
Get Your Interactive Analytics Superpower, with Apache Kylin and Apache Superset
Challenge of Big Data
In the big data era, all enterprises’ face the growing demand and challenge of processing large volumes of data—workloads that traditional legacy systems can no longer satisfy. With the emergence of Artificial Intelligence (AI) and Internet-of-Things (IoT) technology, it has become mission-critical for businesses to accelerate their pace of discovering valuable insights from their massive and ever-growing datasets. Thus, large companies are constantly searching for a solution, often turning to open source technologies. We will introduce two open source technologies that, when combined together, can meet these pressing big data demands for large enterprises.
Apache Kylin: a Leading OpenSource OLAP-on-Hadoop
Modern organizations have had a long history of applying Online Analytical Processing (OLAP) technology to analyze data and uncover business insights. These insights help businesses make informed decisions and improve their service and product. With the emergence of the Hadoop ecosystem, OLAP has also embraced new technologies in the big data era.
Apache Kylin is one such technology that directly addresses the challenge of conducting analytical workloads on massive datasets. It is already widely adopted by enterprises around the world. With powerful pre-calculation technology, Apache Kylin enables sub-second query latency over petabyte-scale datasets. The innovative and intricate design of Apache Kylin allows it to seamlessly consume data from any Hadoop-based data source, as well as other relational database management system (RDBMS). Analysts can use Apache Kylin using standard SQL through ODBC, JDBC, and Restful API, which enables the platform to integrate with any third-party applications.
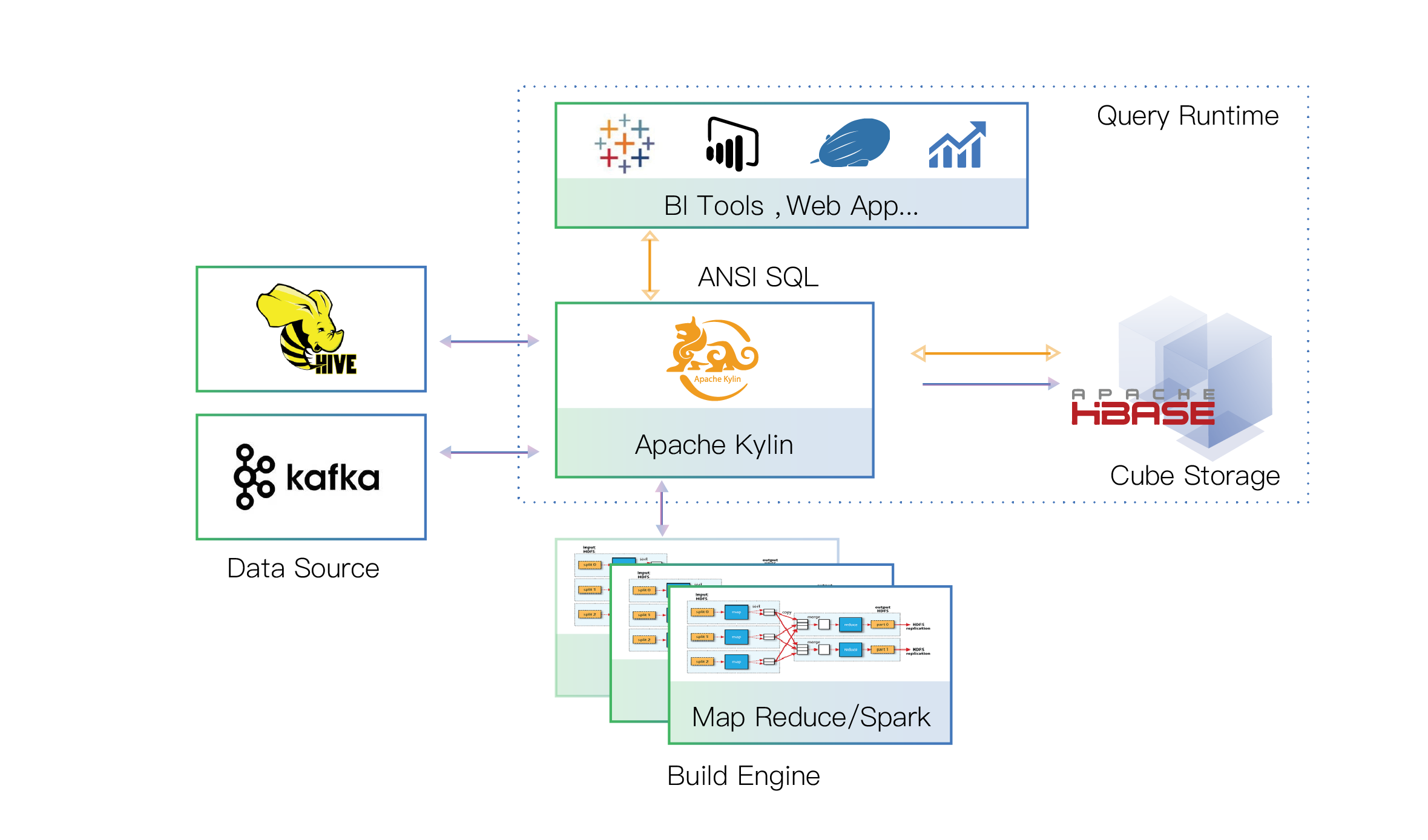
Figure 1: Apache Kylin Architecture
In a fast-paced and rapidly-changing business environment, business users and analysts are expected to uncover insights with speed of thoughts. They can meet this expectation with Apache Kylin, and no longer subjected to the predicament of waiting for hours for one single query to return results. Such a powerful data processing engine empowers the data scientists, engineers, and business analysts of any enterprise to find insights to help reach critical business decisions. However, business decisions cannot be made without rich data visualization. To address this last-mile challenge of big data analytics, Apache Superset comes into the picture.
Apache Superset: Modern, Enterprise-ready Business Intelligence Platform
Apache Superset is a data exploration and visualization platform designed to be visual, intuitive, and interactive. A user can access data in the following two ways:
-
Access data from the following commonly used data sources one table at a time: Kylin, Presto, Hive, Impala, SparkSQL, MySQL, Postgres, Oracle, Redshift, SQL Server, Druid.
-
Use a rich SQL Interactive Development Environment (IDE) called SQL Lab that is designed for power users with the ability to write SQL queries to analyze multiple tables.
Users can immediately analyze and visualize their query results using Apache Superset ‘s rich visualization and reporting features.
