
Why did Youzan choose Kylin4
At the QCon Global Software Developers Conference held on May 29, 2021, Zheng Shengjun, head of Youzan’s data infrastructure platform, shared Youzan’s internal use experience and optimization practice of Kylin 4.0 on the meeting room of open source big data frameworks and applications.
For many users of Kylin2/3(Kylin on HBase), this is also a chance to learn how and why to upgrade to Kylin 4.
This sharing is mainly divided into the following parts:
- The reason for choosing Kylin 4
- Introduction to Kylin 4
- How to optimize performance of Kylin 4
- Practice of Kylin 4 in Youzan
01 The reason for choosing Kylin 4
Introduction to Youzan
China Youzan Co., Ltd (stock code 08083.HK). is an enterprise mainly engaged in retail technology services.
At present, it owns several tools and solutions to provide SaaS software products and talent services to help merchants operate mobile social e-commerce and new retail channels in an all-round way.
Currently Youzan has hundreds of millions of consumers and 6 million existing merchants.
History of Kylin in Youzan
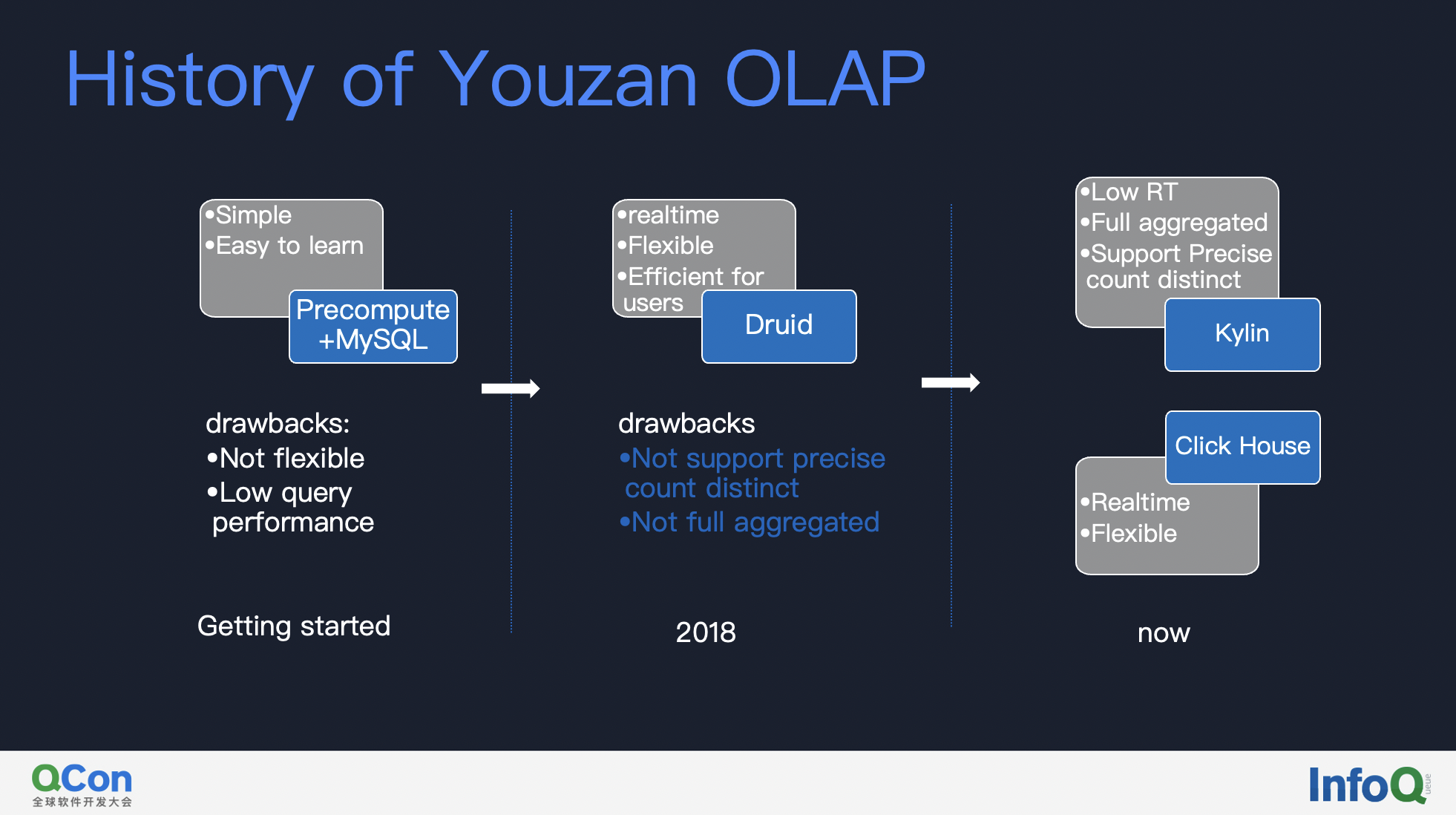
First of all, I would like to share why Youzan chose to upgrade to Kylin 4. Here, let me briefly reviewed the history of Youzan OLAP infra.
