
Apache Kylin4 — A new storage and compute architecture
This article will discuss three aspects of Apache Kylin: First, we will briefly introduce query principles of Apache Kylin. Next, we will introduce Apache Parquet Storage, a project our team has been involved in that Kyligence is contributing back to the open source software community by the end of this year (2020). Finally, we will introduce the extensive use of precision count distinct by community users as well as its implementation in Kylin and some extensions.
01 Introduction to Apache Kylin
Apache Kylin is an open source distributed analysis engine that provides SQL query interfaces above Hadoop/Spark and OLAP capabilities to support extremely large data. It was initially developed at eBay Inc. and contributed to the open source software community. It can query massive relational tables with sub-second response times.
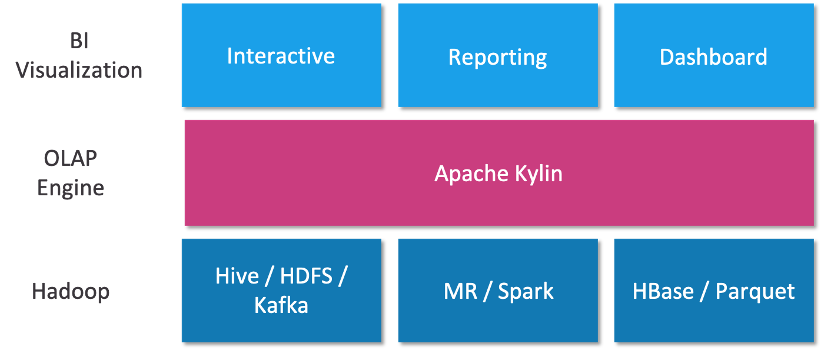
As a SQL acceleration layer, Kylin can connect with various data sources such as Hive and Kafka, and can connect with commonly used BI systems such as Tableau and Power BI. It can also be queried directly (ad hoc) using standard SQL tools.
If you find yourself confronted by unhappy BI users for any of the following reasons, you should consider using Apache Kylin:
- Their batch of queries are too slow
- Query or user concurrency should be higher
- Resources usage should be lower
- The system doesn’t fully support SQL syntax
- The system doesn’t seamlessly integrate with their favorite BI tools\
02 Apache Kylin Rationale
Kylin’s core idea is the precomputation of result sets, meaning it calculates all possible query results in advance according to the specified dimensions and indicators and uses space for time to speed up OLAP queries with fixed query patterns.
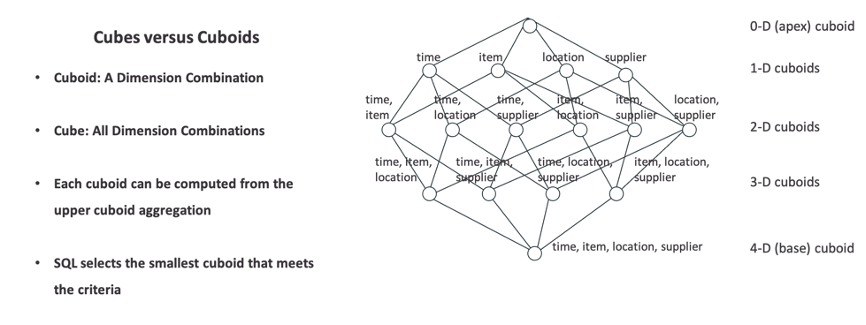
Kylin’s design is based on cube theory. Each combination of dimensions is called a cuboid and the set of all cuboids is a cube. The cuboid composed of all dimensions is called the base cuboid, and the time, item, location, and supplier shown in the figure is an example of this. All cuboids can be calculated from the base cuboid. A cuboid can be understood as a wide table after precomputation. During the query, Kylin will automatically select the most suitable cuboid that meets the query requirements.
