
有赞为什么选择 Kylin4
在 2021年5月29日举办的 QCon 全球软件开发者大会上,来自有赞的数据基础平台负责人 郑生俊 在大数据开源框架与应用专题上分享了有赞内部对 Kylin 4.0 的使用经历和优化实践,对于众多 Kylin 老用户来说,这也是升级 Kylin 4 的实用攻略。
本次分享主要分为以下四个部分:
- 有赞选用 Kylin 4 的原因
- Kylin 4 原理介绍
- Kylin 4 性能优化
- Kylin 4 在有赞的实践
01 有赞选用 Kylin 4 的原因
首先分享有赞为什么会选择升级为 Kylin 4,这里先简单回顾一下有赞 OLAP 的发展历程:有赞初期为了快速迭代,选择了预计算 + MySQL 的方式;2018年,因为查询灵活和开发效率引入了 Druid,但是存在预聚合度不高、不支持精确去重和明细 OLAP 等问题;在这样的背景下,有赞引入了满足聚合度高、支持精确去重和 RT 最低的 Apache Kylin 和查询非常灵活的 ROLAP ClickHouse。
从2018年引入 Kylin 到现在,有赞已经使用 Kylin 三年多了。随着业务场景的不断丰富和数据量的不断积累,有赞目前有 600 万的存量商家,2020年 GMV 是 1073亿,日构建量为 100 亿+,目前 Kylin 已经基本覆盖了有赞所有的业务范围。
随着有赞自身的迅速发展和不断深入地使用 Kylin,我们也遇到一些挑战:
- 首先 Kylin on HBase 的构建性能无法满足有赞的预期,构建性能会影响到用户的故障恢复时间和稳定性的体验;
- 其次,随着更多大商家(单店千万级别会员、数十万商品)的接入,对我们的查询也带来了很大的挑战。Kylin on HBase 受限于 QueryServer 单点查询的局限,无法很好地支持这些复杂的场景;
- 最后,因为 HBase 不是一个云原生系统,很难做到弹性的资源伸缩,随着数据量的不断增长,这个系统对于商家而言,使用时间是存在高峰和低谷的,这就造成平均的资源使用率不够高。
面对这些挑战,有赞选择去向更云原生的 Apache Kylin 4 去靠拢和升级。
02 Kylin 4 原理介绍
首先介绍一下 Kylin 4 的主要优势。Apache Kylin 4 是完全基于 Spark 去做构建和查询的,能够充分地利用 Spark的并行化、向量化和全局动态代码生成等技术,去提高大查询的效率。
这里从存储、构建和查询三个部分简单介绍一下 Kylin 4 的原理。
存储