In the early days of Youzan, in order to iterate develop process quickly, we chose the method of pre-computation + MySQL; in 2018, Druid was introduced because of query flexibility and development efficiency, but there were problems such as low pre-aggregation, not supporting precisely count distinct measure. In this situation, Youzan introduced Apache Kylin and ClickHouse. Kylin supports high aggregation, precisely count distinct measure and the lowest RT, while ClickHouse is quite flexible in usage(ad hoc query).
From the introduction of Kylin in 2018 to now, Youzan has used Kylin for more than three years. With the continuous enrichment of business scenarios and the continuous accumulation of data volume, Youzan currently has 6 million existing merchants, GMV in 2020 is 107.3 billion, and the daily build data volume is 10 billion +. At present, Kylin has basically covered all the business scenarios of Youzan.
The challenges of Kylin 3
With Youzan’s rapid development and in-depth use of Kylin, we also encountered some challenges:
- First of all, the build performance of Kylin on HBase cannot meet the favorable expectations, and the build performance will affect the user’s failure recovery time and stability experience;
- Secondly, with the access of more large merchants (tens of millions of members in a single store, with hundreds of thousands of goods for each store), it also brings great challenges to our OLAP system. Kylin on HBase is limited by the single-point query of Query Server, and cannot support these complex scenarios well;
- Finally, because HBase is not a cloud-native system, it is difficult to achieve flexible scale up and scale down. With the continuous growth of data volume, this system has peaks and valleys for businesses, which results in the average resource utilization rate is not high enough.
Faced with these challenges, Youzan chose to move closer and upgrade to the more cloud-native Apache Kylin 4.
02 Introduction to Kylin 4
First of all, let’s introduce the main advantages of Kylin 4. Apache Kylin 4 completely depends on Spark for cubing job and query. It can make full use of Spark’s parallelization, quantization(向量化), and global dynamic code generation technologies to improve the efficiency of large queries.
Here is a brief introduction to the principle of Kylin 4, that is storage engine, build engine and query engine.
Storage engine

First of all, let’s take a look at the new storage engine, comparison between Kylin on HBase and Kylin on Parquet. The cuboid data of Kylin on HBase is stored in the table of HBase. Single Segment corresponds to one HBase table. Aggregation is pushed down to HBase coprocessor.
But as we know, HBase is not a real Columnar Storage and its throughput is not enough for OLAP System. Kylin 4 replaces HBase with Parquet, all the data is stored in files. Each segment will have a corresponding HDFS directory. All queries and cubing jobs read and write files without HBase . Although there will be a certain loss of performance for simple queries, the improvement brought about by complex queries is more considerable and worthwhile.