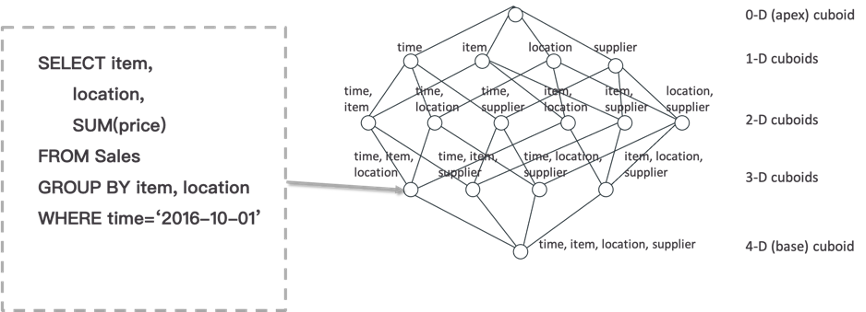
For example, the query in the above figure will look for the cuboid (time, item, location). Compared with the calculation from the user’s original table, the calculation from the cuboid can greatly reduce the amount of scanned data and calculation.
03 Apache Kylin Basic Query Process
Let’s look briefly at the rationale of Kylin queries. The first three steps are the routine operations of all query engines. We use the Apache Calcite framework to complete this operation. We will not go into great detail here but, should you wish to learn more, there is plenty of related material online.

The introduction here focuses on the last two steps: Kylin adaptation and query execution. Why do we need to do Kylin adaptation? Because the query plan we obtained earlier is directly converted according to the user’s query, and so this query plan cannot directly query the precomputed data. Here, a rewrite is needed to create an execution plan so that it can query the precomputed data (i.e. cube data). Let’s look at the following example:
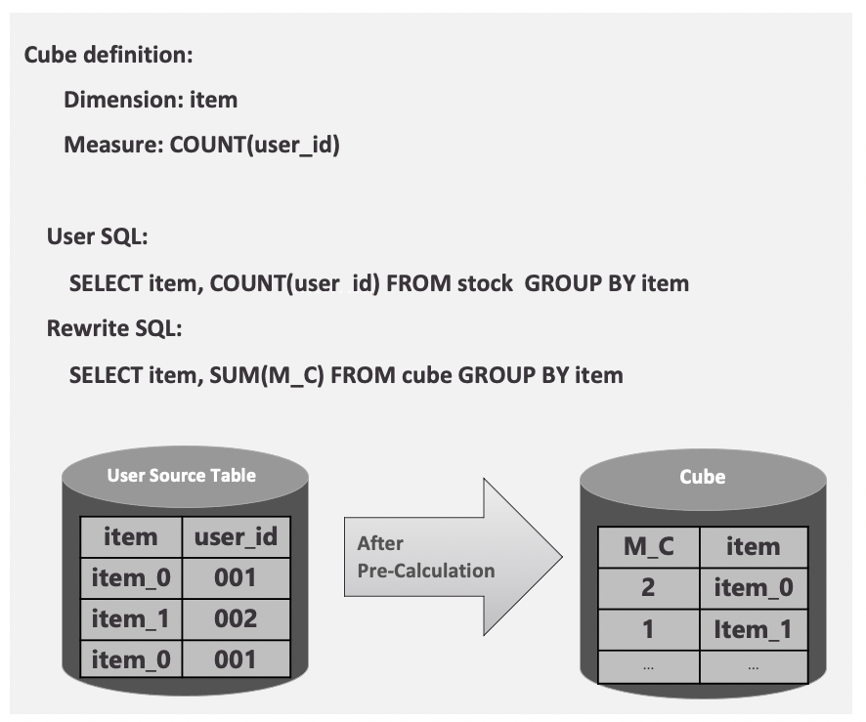
The user has a stock of goods. Item and user_id indicate which item has been accessed and the user wants to analyze the Page View (PV) of the goods. The user defines a cube where the dimension is item and the measure is COUNT (user_id). If the user wants to analyze the PV of the goods, he will issue the following SQL:
SELECT item, COUNT (user_id) FROM stock GROUP BY item;
After this SQL is sent to Kylin, Kylin cannot directly use its original semantics to query our cube data. This is because after the data is precomputed, there will only be one row of data in the key of each item. The rows of the same item key in the original table have been aggregated in advance, generating a new measure column to store how many user_id accesses each item key has, so the rewritten SQL will be similar to this:
SELECT item, SUM (M_C) FROM stock GROUP BY item;
Why is there another SUM/GROUP BY operation here instead of directly fetching the data and returning it? Because the cuboid that may be hit by the query is more than one dimension of item, meaning it is not the most accurate cuboid. It needs to be aggregated again from these dimensions, but the amount of partially aggregated data still significantly reduces the amount of data and calculation compared with the data in the user’s original table. If the query hits the cuboid accurately, we can directly skip the process of Agg/GROUP BY, as it is shown in the following figure:

The above figure is a scenario without precomputation, which requires on-site calculation. Agg and Join will involve shuffle, so the performance will be poor and more resources will be occupied with large amounts of data, which will affect the concurrency of queries.