![]()
Figure 2
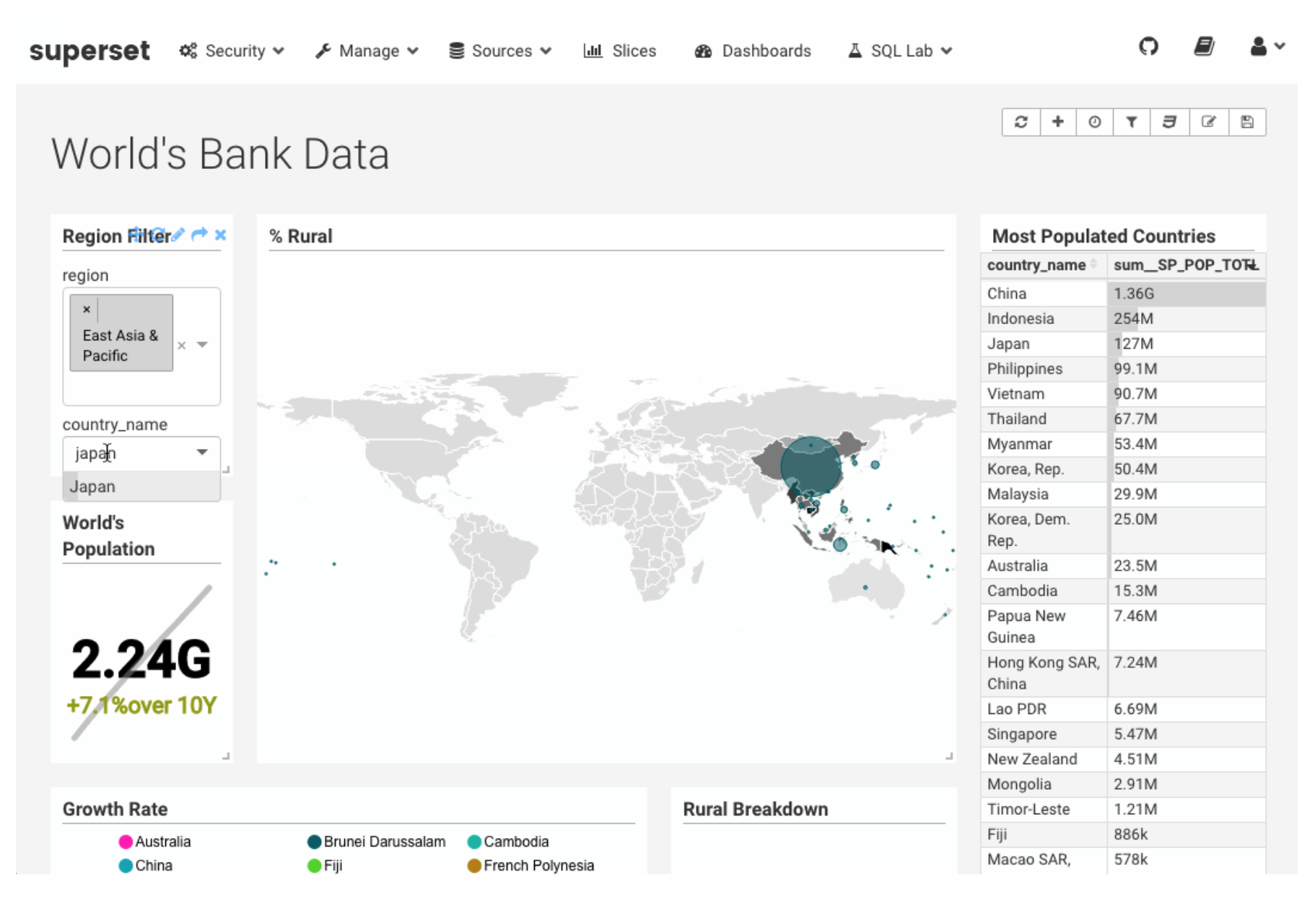
Figure 3: Apache Superset Visualization Interface
Integrating Apache Kylin and Apache Superset to Boost Your Productivity
Both Apache Kylin and Apache Superset are built to provide fast and interactive analytics for their users. The combination of these two open source projects can bring that goal to reality on petabyte-scale datasets, thanks to pre-calculated Kylin Cube.
The Kyligence Data Science team has recently open sourced kylinpy, a project that makes this combination possible. Kylinpy is a Python-based Apache Kylin client library. Any application that uses SQLAlchemy can now query Apache Kylin with this library installed, specifically Apache Superset. Below is a brief tutorial that shows how to integrate Apache Kylin and Apache Superset.
Prerequisite
- Install Apache Kylin
Please refer to this installation tutorial. - Apache Kylin provides a script for you to create a sample Cube. After you successfully installed Apache Kylin, you can run the below script under Apache Kylin installation directory to generate sample project and Cube.
./${KYLIN_HOME}/bin/sample.sh -
When the script finishes running, log onto Apache Kylin web with default user ADMIN/KYLIN; in the system page click “Reload Metadata,” then you will see a sample project called “Learn Kylin.”
- Select the sample cube “kylin_sales_cube”, click “Actions” -> “Build”, pick a date later than 2014-01-01 (to cover all 10000 sample records);
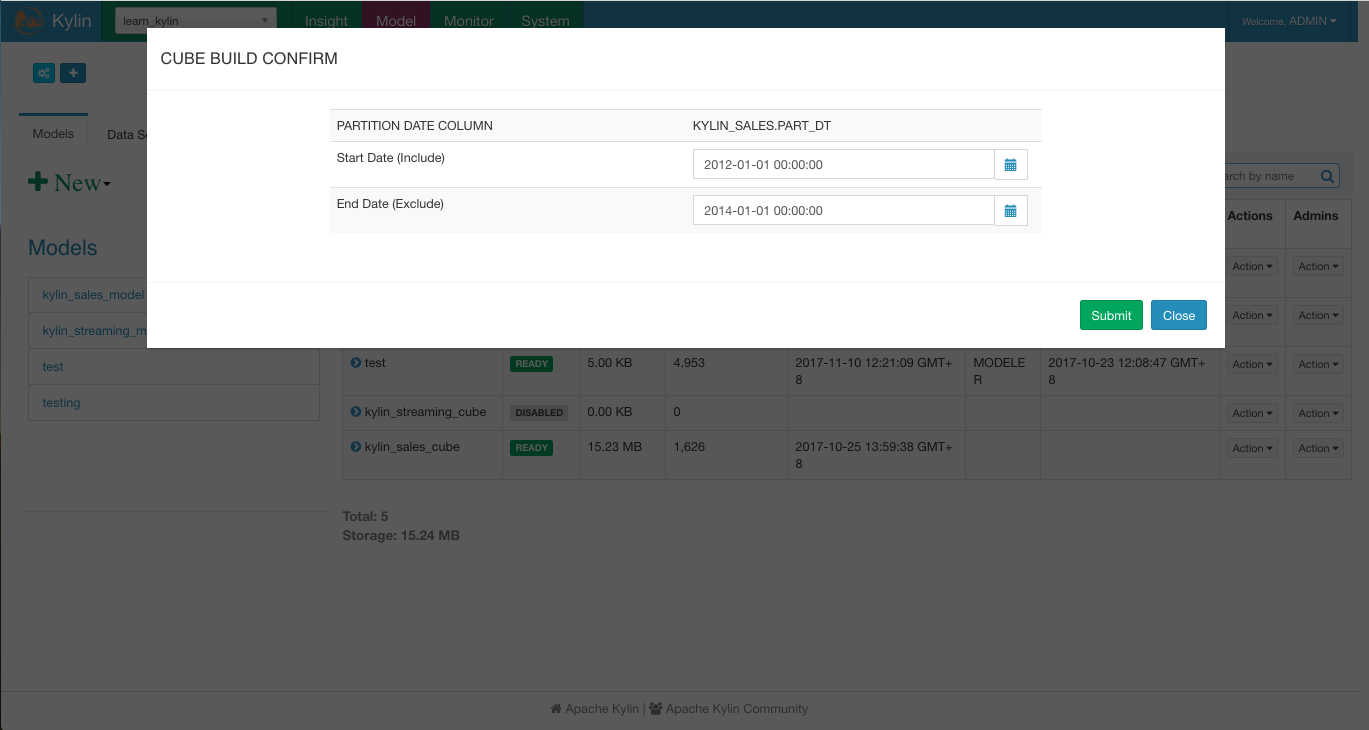
Figure 4: Build Cube in Apache Kylin
- Check the build progress in “Monitor” tab until it reaches 100%;
- Execute SQL in the “Insight” tab, for example:
select part_dt,
sum(price) as total_selled,
count(distinct seller_id) as sellers
from kylin_sales
group by part_dt
order by part_dt
-- #This query will hit on the newly built Cube “Kylin_sales_cube”.