Build engine
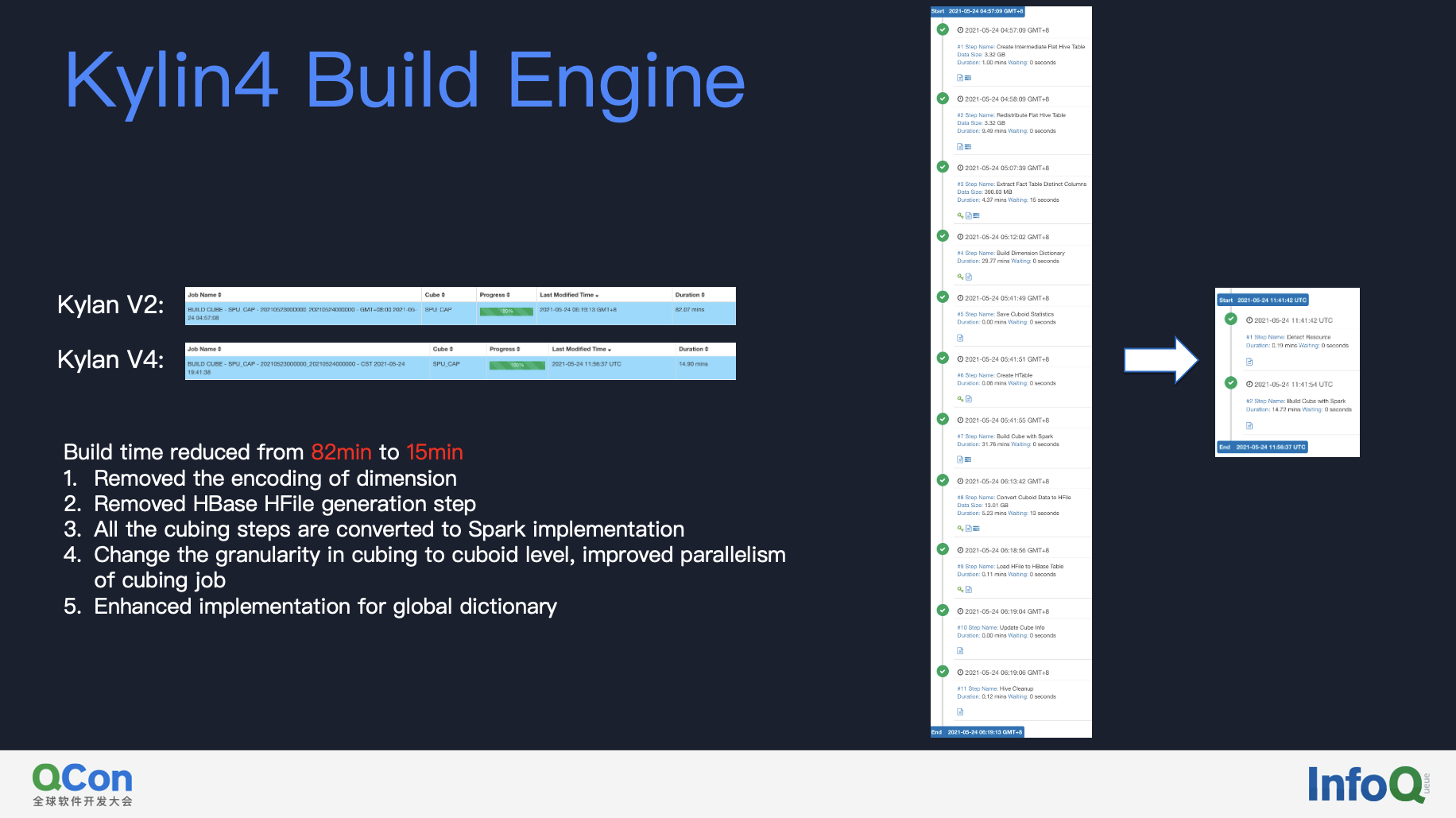
The second is the new build engine. Based on our test, the build speed of Kylin on Parquet has been optimized from 82 minutes to 15 minutes. There are several reasons:
- Kylin 4 removes the encoding of the dimension, eliminating a building step of encoding;
- Removed the HBase File generation step;
- Kylin on Parquet changes the granularity of cubing to cuboid level, which is conducive to further improving parallelism of cubing job.
- Enhanced implementation for global dictionary. In the new algorithm, dictionary and source data are hashed into the same buckets, making it possible for loading only piece of dictionary bucket to encode source data.
As you can see on the right, after upgradation to Kylin 4, cubing job changes from ten steps to two steps, the performance improvement of the construction is very obvious.