After the precomputation, the previously most time-consuming two-step operation (Agg/Join) disappeared from the rewritten execution plan, showing a cuboid precise match. Additionally, when defining the cube we can choose to order by column so the Sort operation does not need to be calculated. The whole calculation is a single stage without the expense of a shuffle. The calculation can be completed with only a few tasks therefore improving the concurrency of the query.
04 Apache Kylin on HBase
In the current open source version, the built data is stored in HBase, we’ve got a logical execution plan that can query cube data from the above section. Calcite framework will generate the corresponding physical execution plan according to this logical execution plan and, finally, each operator will generate its own executable code through code generation.

This process is an iterator model. Data flows from the lowest TableScan operator to the upstream operator. The whole process is like a volcanic eruption, so it is also called Volcano Iterator Mode. The code generated by this TableScan will fetch cube data from HBase, and when the data is returned to Kylin Query Server, it will be consumed layer by layer by the upper operator.
05 Bottlenecks with Kylin on HBase
This scenario is not a big problem with simple SQL because, in the case of a precise matching cuboid, minimal computing will be done on Kylin Query Server after retrieving the data from HBase. However, for some more complex queries, Kylin Query Server will not only pull back a large amount of data from HBase but also compute very resource-intensive operations such as Joins and Aggregates.
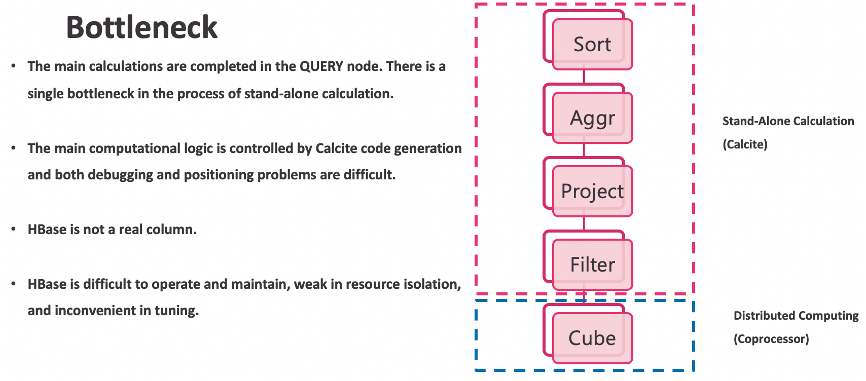
For example, a query joins two subqueries, each subquery hits its own cube and then does some more complicated aggregate operations at the outermost layer such as COUNT DISTINCT. When the amount of data becomes large, Kylin Query Server may be out of memory (OOM). The solution is to simply increase the memory of the Kylin Query Server.
However, this is a vertical expansion process that becomes a bottleneck. We know from experience that bottlenecks in big data can be difficult to diagnose and can lead to the abandonment of a critical technology when selecting an architecture. In addition, there are many other limitations when using this system. For example, the operation and maintenance of HBase is notoriously difficult. It is safe to assume that once the performance of HBase is not good, the performance of Kylin will also suffer.