首先来看一下,Kylin on HBase 和 Kylin on Parquet 的对比。Kylin on HBase 的 Cuboid 的数据是存放在 HBase 的表里,一个 Segment 对应了一张 HBase 表,查询下推的工作由 HBase 协理器处理,因为 HBase 不是真正的列存并且对 OLAP 而言吞吐量不高。Kylin 4 将 HBase 替换为 Parquet,也就是把所有的数据按照文件存储,每个 Segment 会存在一个对应的 HDFS 的目录,所有的查询、构建都是直接通过读写文件的方式,不用再经过 HBase。虽然对于小查询的性能会有一定损失,但对于复杂查询带来的提升是更可观的、更值得的。
构建引擎
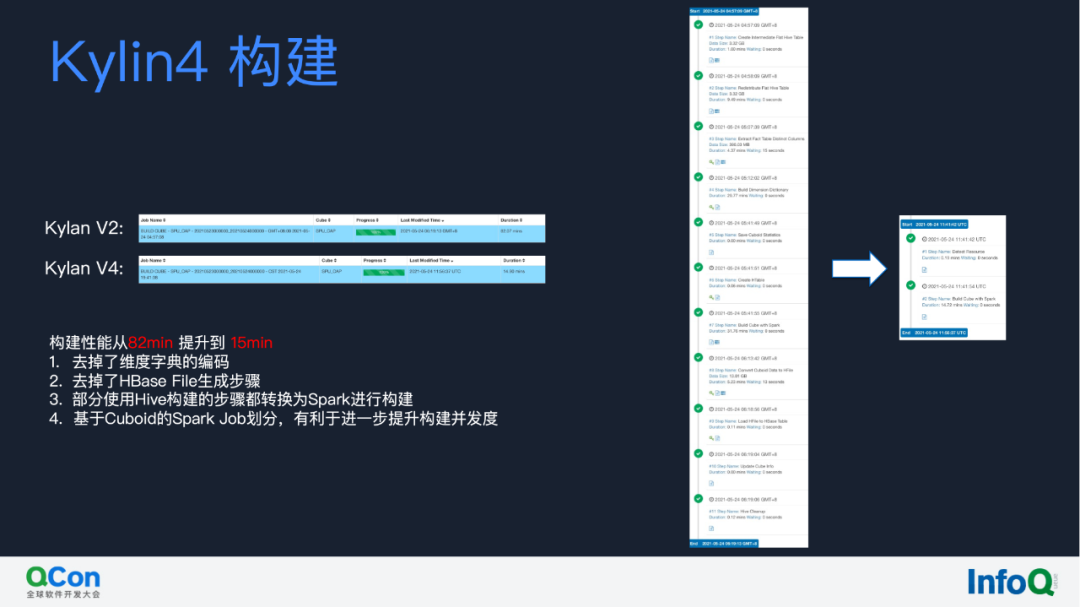
其次是 Kylin 构建引擎,基于有赞的测试,Kylin on Parquet 的构建速度已经从 82 分钟优化到了 15 分钟,有以下几个原因:
- Kylin 4 去掉了维度字典的编码,省去了编码的一个构建步骤;
- 去掉了 HBase File 的生成步骤;
- 新版本的 Kylin 4 所有的构建步骤都转换为 Spark 进行构建;
- Kylin on Parquet 基于 Cuboid 去划分构建粒度,有利于进一步地提升并行度。
可以看到右侧,从十个步骤简化到了两个步骤,构建性能提升的非常明显的。
查询引擎
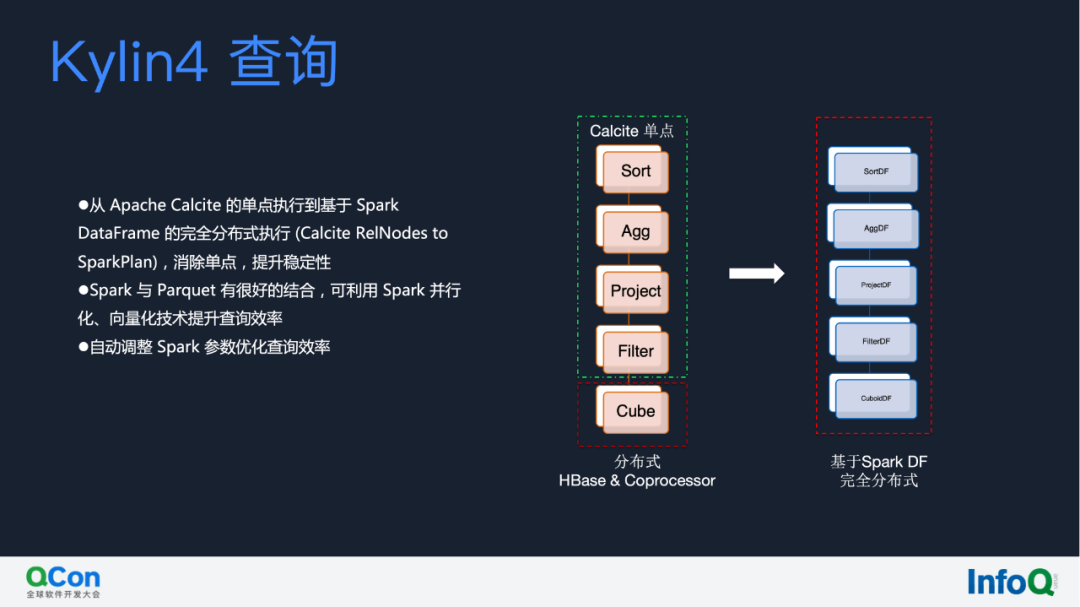
接下来就是 Kylin 4 的查询,大家可以看到,左边这列 Kylin on HBase 的计算是完全依托于 Calcite 和 HBase 的协处理器,这就导致当数据从 HBase 读取后,如果想做聚合、排序等,就会局限于 QueryServer 单点的瓶颈,而 Kylin 4 则转换为基于 Spark DataFrame 的全分布式的查询机制。
03 Kylin 4 性能优化
接下来分享有赞在 Kylin 4 所做的一些性能优化。
查询性能优化
#### 1.动态消除维度分区

