈
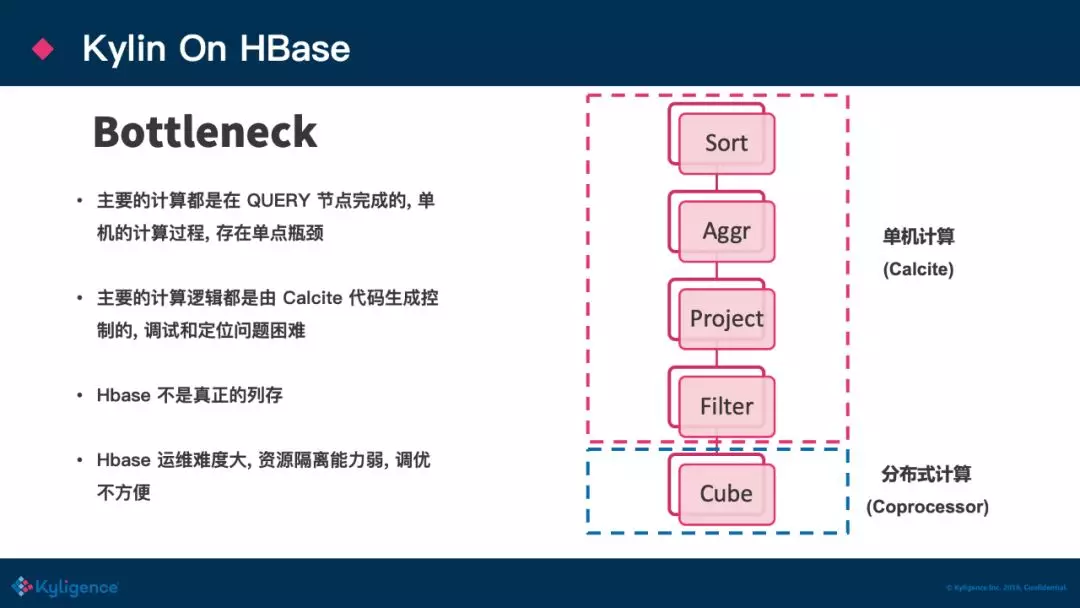
这套方案对于简单的 SQL 并没有什么大问题,因为在精确匹配 Cuboid 的情况下,从 HBase 取回数据后,在 Kylin Query Server 端并不会做太多计算,但当一些比较复杂的查询,例如一句查询 join 了两个子查询,每个子查询都命中了各自的 cube,并在最外层做一些比较复杂的 Aggregate 操作,比如 COUNT DISTINCT 等,在这种情况下,Kylin Query Server 端不仅要从 HBase拉回大量的数据,并且还要在 Kylin Query Server 端计算 Join/Aggregate 等非常耗时耗资源的操作,当数据量变大,Kylin 的Query Server 端就可能会 OOM,解决的方式是提高 Query Server 端的内存,但这是个垂直扩容的过程,这就成了一个单点瓶颈,而大数据方案中存在单点瓶颈,是一个非常严重的问题,可能直接导致公司在架构选型的时候一键 pass 掉这个方案。
另外这套方案在使用中还有很多其他的局限:
- 例如 HBase 的运维是出了名的难,一旦 HBase 性能不好,那么可想而知 Kylin 的性能也不会好。
- HBase 的资源隔离能力也比较弱,当某个时刻有比较大的负载的时候,其他使用 HBase 的业务也会受到影响,体现到 Kylin 可能会是查询的性能比较不稳定,benchmark 会有毛刺,解释起来比较麻烦并且需要集群 metric 的支持,对前线人员要求比较高。
- HBase 里存储的都是经过编码后的 Byte Array 类型,序列化反序列化的开销也不能忽视。而对于我们开发人员来说,Calcite 代码生成比较难以调试,并且我们 HBase 的技能树修的比较少,想对 HBase 做源码级别的性能改进也比较困难。
05 Kylin On Parquet
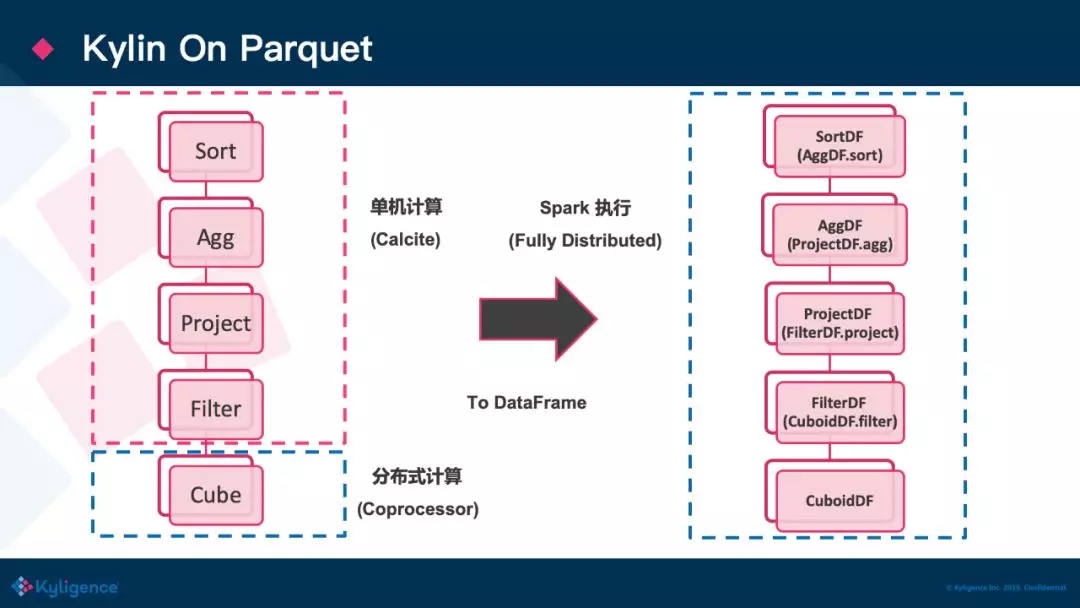
由于上述 Kylin on HBase 方案的诸多局限性,我们公司很早的时候就在商业版本中研发新一代基于 Spark + Parquet 的方案用以替代开源的方案。下面介绍下该方案的整体架构:
其实整体来说,新的设计非常简洁:使用 visitor 模式遍历之前生成的能够查询 Cube 数据的逻辑执行计划树,执行计划树的节点代表一个算子,里面其实无非就是保存了一些信息,比如要扫哪个表,要 filter/project 哪些列等等。将原来树上的每一个算子都翻译成一个 Spark 对于 Dataframe 的一个操作,每个上游节点都问自己的下游节点它处理完之后的一个 DF,一直到最下游的TableScan节点,由它生成初始的 DF,可以简单理解成 cuboidDF= spark.read.parquet(path),得到初始的 DF之后,向它的上游返回,上游节点再对这个下游的 DF apply 上自己的操作,再返回给自己的上游,最后最上层节点对这个 DF 进行 collect 就触发了整个计算流程。这套框架的思想很简单,不过中间 Calcite 和 Spark 的 gap 的坑比我们想象的要多一些,比如数据类型/两边支持函/行为定义不一致等等。后期我们也有打算替换 Calcite 为 Catalyst,整套的架构会更加精致自然。

这一套 Kylin On Parquet 的方案,依托了 Spark:
-
所有计算都是分布式的,不存在单点瓶颈,可以通过横向扩容提高系统的计算能力;
-
资源调度有各种方案可以选择:Yarn/K8S/ Mesos,满足企业对于资源隔离的需求;
-
Spark 在性能方面的努力可以天然享受到,上文提到 Kylin On HBase 的序列化反序列化开销,就可以由 Spark 的 Tungsten 项目进行优化;
-
减少了 HBase 的依赖,带来了运维极大的方便,所有上下游依赖可以由 Spark 帮我们搞定,减少了自己的依赖,也方便上云;
-
对于开发人员来讲,可以对每个算子生成的 DF 直接进行进行 collect,观察数据在这一层有没有出现问题,并且 Spark + Parquet 是目前非常流行的 SQL On Hadoop 方案,我们团队对这两个项目也比较熟悉,维护了一个自己的 Spark 和 Parquet 分支,在上面进行了很多针对于我们特定场景的性能优化和稳定性提升的工作。