Query engine
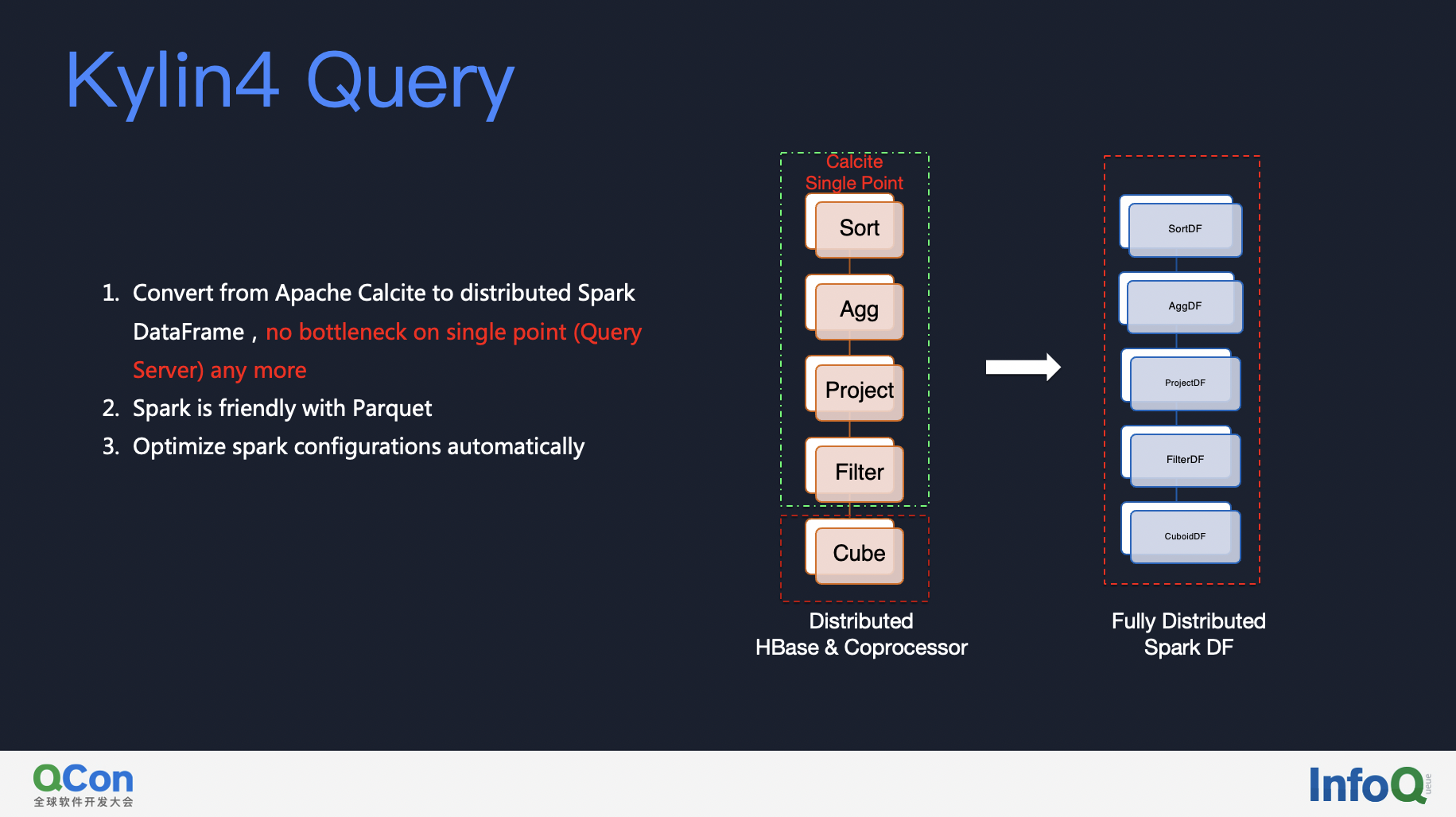
Next is the new query engine of Kylin 4. As you can see, the calculation of Kylin on HBase is completely dependent on the coprocessor of HBase and query server process. When the data is read from HBase into query server to do aggregation, sorting, etc, the bottleneck will be restricted by the single point of query server. But Kylin 4 is converted to a fully distributed query mechanism based on Spark, what’s more, it ‘s able to do configuration tuning automatically in spark query step !
03 How to optimize performance of Kylin 4
Next, I’d like to share some performance optimizations made by Youzan in Kylin 4.