首先我们来看一个场景,我们做到了动态消除分区维度,混合使用 cuboid 来对复杂查询,减少数十倍的计算量。
这里举一个例子,在一个 Cube 有三个 Segment 的情况下,Cube 分区字段记作 P,它有三个 Segment 分别是1月1日到2月1日、2月1日到3月1日,3月1日到3月7日。假设有一个SQL,Select count(a) from test where p >= 20200101 and p <= 20200313 group by a。
在这种情况下,因为需要分区过滤,Kylin 它会选择 a 和 p 预计算维度的组合,转换成执行计划就是最上层的 Aggregate 然后 Filter,最后会转换成一个 TableScan,这个 TableScan 就是选择聚合维度为 a 和 p 这样的一个维度组合。实际上这个查询计划是适合把它优化成右边这种方式的,对于某个 Segment 完全使用到的数据,我们可以选择一个 Cuboid 为 a 的 Cuboid 去做查询。对于部分用到的分区或者 Segment,我们可以选择 a 和 p 这样的一个维度组合。通过这种方式,在 a 只有一个可能值的情况下,之前可能要 scan 65 条数据,优化后只要 scan 8 条数据。假设时间跨度更长,比如说跨几个月、半年甚至一年,就会减少数十倍、几十倍的计算量和 IO。
在有赞某些场景,RT 可以从 10 秒优化到 3 秒、20s 提升到 6s,对于更复杂的场景(比如计算密集型的 HLL),会有更显著的优化效果。这部分优化,有赞也正打算贡献回社区。因为涉及到如何在多层嵌套和复杂的条件下进行 segment 分组,以及目前 calcite 和 spark catalyst 并存,实现上会比较复杂。到时候大家在 Kylin 4.0-GA 版本可能就可以看到这个优化了。
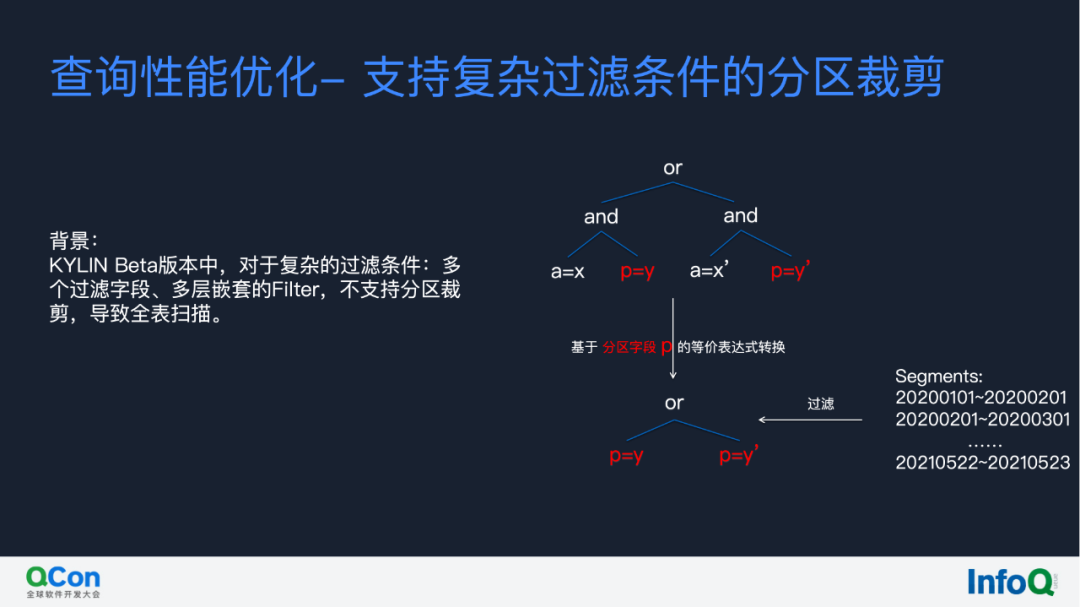
2.复杂过滤条件下的分区裁剪
接下来再介绍一下有赞所做的查询性能优化,就是支持复杂过滤条件下的分区裁剪。目前 Kylin 4.0 Beta 版本对于复杂的过滤条件比如多个过滤字段、多层嵌套的 Filter 等,不支持分区裁剪,导致全表扫描。我们做了一个优化,是将复杂的嵌套 Filter 过滤的语法树转换成基于分区字段 p 的一个等价表达式,然后再将这个表达式应用到每一个 Segment 去做过滤,通过这样的方式,去支持它做到一个非常复杂的分区过滤裁剪。
3.Spark 参数调优

