
在 Cube 级别重写默认的 kylin.properties
conf/kylin.properties 里有许多的参数,控制/影响着 Kylin 的行为;大多数参数是全局配置的,例如 security 或 job 相关的参数;有一些是 Cube 相关的;这些 Cube 相关的参数可以在任意 Cube 级别进行自定义。对应的 GUI 页面是 Cube 创建的 “重写配置” 步骤所示的页面,如下图所示.
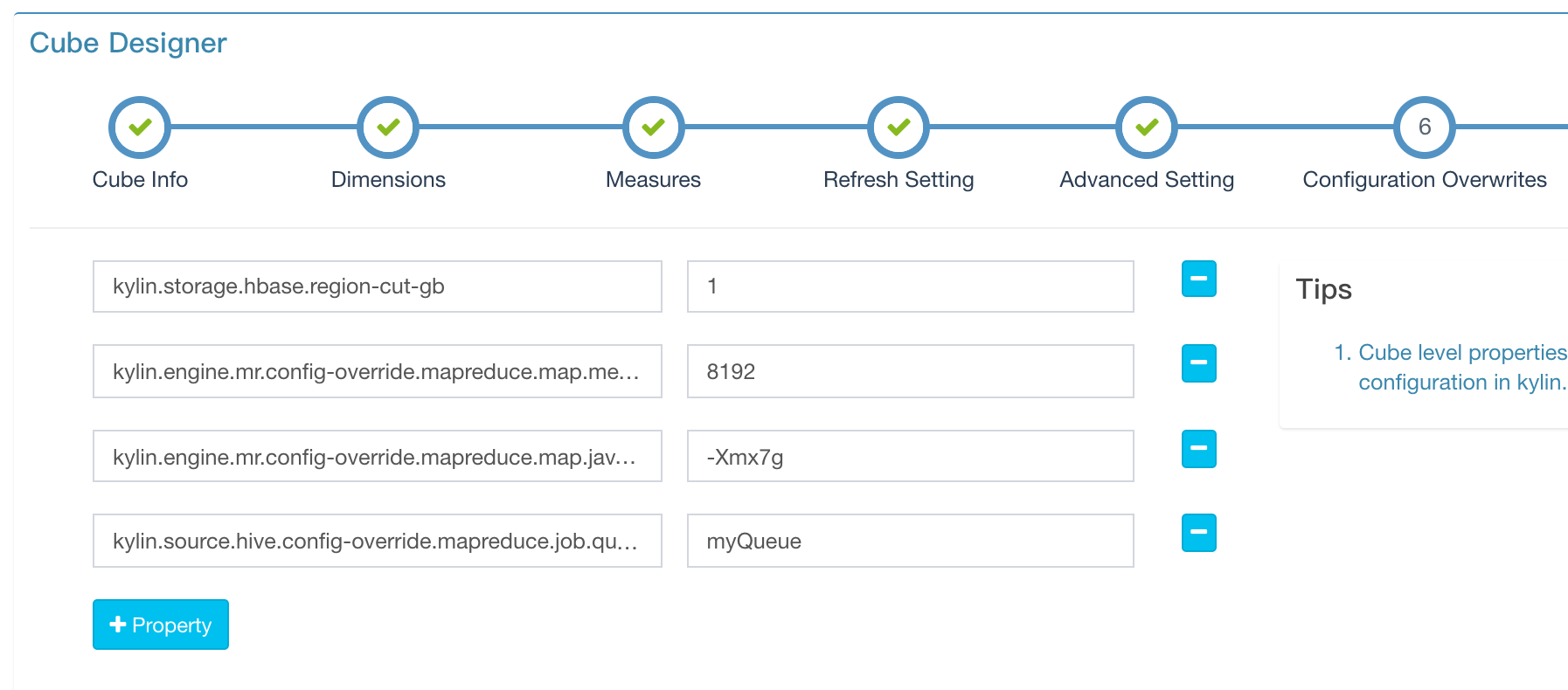
两个示例:
-
kylin.cube.algorithm:定义了 job engine 选择的 Cubing 算法;默认值为 “auto”,意味着 engine 会通过采集数据动态的选择一个算法 (“layer” or “inmem”)。如果您很了解 Kylin 和 您的数据/集群,您可以直接设置您喜欢的算法。 -
kylin.storage.hbase.region-cut-gb:定义了创建 HBase 表时一个 region 的大小。默认一个 region “5” (GB)。对于小的或中等大小的 cube 来说它的值可能太大了,所以您可以设置更小的值来获得更多的 regions,可获得更好的查询性能。
在 Cube 级别重写默认的 Hadoop job conf 值
conf/kylin_job_conf.xml 和 conf/kylin_job_conf_inmem.xml 管理 Hadoop jobs 的默认配置。如果您想通过 cube 自定义配置,您可以通过和上面相似的方式获得,但是需要加一个前缀 kylin.engine.mr.config-override.;当提交 jobs 这些配置会被解析并应用。下面是两个示例:
- 希望 job 从 Yarn 获得更多 memory,您可以这样定义:
kylin.engine.mr.config-override.mapreduce.map.java.opts=-Xmx7g和kylin.engine.mr.config-override.mapreduce.map.memory.mb=8192 - 希望 cube’s job 使用不同的 Yarn resource queue,您可以这样定义:
kylin.engine.mr.config-override.mapreduce.job.queuename=myQueue(“myQueue” 是一个举例,可更换成您的 queue 名字)
在 Cube 级别重写默认的 Hive job conf 值
conf/kylin_hive_conf.xml 管理运行时 Hive job 的默认配置 (例如创建 flat hive table)。如果您想通过 cube 自定义配置,您可以通过和上面相似的方式获得,但需要另一个前缀 kylin.source.hive.config-override.;当运行 “hive -e” 或 “beeline” 命令,这些配置会被解析并应用。请看下面示例:
- 希望 hive 使用不同的 Yarn resource queue,您可以这样定义:
kylin.source.hive.config-override.mapreduce.job.queuename=myQueue(“myQueue” 是一个举例,可更换成您的 queue 名字)
在 Cube 级别重写默认的 Spark conf 值
Spark 的配置是在 conf/kylin.properties 中管理,前缀为 kylin.engine.spark-conf.。例如,如果您想要使用 job queue “myQueue” 运行 Spark,设置 “kylin.engine.spark-conf.spark.yarn.queue=myQueue” 会让 Spark 在提交应用时获取 “spark.yarn.queue=myQueue”。参数可以在 Cube 级别进行配置,将会覆盖 conf/kylin.properties 中的默认值。
支持压缩
默认情况,Kylin 不支持压缩,在产品环境这不是一个推荐的设置,但对于新的 Kylin 用户是个权衡。一个合适的算法将会减少存储负载。不支持的算法会阻碍 Kylin job build。Kylin 可以使用三种类型的压缩,HBase 表压缩,Hive 输出压缩 和 MR jobs 输出压缩。
-
HBase 表压缩
压缩设置通过kylin.hbase.default.compression.codec定义在kyiln.properties中,默认值为 none。有效的值包括 none,snappy,lzo,gzip 和 lz4。在变换压缩算法前,请确保您的 Hbase 集群支持所选算法。尤其是 snappy,lzo 和 lz4,不是所有的 Hadoop 分布式都会包含。 -