Optimization of query engine
#### 1.Cache Calcite physical plan
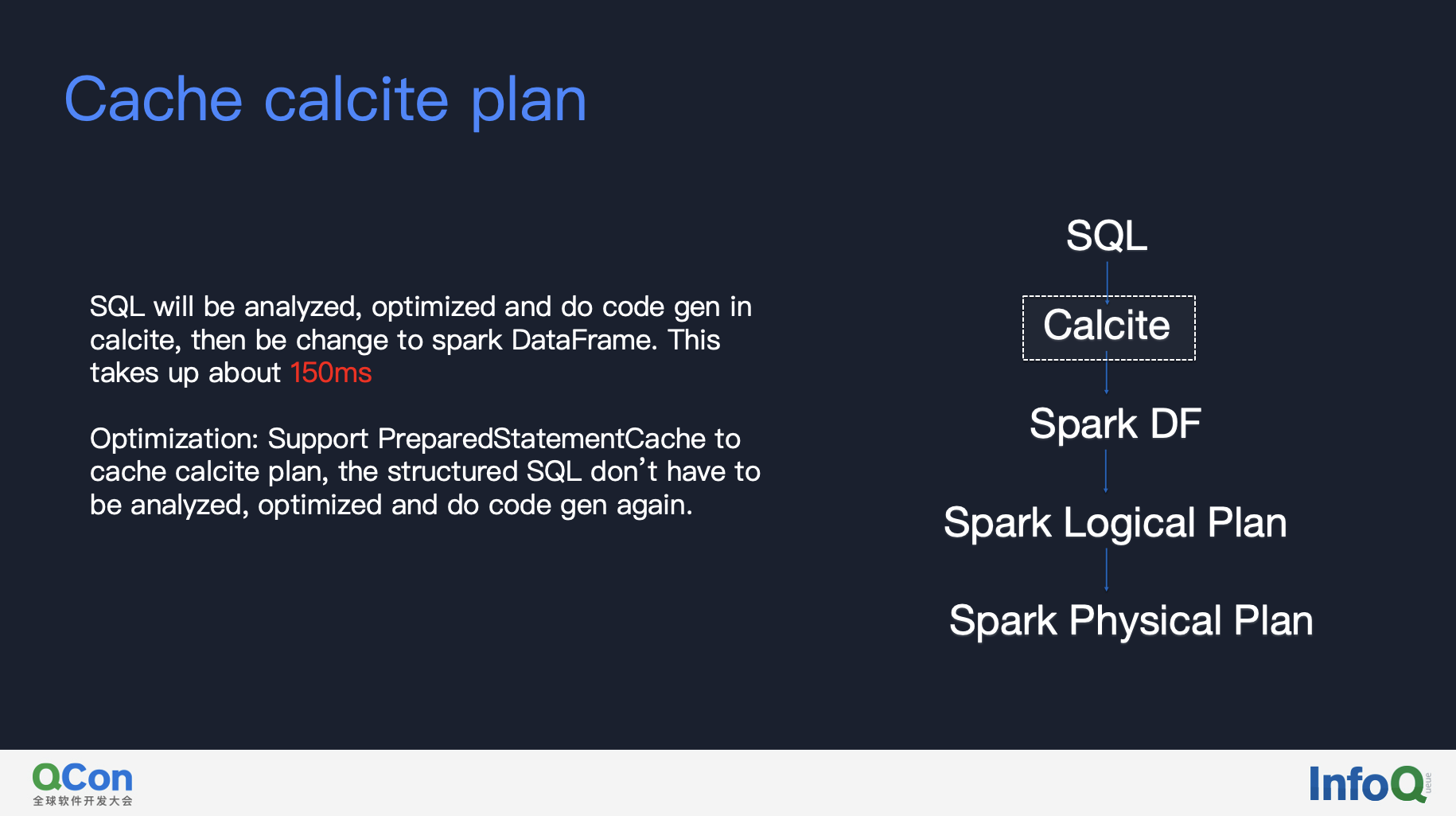
In Kylin4, SQL will be analyzed, optimized and do code generation in calcite. This step takes up about 150ms for some queries. We have supported PreparedStatementCache in Kylin4 to cache calcite plan, so that the structured SQL don’t have to do the same step again. With this optimization it saved about 150ms of time cost.
2.Tunning spark configuration

Kylin4 uses spark as query engine. As spark is a distributed engine designed for massive data processing, it’s inevitable to loose some performance for small queries. We have tried to do some tuning to catch up with the latency in Kylin on HBase for small queries.
Our first optimization is to make more calculations finish in memory. The key is to avoid data spill during aggregation, shuffle and sort. Tuning the following configuration is helpful.