接下来是比较重要的一部分,就是关于 Spark 的调参。Spark 是一个分布式计算框架,相比 Calcite 而言,对于小查询是存在一定劣势的。
首先我们做了一个调整,尽量让 Spark 所有的计算操作是在内存中完成的。以下两种情况会产生 spill:
- 01 在聚合时,在我们内存不够的时候,Spark 会将 HashAggregate 转换为 Sort Based Aggregate,实际上这一步是很耗性能的。我们通过调大阈值的参数,尽量让所有的聚合都在内存中完成。
- 02 在 shuffle 的过程中,Spark是不可避免地会进行 Spill,会落盘,我们能做的尽量在 Shuffle 过程减少 Spill,只在最后 Shuffle 结束之后进行 Spill。
第二个我们做的调优是,相比 on YARN/Standalone 模式下,local 模式大部分都是在进程内通信的,也不需要产生跨网络的 Shuffle, broadcast 广播变量也不需要跨网络,所以对于小查询,我们会路由到以 Local 模式运行的 Spark Application,这对于小查询非常有意义。
第三个优化是 shuffle 使用内存盘。因为内存盘肯定是最快的,我们将内存盘挂载为 tmpfs 文件系统,然后将 spark.local.dir 指定为挂载的内存盘去优化 shuffle 的速度和吞吐。
第四个优化是我们关闭 Spark 全局动态代码生成。Spark 的全局动态代码生成是要在运行的时间内去动态拼接代码,再去动态编译代码,这个过程实际上是很耗时的。对于离线的大数据量下是很有优化意义,但是对于比较小的一些数据场景,我们关掉这个动态代码生成之后,能够节省大概 100 到 200 毫秒的耗时。
目前经过上述一系列的优化,我们能让小查询的 RT 稳定在大概 300 毫秒左右,尽管 HBase 可能是几十毫秒左右的 RT,但我们认为目前已经比较接近了,这种为提升大查询提升的 Tradeoff 我们认为是一个很值得的事情。
4.小查询优化

然后,我来分享一下小查询的优化。Kylin on HBase 依托于 HBase 能够做到几十毫秒的 RT,因为 HBase 有 bucket cache 缓存。而 Kylin on Parquet 就完全基于文件的读取和计算,缓存依赖于文件系统的 page cache,那么它小查询的 RT 会比 HBase 更高一些,我们能做的就是尽量缩小 Kylin on Parquet 和 Kylin on HBase 的 RT 差距。
经过我们的分析,SQL 会通过 Calcite 解析成 Calcite 语法树,然后将这个语法树转化为 Spark DataFrame,最终再将整个查询交给 Spark 去执行。在这一步的过程中,SQL 转化成 Calcite 的过程中,是需要经过语法解析、优化等,这一步大概会消耗 150 毫秒左右。有赞做的是尽量使用结构化的 SQL,就是 PreparedStatement,我们在 Kylin 中支持 PreparedStatementCache,对于固定的 SQL 格式,将它的执行计划进行缓存,去重用这样的执行计划,降低该步骤的时间消耗,通过这样的优化,可以降低大概 100 毫秒左右的耗时。
5.Parquet 优化
关于查询性能的优化,有赞还充分利用了 Parquet 索引,优化建议包括:
-
Parquet 文件首先根据 Shard By Column 进行分组,过滤条件尽量包含 Shard By Column;
-
Parquet 中的数据依然按照维度排序,结合 Column MetaData 中的 Max、Min 索引,在命中前缀索引时能够过滤掉大量数据;
-
调小 RowGroup Size 增大索引粒度等。
构建性能优化
#### 1.对 parent dataset 做缓存

2.处理空值导致的数据倾斜

更多关于构建优化的细节内容大家可以参考 Kylin 4 最新功能预览 + 优化实践抢先看
04 Kylin 4 在有赞的实践
介绍有赞的优化之后,我们再来分享一下优化的效果,也就是 Kylin 4 在有赞的实践包括升级过程以及上线的效果。
元数据升级
首先是如何升级,我们开发了一个元数据无缝升级的工具,首先我们在 Kylin on HBase 的元数据是保存在 HBase 里的,我们将 HBase 里的元数据以文件的格式导出,再将文件格式的元数据写入到 MySQL,我们也在 Apache Kylin 的官方 wiki 更新了操作文档以及大致的原理,更多详情大家可以参考:如何升级元数据到kylin4.