- Next, we will install Apache Superset and initialize it.
You may refer to Apache Superset official website instruction to install and initialize. - Install kylinpy
$ pip install kylinpy
- Verify your installation, if everything goes well, Apache Superset daemon should be up and running.
$ superset runserver -d
Starting server with command:
gunicorn -w 2 --timeout 60 -b 0.0.0.0:8088 --limit-request-line 0 --limit-request-field_size 0 superset:app
[2018-01-03 15:54:03 +0800] [73673] [INFO] Starting gunicorn 19.7.1
[2018-01-03 15:54:03 +0800] [73673] [INFO] Listening at: http://0.0.0.0:8088 (73673)
[2018-01-03 15:54:03 +0800] [73673] [INFO] Using worker: sync
[2018-01-03 15:54:03 +0800] [73676] [INFO] Booting worker with pid: 73676
[2018-01-03 15:54:03 +0800] [73679] [INFO] Booting worker with pid: 73679
Connect Apache Kylin from ApacheSuperset
Now everything you need is installed and ready to go. Let’s try to create an Apache Kylin data source in Apache Superset.
1. Open up http://localhost:8088 in your web browser with the credential you set during Apache Superset installation.
Figure 5: Apache Superset Login Page
- Go to Source -> Datasource to configure a new data source.
- SQLAlchemy URI pattern is : kylin://<username>:<password>@<hostname>:<port>/<project name>
- Check “Expose in SQL Lab” if you want to expose this data source in SQL Lab.
- Click “Test Connection” to see if the URI is working properly.
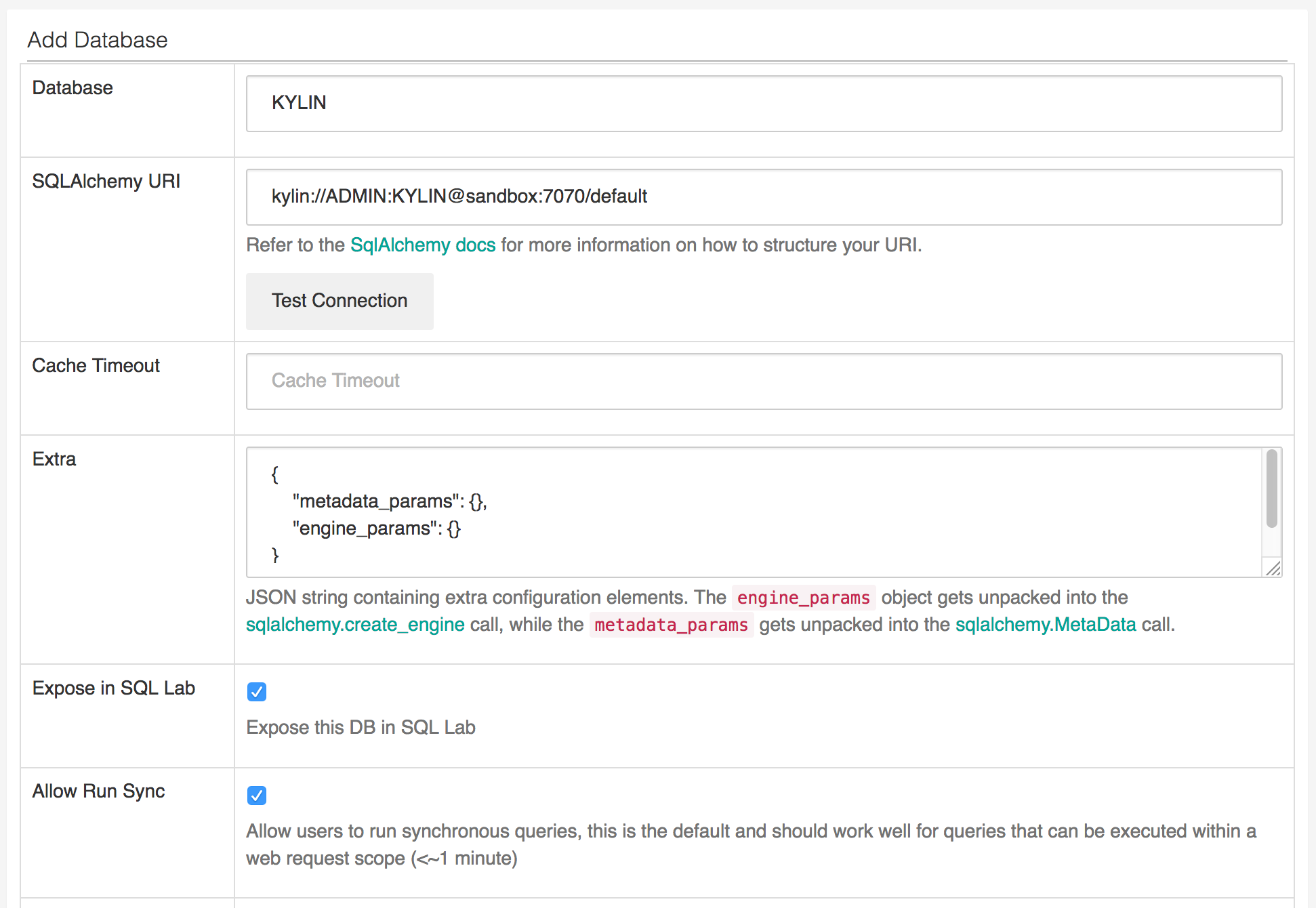
Figure 6: Create an Apache Kylin data source
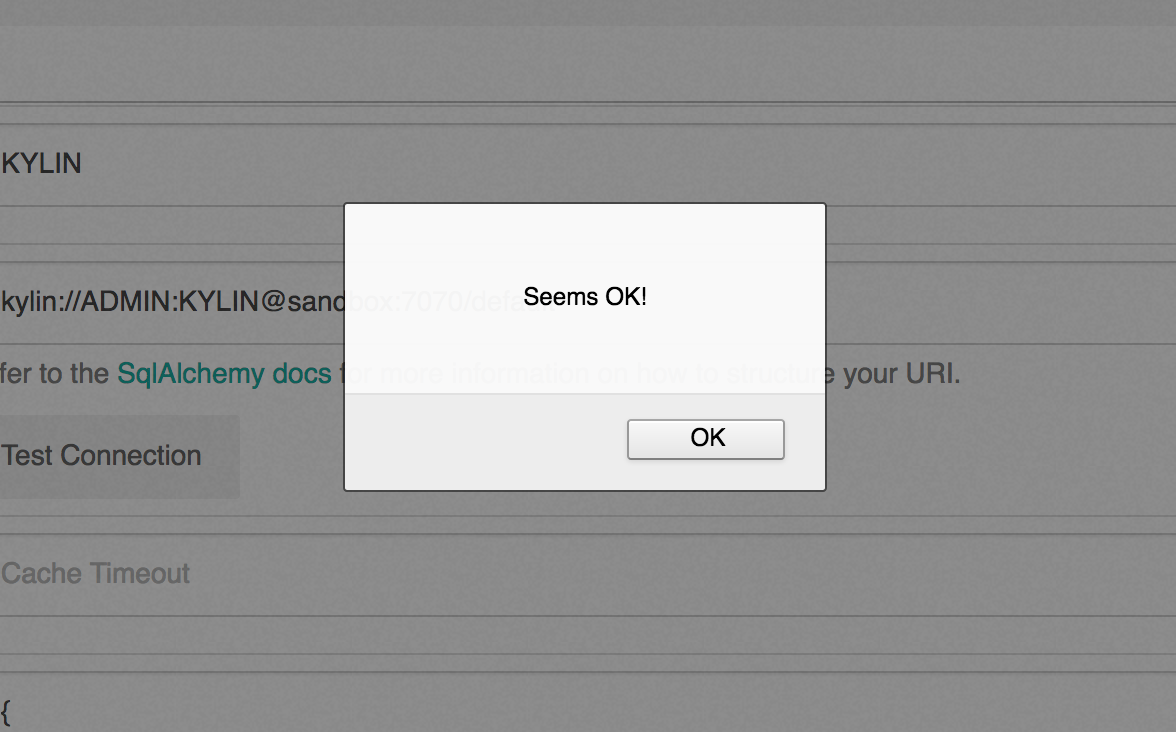
Figure 7: Test Connection to Apache Kylin
If the connection to Apache Kylin is successful, you will see all the tables from Learn_kylin project show up at the bottom of the connection page.
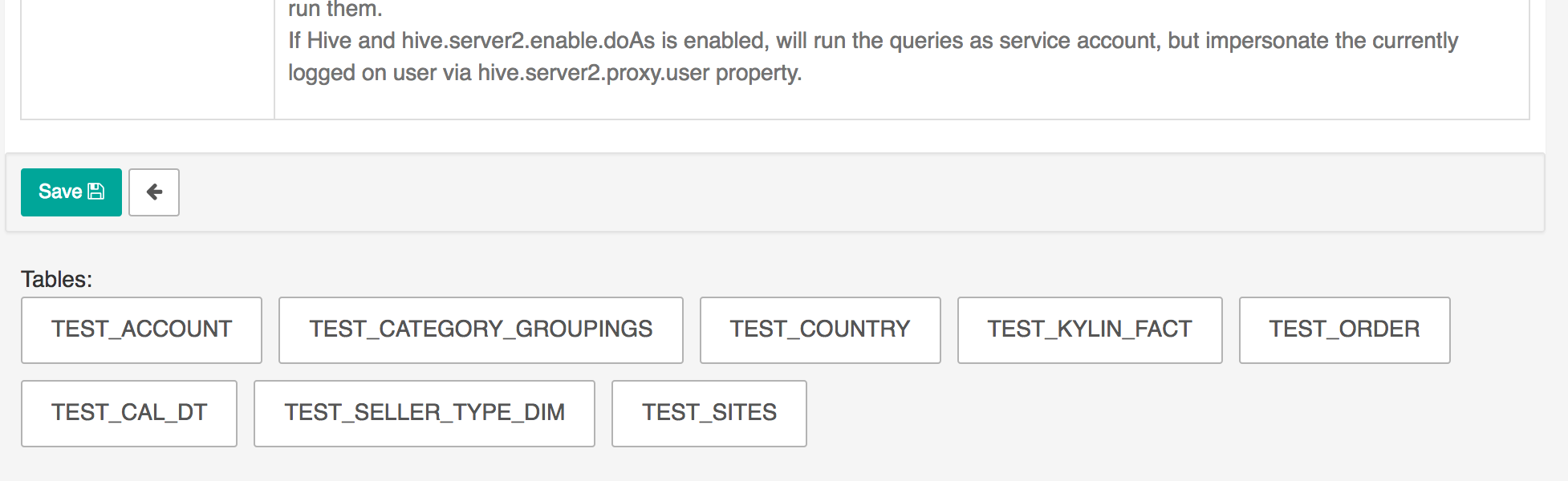
Figure 8: Tables will show up if connection is successful
Query Kylin Table
- Go to Source -> Tables to add a new table, type in a table name from “Learn_kylin” project, for example, “Kylin_sales”.