- 1.set
spark.sql.objectHashAggregate.sortBased.fallbackThresholdto larger value to avoid HashAggregate fall back to Sort Based Aggregate, which really kills performance when happens. - 2.set
spark.shuffle.spill.initialMemoryThresholdto a large value to avoid to many spills during shuffle.
Secondly, we route small queries to Query Server which run spark in local mode. Because the overhead of task schedule, shuffle read and variable broadcast is enlarged for small queries on YARN/Standalone mode.
Thirdly, we use RAM disk to enhance shuffle performance. Mount RAM disk as TMPFS and set spark.local.dir to directory using RAM disk.
Lastly, we disabled spark’s whole stage code generation for small queries, for spark’s whole stage code generation will cost about 100ms~200ms, whereas it’s not beneficial to small queries which is a simple project.
3.Parquet optimization
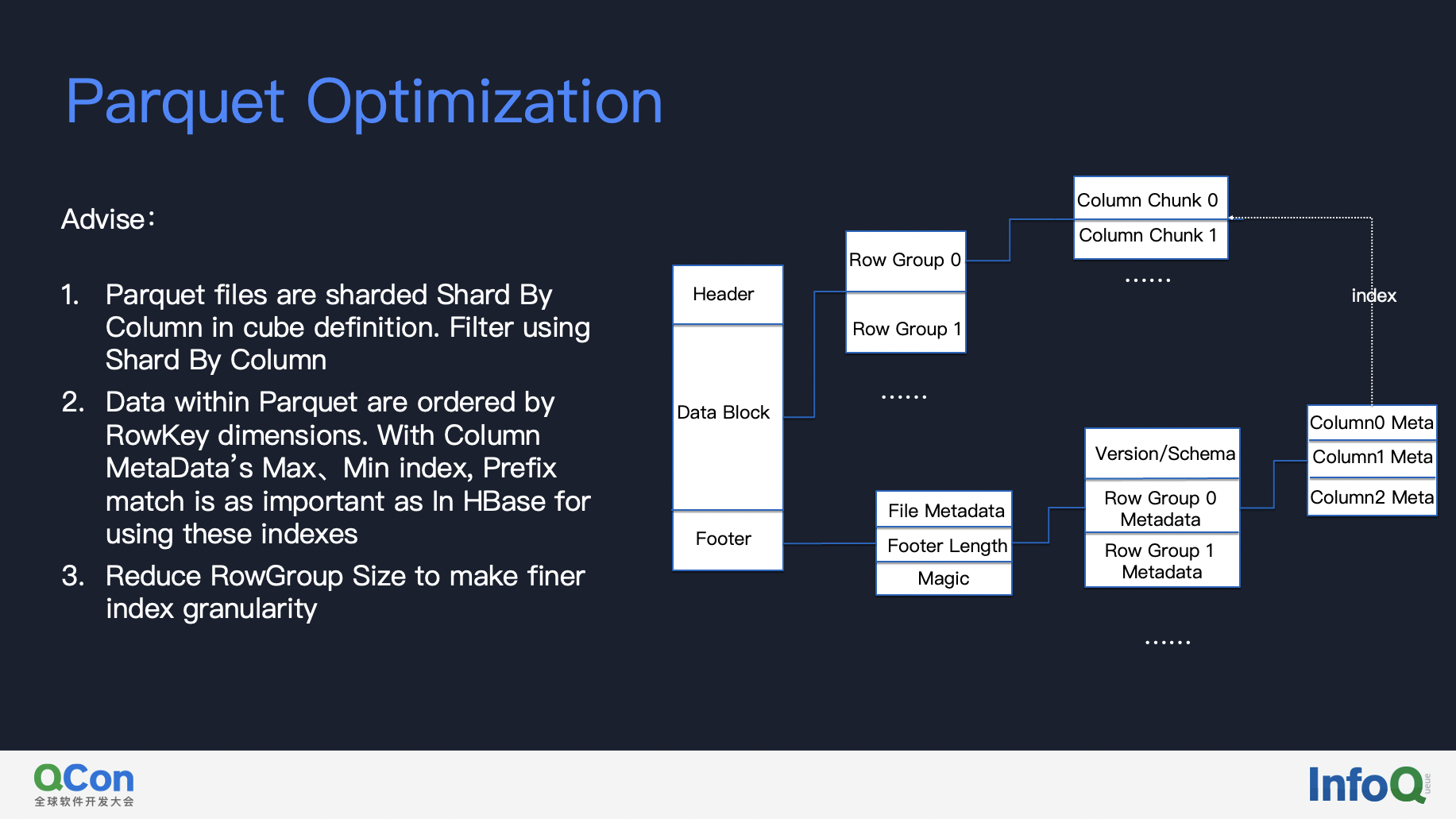
Optimizing parquet is also important for queries.