The resource isolation capabilities of HBase are also relatively weak. When there is a large load at a given moment, other applications using HBase will also be affected. This may cause Kylin to have unstable query performance which can be difficult to troubleshoot. All data stored in HBase are encoded Byte Array types and the overhead of serialization and deserialization cannot be ignored.
06 Apache Kylin with Spark + Parquet
Due to the limitations of the Kylin-on-HBase solution mentioned above, Kyligence has developed a new generation of Spark + Parquet-based solutions for the commercial version of Kylin. This was done early on to update and enhance the open source software solution for enterprise use.
The following is an introduction to the overall framework of this new system.
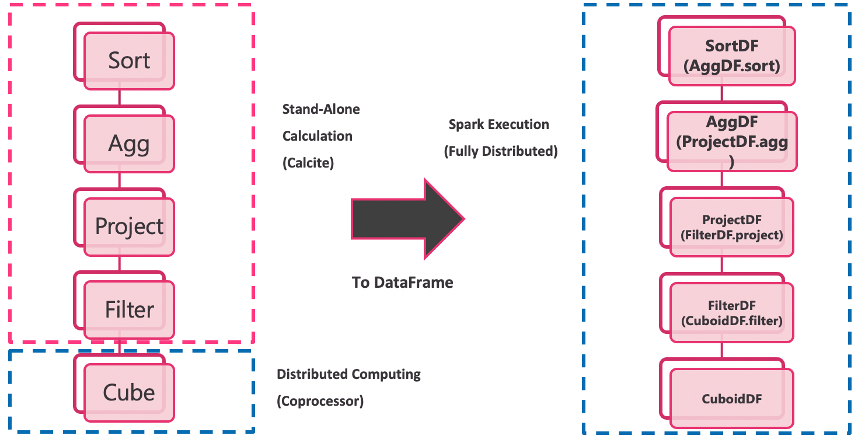
In fact, the new design is very simple. The visitor mode is used to traverse the previously generated logical execution plan tree that can query cube data. The nodes of the execution plan tree represent an operator, which actually stores nothing more than some information such as which table to scan, which columns to filter/project, etc. Each operator will be translated into a Spark operation on Dataframe on the original tree, each upstream node asks its downstream node for a DF up to the most downstream TableScan node after it has finished processing. After it generates the initial DF, which can be simply understood as cuboidDF = spark.read.parquet (path). After obtaining the initial DF, it returns to its upstream. The upstream node applies its own operation on the downstream DF and returns to its upstream. Finally, the top node collects the DF to trigger the whole calculation process.
07 Advantages of the Spark/Parquet Architecture
This Kylin on Parquet plan relies on Spark. All calculations are distributed and there is no single point where performance can bottleneck. The computing power of the system can be improved through horizontal expansion (scale-out). There are various schemes for resource scheduling such as Yarn, K8S, or Mesos to meet the needs of enterprises for resource isolation. Spark’s performance efforts can be naturally enjoyed. The overhead of serialization and deserialization of Kylin on HBase mentioned above can be optimized by Spark’s Tungsten project.

Reducing the dependence upon HBase simplifies operation and maintenance. All upstream and downstream dependencies can be handled by Spark for us, reducing our dependence and facilitating cloud access.
For developers, the DF generated by each operator can be collected directly to observe whether there is any problem with the data at this level, and Spark + Parquet is currently a very popular SQL on Hadoop scheme. The open source committers at Kyligence are also familiar with these two projects and maintain their own Spark and Parquet branch. A lot of performance optimization and stability improvements have been done in this area for our specific scenarios.
08 Summary
Apache Kylin has over 1,000 users worldwide. But, in order for the project to ensure its future position as a vital, Cloud-Native technology for enterprise analytics, the Kylin community must periodically evaluate and update the key architectural assumptions being made to accomplish that goal. The removal of legacy connections to the Hadoop ecosystem in favor of Spark and Parquet is an important next step to realizing the dream of pervasive analytics based on open source technology for organizations of all sizes around the world.