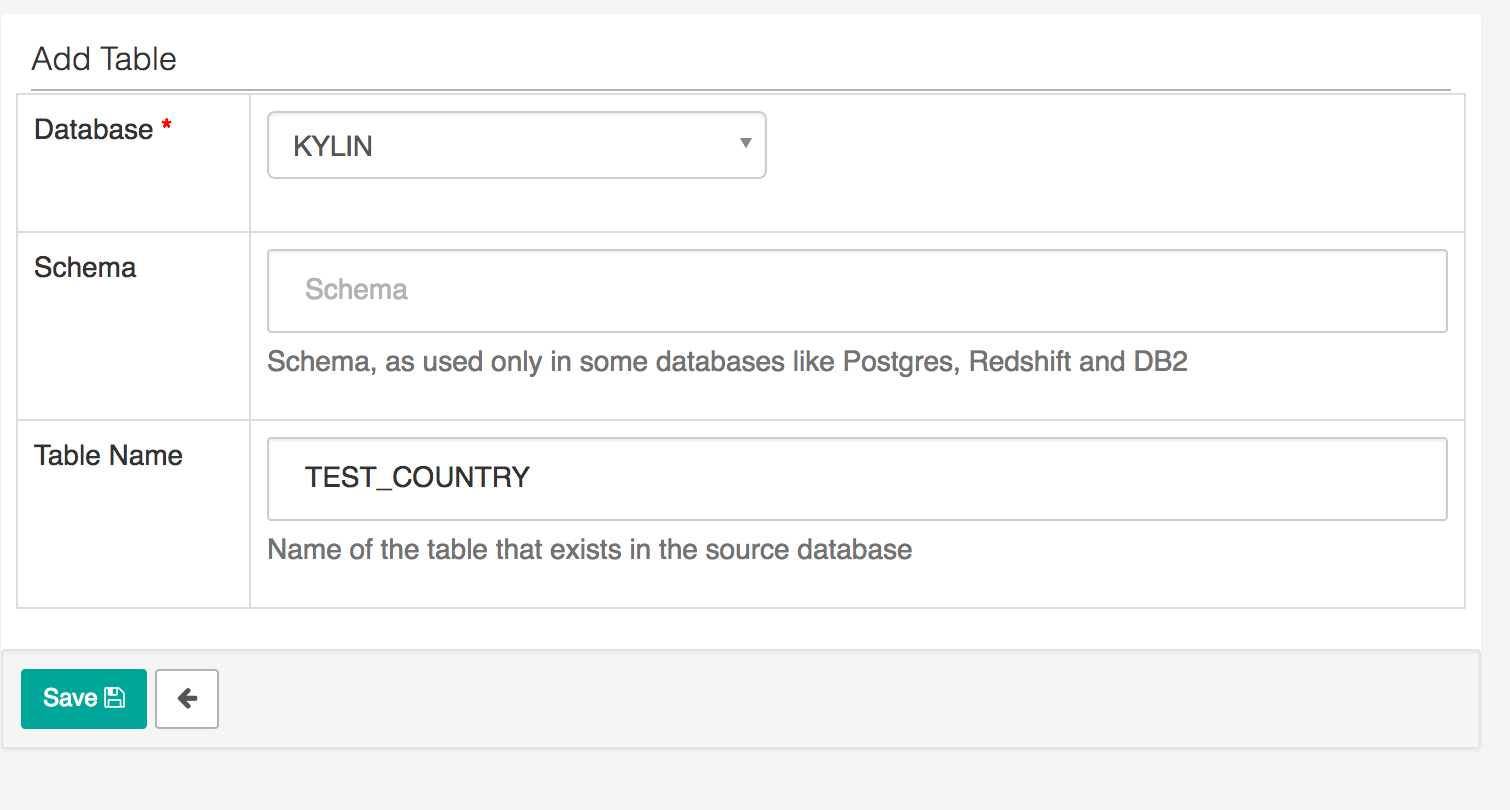
Figure 9 Add Kylin Table in Apache Superset
- Click on the table you created. Now you are ready to analyze your data from Apache Kylin.
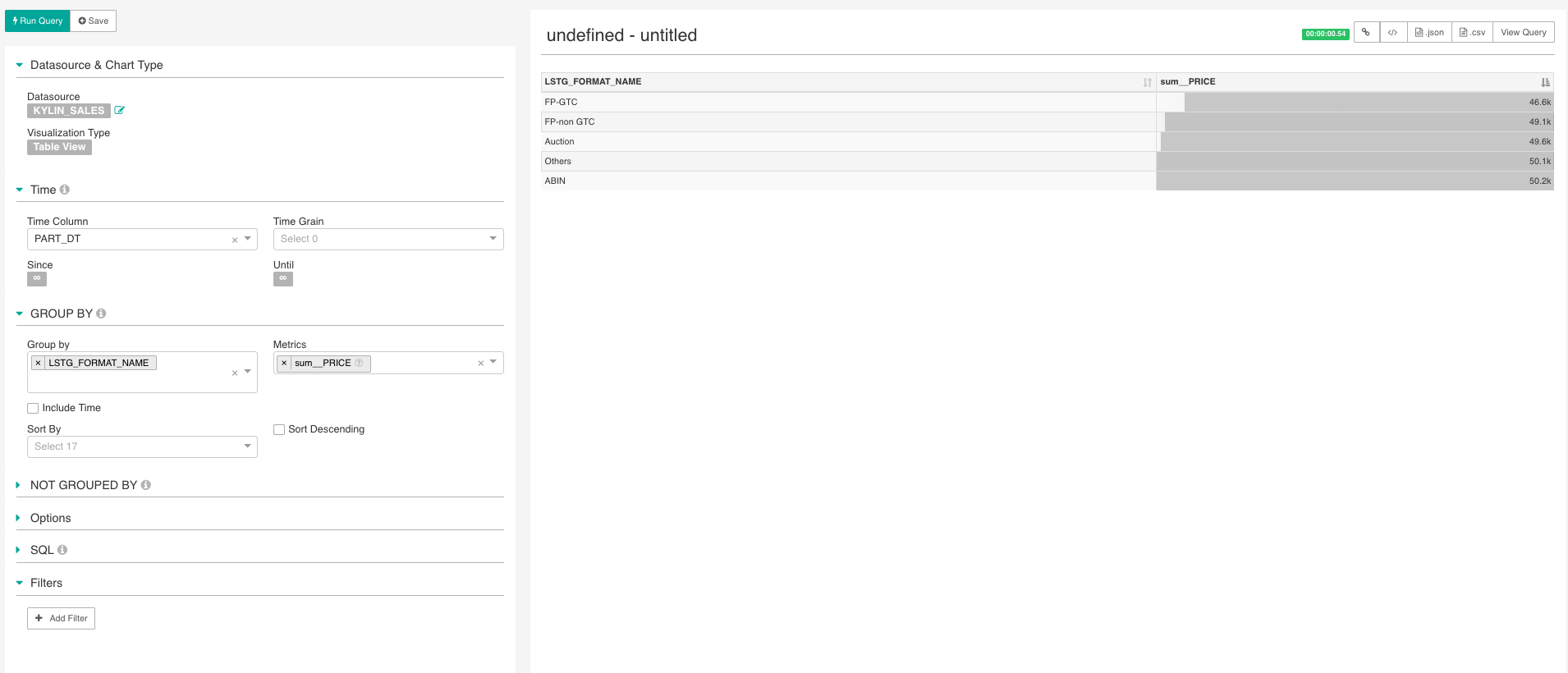
Figure 10 Query single table from Apache Kylin
Query Multiple Tables from Kylin Using SQL Lab.
Kylin Cube is usually based on a data model joined by multiples tables. Thus, it is quite common to query multiple tables at the same time using Apache Kylin. In Apache Superset, you can use SQL Lab to join your data across tables by composing SQL queries. We will use a query that can hit on the sample cube “kylin_sales_cube” as an example.