我们大致介绍一下整个过程中的一些兼容性,需要迁移的数据大概有六个:前三个是 project 元信息,tables 的元信息,包括一些 Hive 表,还有 model 模型定义的一些元信息,这些是不需要修改的。需要修改的就是 Cube 的元信息。这部分需要修改哪些东西呢?首先是 Cube 所使用的存储和查询的类型,更新完这两个字段之后,需要重新计算一下 Cube 的签名,这个签名的作用是 Kylin 内部设计的避免 Cube 确定之后我们再去修改 Cube 导致的一些问题;最后一个是权限相关,这部分也是兼容,无需修改的。
Kylin 4 在有赞上线后的表现

元数据迁移到 Kylin 之后,我们来分享一下在有赞的一些场景下带来了的质变和大幅度的性能提升。首先像商品洞察这样一个场景,有一个数十万商品的大店铺,我们要去分析它的交易和流量等,有十几个精确去重的计算。精确去重如果没有通过预计算和 Bitmap 去做优化实际上效率是很低的,Kylin 目前使用 Bitmap 去做精确去重的支持。在一个需要对几十万个商品的各种 UV 去做排序的复杂查询的场景,Kylin 2 的 RT 是 27 秒,而在 Kylin 4 这个场景的 RT 从 27 秒降到了 2 秒以内。
我觉得 Kylin 4 最吸引我的地方是它完全变成了一个手动档,而 Kylin on HBase 实际上是一个自动档,因为它的并发完全和 region 的数量绑定了。

Kylin 4 在有赞的未来计划
Kylin 4 在有赞的升级大致包含以下几个步骤:
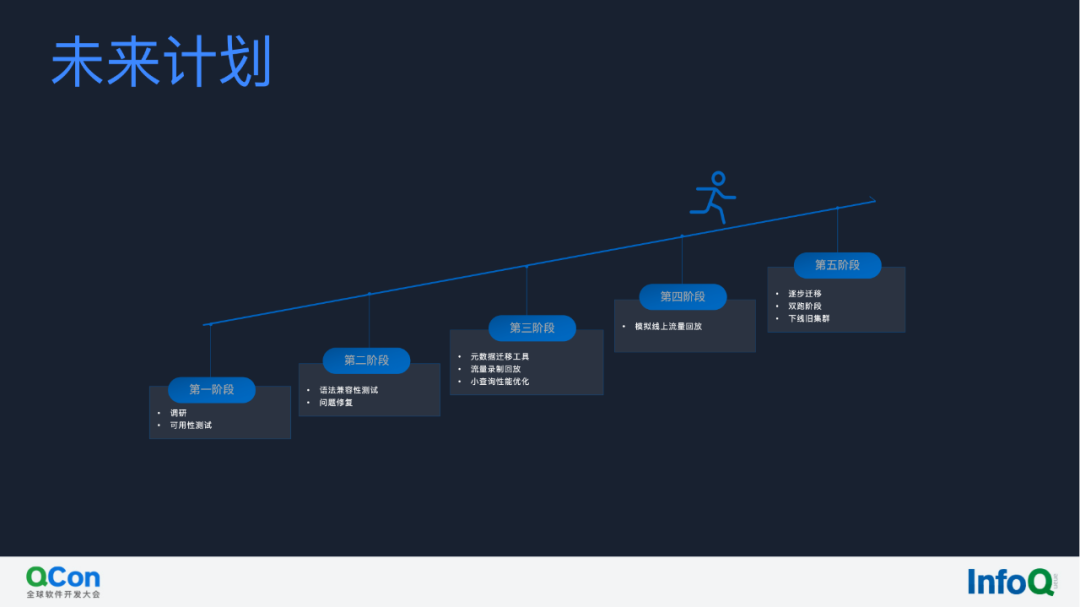
第一阶段就是调研和可用性测试,因为 Kylin on Parquet 实际上是基于 Spark,是有一定的学习成本的,这个我们也花了一段时间;
第二阶段就是语法兼容性测试,我们扩展了 Kylin 4 初期不支持的一些语法,比如说分页查询的语法等;
第三阶段就是流量重放,逐步地上线 Cube 等;
我们现在是属于第四阶段,我们已经迁移了一些数据了,未来的话,我们会逐步地下线旧集群,然后将所有的业务往新集群上去迁移。
关于 Kylin 4 我们未来计划开发的功能和满足的需求有赞也会在社区去同步。就不在这里做详细介绍了,大家可以关注我们社区的最新动态,以上就是我们的分享。