Hive 输出压缩
压缩设置定义在kylin_hive_conf.xml。默认设置为 empty 其利用了 Hive 的默认配置。如果您重写配置,请在kylin_hive_conf.xml中添加 (或替换) 下列属性。以 snappy 压缩为例:
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description></description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description></description>
</property>- MR jobs 输出压缩
压缩设置定义在kylin_job_conf.xml和kylin_job_conf_inmem.xml中。默认设置为 empty 其利用了 MR 的默认配置。如果您重写配置,请在kylin_job_conf.xml和kylin_job_conf_inmem.xml中添加 (或替换) 下列属性。以 snappy 压缩为例:
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description></description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description></description>
</property>压缩设置只有在重启 Kylin 服务器实例后才会生效。
分配更多内存给 Kylin 实例
打开 bin/setenv.sh,这里有两个 KYLIN_JVM_SETTINGS 环境变量的样例设置;默认设置较小 (最大为 4GB),您可以注释它然后取消下一行的注释来给其分配 16GB:
export KYLIN_JVM_SETTINGS="-Xms1024M -Xmx4096M -Xss1024K -XX:MaxPermSize=128M -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:$KYLIN_HOME/logs/kylin.gc.$$ -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=64M"
# export KYLIN_JVM_SETTINGS="-Xms16g -Xmx16g -XX:MaxPermSize=512m -XX:NewSize=3g -XX:MaxNewSize=3g -XX:SurvivorRatio=4 -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:CMSInitiatingOccupancyFraction=70 -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError"启用多个任务引擎
从 2.0 开始, Kylin 支持多个任务引擎一起运行,相比于默认单任务引擎的配置,多引擎可以保证任务构建的高可用。
使用多任务引擎,你可以在多个 Kylin 节点上配置它的角色为 job 或 all。为了避免它们之间产生竞争,需要启用分布式任务锁,请在 kylin.properties 里配置:
kylin.job.scheduler.default=2
kylin.job.lock=org.apache.kylin.storage.hbase.util.ZookeeperJobLock
并记得将所有任务和查询节点的地址注册到 kylin.server.cluster-servers.
支持 LDAP 或 SSO authentication
查看 How to Enable Security with LDAP and SSO
支持邮件通知
Kylin 可以在 job 完成/失败的时候发送邮件通知;编辑 conf/kylin.properties,设置如下参数使其生效:
mail.enabled=true
mail.host=your-smtp-server
mail.username=your-smtp-account
mail.password=your-smtp-pwd
mail.sender=your-sender-address
kylin.job.admin.dls=adminstrator-address重启 Kylin 服务器使其生效。设置 mail.enabled 为 false 令其失效。
所有的 jobs 管理员都会收到通知。建模者和分析师需要将邮箱填写在 cube 创建的第一页的 “Notification List” 中,然后即可收到关于该 cube 的通知。