When you run your query in SQL Lab, the result will come from the data source, in this case, Apache Kylin.
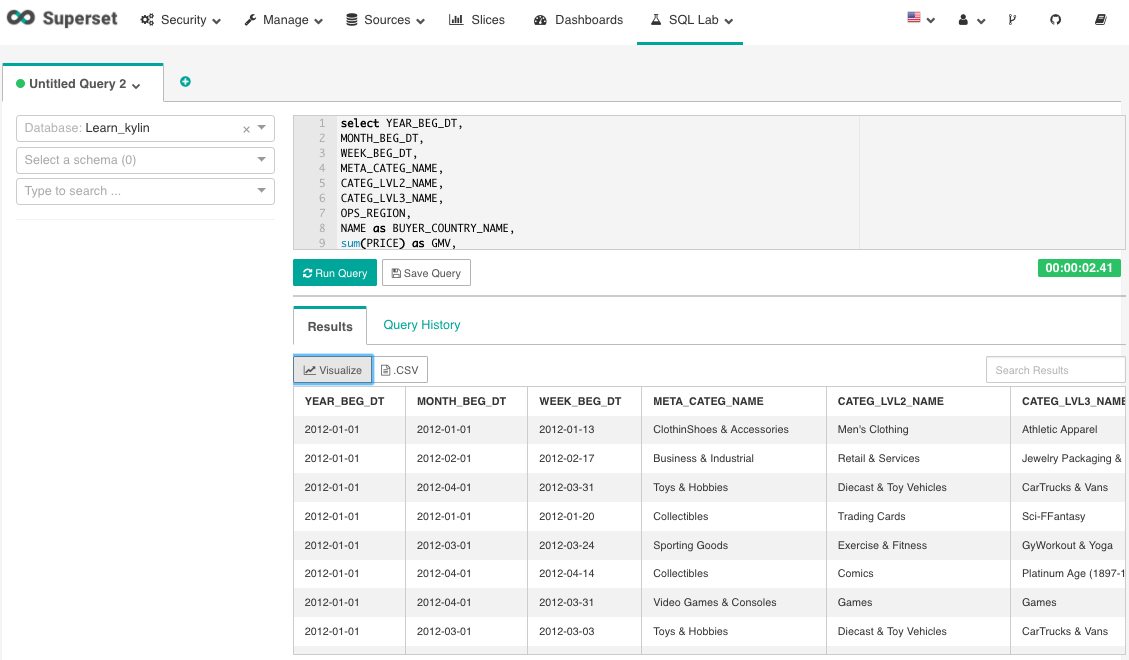
Figure 11 Query multiple tables from Apache Kylin using SQL Lab
When the query returns results, you may immediately visualize them by clicking on the “Visualize” button.
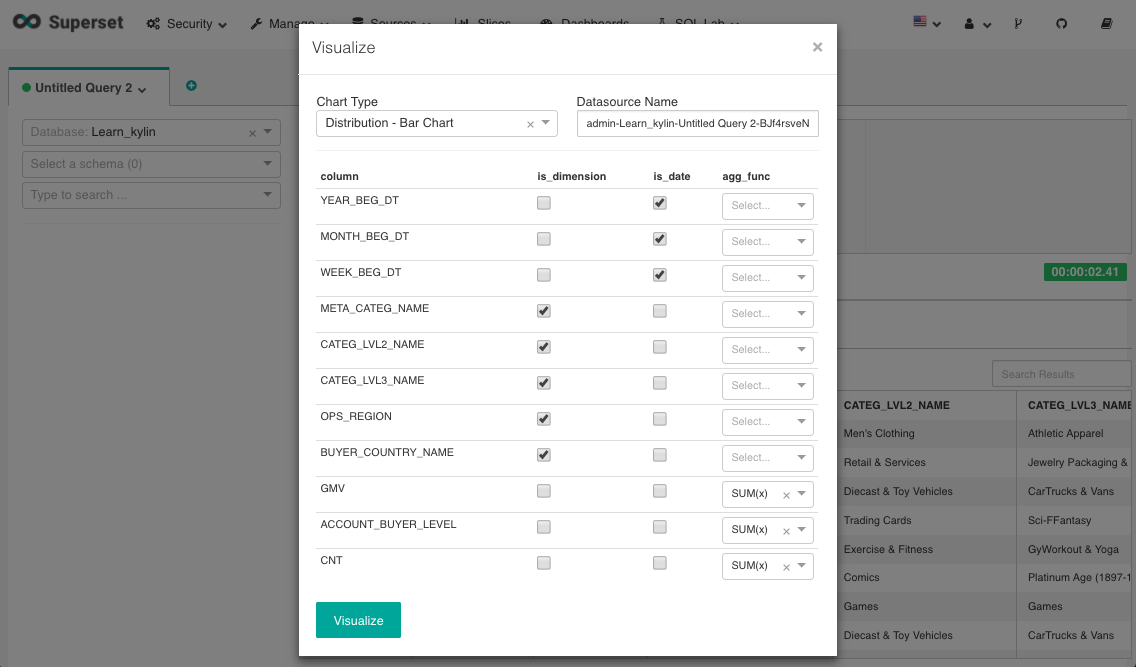
Figure 12 Define your query and visualize it immediately
You may copy the entire SQL below to experience how you can query Kylin Cube in SQL Lab.
select
YEAR_BEG_DT,
MONTH_BEG_DT,
WEEK_BEG_DT,
META_CATEG_NAME,
CATEG_LVL2_NAME,
CATEG_LVL3_NAME,
OPS_REGION,
NAME as BUYER_COUNTRY_NAME,
sum(PRICE) as GMV,
sum(ACCOUNT_BUYER_LEVEL) ACCOUNT_BUYER_LEVEL,
count(*) as CNT
from KYLIN_SALES
join KYLIN_CAL_DT on CAL_DT=PART_DT
join KYLIN_CATEGORY_GROUPINGS on SITE_ID=LSTG_SITE_ID and KYLIN_CATEGORY_GROUPINGS.LEAF_CATEG_ID=KYLIN_SALES.LEAF_CATEG_ID
join KYLIN_ACCOUNT on ACCOUNT_ID=BUYER_ID
join KYLIN_COUNTRY on ACCOUNT_COUNTRY=COUNTRY
group by YEAR_BEG_DT, MONTH_BEG_DT,WEEK_BEG_DT,META_CATEG_NAME,CATEG_LVL2_NAME, CATEG_LVL3_NAME, OPS_REGION, NAME
## Experience All Features in Apache Superset with Apache Kylin
Most of the common reporting features are available in Apache Superset. Now let’s see how we can use those features to analyze data from Apache Kylin.
Sorting
You may sort by a measure regardless of how it is visualized.
You may specify a “Sort By” measure or sort the measure on the visualization after the query returns.