The first principal is that we’d better always include shard by column in our filter condition, for parquet files are shard by shard-by-column, filter using shard by column reduces the data files to read.
Then look into parquet files, data within files are sorted by rowkey columns, that is to say, prefix match in query is as important as Kylin on HBase. When a query condition satisfies prefix match, it can filter row groups with column’s max/min index. Furthermore, we can reduce row group size to make finer index granularity, but be aware that the compression rate will be lower if we set row group size smaller.
4.Dynamic elimination of partitioning dimensions
Kylin4 have a new ability that the older version is not capable of, which is able to reduce dozens of times of data reading and computing for some big queries. It’s offen the case that partition column is used to filter data but not used as group dimension. For those cases Kylin would always choose cuboid with partition column, but now it is able to use different cuboid in that query to reduce IO read and computing.
The key of this optimization is to split a query into two parts, one of the part uses all segment’s data so that partition column doesn’t have to be included in cuboid, the other part that uses part of segments data will choose cuboid with partition dimension to do the data filter.
We have tested that in some situations the response time reduced from 20s to 6s, 10s to 3s.

Optimization of build engine
#### 1.cache parent dataset

Kylin build cube layer by layer. For a parent layer with multi cuboids to build, we can choose to cache parent dataset by setting kylin.engine.spark.parent-dataset.max.persist.count to a number greater than 0. But notice that if you set this value too small, it will affect the parallelism of build job, as the build granularity is at cuboid level.
04 Practice of Kylin 4 in Youzan
After introducing Youzan’s experience of performance optimization, let’s share the optimization effect. That is, Kylin 4’s practice in Youzan includes the upgrade process and the performance of online system.
Upgrade metadata to adapt to Kylin 4
First of all, for metadata for Kylin 3 which stored on HBase, we have developed a tool for seamless upgrading of metadata. First of all, our metadata in Kylin on HBase is stored in HBase. We export the metadata in HBase into local files, and then use tools to transform and write back the new metadata into MySQL. We also updated the operation documents and general principles in the official wiki of Apache Kylin. For more details, you can refer to: How to migrate metadata to Kylin 4.
Let’s give a general introduction to some compatibility in the whole process. The project metadata, tables metadata, permission-related metadata, and model metadata do not need be modified. What needs to be modified is the cube metadata, including the type of storage and query used by Cube. After updating these two fields, you need to recalculate the Cube signature. The function of this signature is designed internally by Kylin to avoid some problems caused by Cube after Cube is determined.
Performance of Kylin 4 on Youzan online system

After the migration of metadata to Kylin4, let’s share the qualitative changes and substantial performance improvements brought about by some of the promising scenarios. First of all, in a scenario like Commodity Insight, there is a large store with several hundred thousand of commodities. We have to analyze its transactions and traffic, etc. There are more than a dozen precise precisely count distinct measures in single cube. Precisely count distinct measure is actually very inefficient if it is not optimized through pre-calculation and Bitmap. Kylin currently uses Bitmap to support precisely count distinct measure. In a scene that requires complex queries to sort hundreds of thousands of commodities in various UV(precisely count distinct measure), the RT of Kylin 2 is 27 seconds, while the RT of Kylin 4 is reduced from 27 seconds to less than 2 seconds.
What I find most appealing to me about Kylin 4 is that it’s like a manual transmission car, you can control its query concurrency at your will, whereas you can’t change query concurrency in Kylin on HBase freely, because its concurrency is completely tied to the number of regions.
Plan for Kylin 4 in Youzan
We have made full test, fixed several bugs and improved apache KYLIN4 for several months. Now we are migrating cubes from older version to newer version. For the cubes already migrated to KYLIN4, its small queries’ performance meet our expectations, its complex query and build performance did bring us a big surprise. We are planning to migrate all cubes from older version to Kylin4.