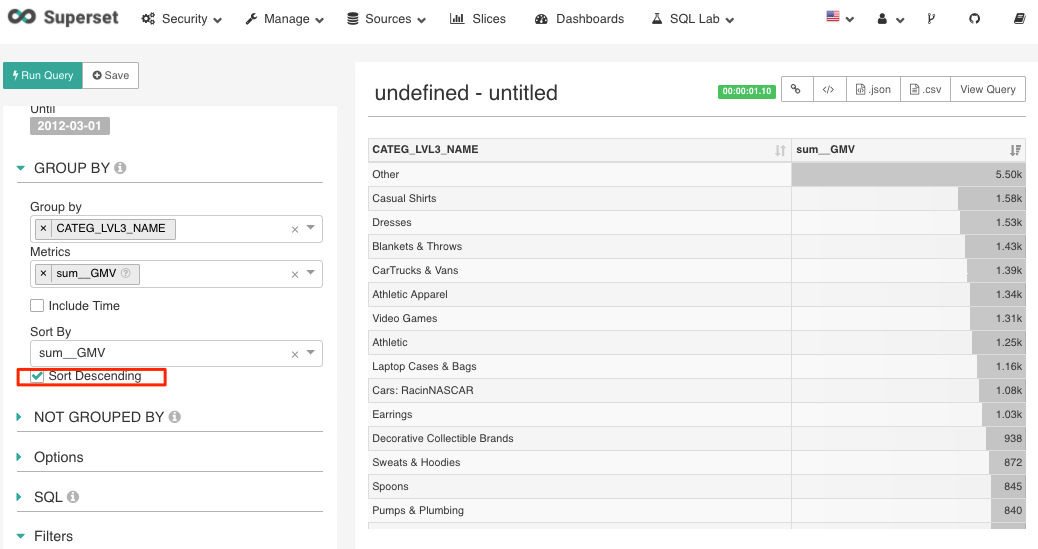
Figure 13 Sort by
Filtering
There are multiple ways you may filter data from Apache Kylin.
1. Date Filter
You may filter date and time dimension with the calendar filter.
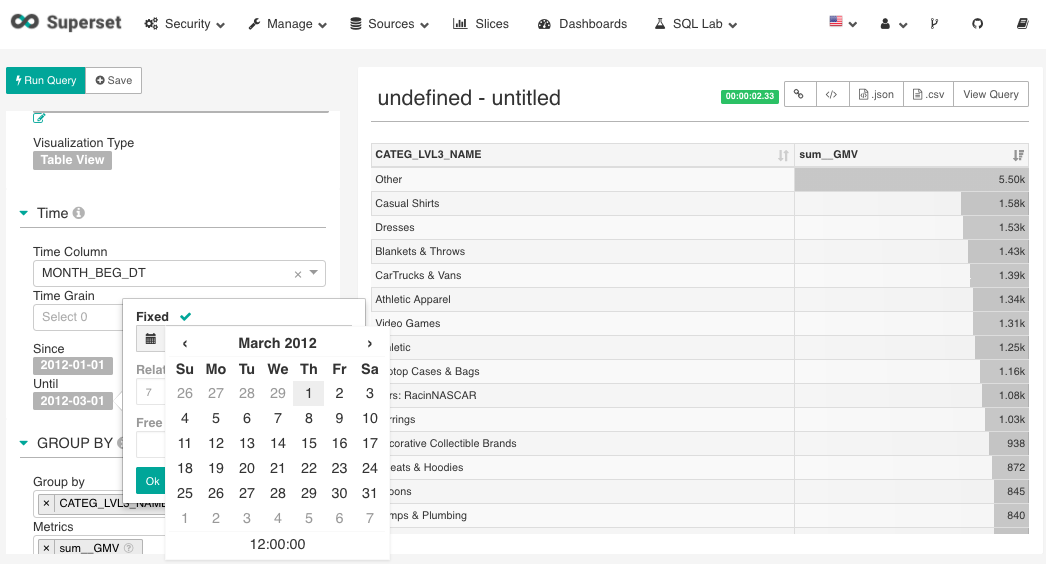
Figure 14 Filtering time
-
Dimension Filter
For other dimensions, you may filter it with SQL conditions like “in, not in, equal to, not equal to, greater than and equal to, smaller than and equal to, greater than, smaller than, like”.
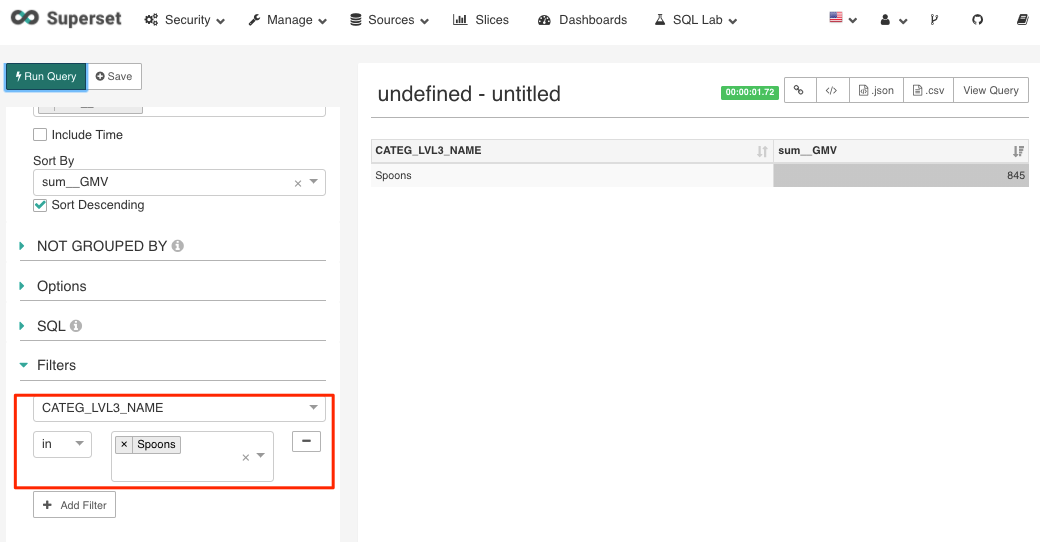
Figure 15 Filtering dimension -
Search Box
In some visualizations, it is also possible to further narrow down your result set after the query is returned from the data source using the “Search Box”.
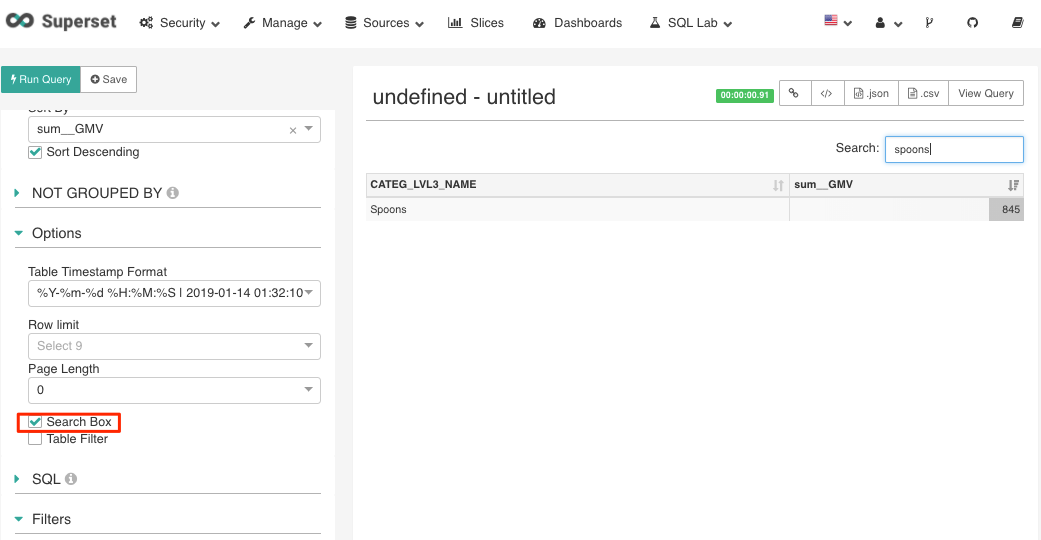
Figure 16 Search Box -
Filtering the measure
Apache Superset allows you to write a “having clause” to filtering the measure.
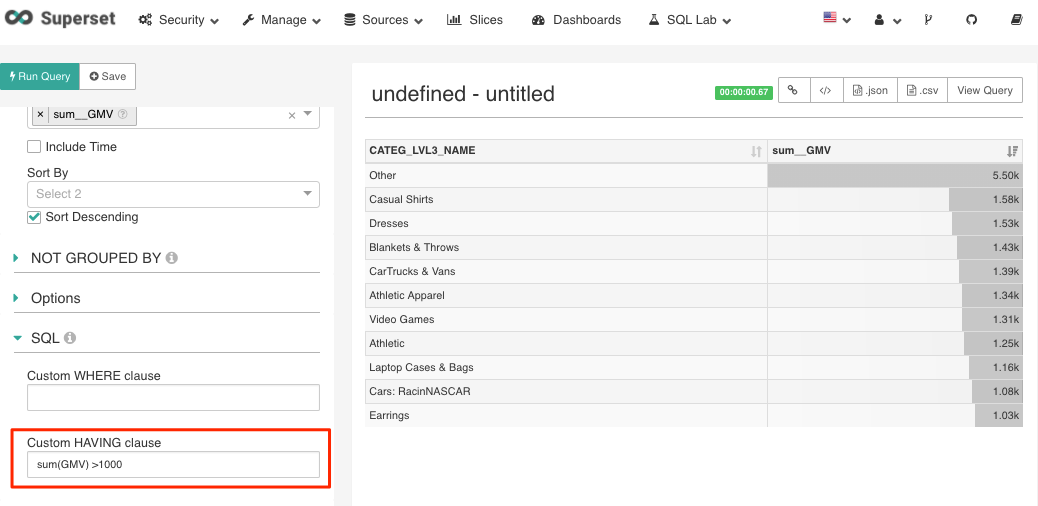
Figure 17 Filtering measure -
Filter Box
The filter box visualization allows you to create a drop-down style filter that can filter all slices on a dashboard dynamically
As the screenshot below shows, if you filter the CATE_LVL2_NAME dimension from the filter box, all the visualizations on this dashboard will be filtered based on your selection.
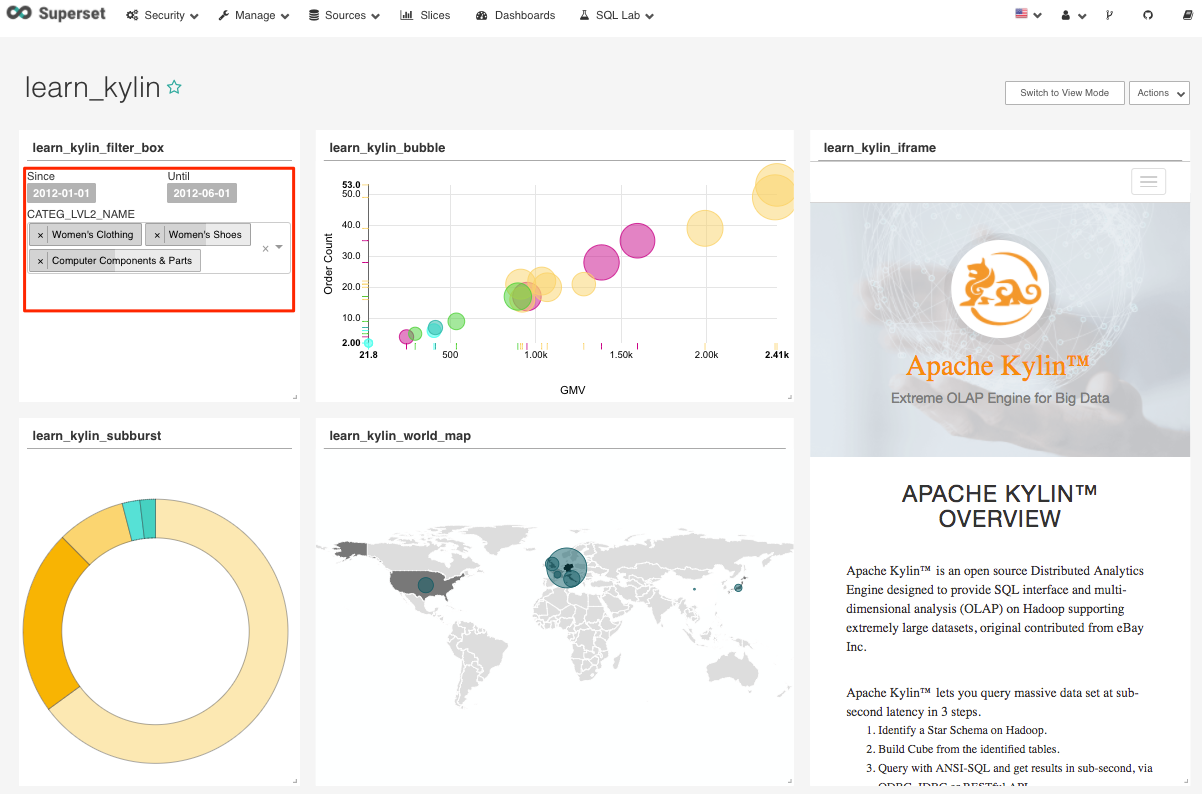
Figure 18 The filter box visualization
Top-N
To provide higher performance in query time for Top N query, Apache Kylin provides approximate Top N measure to pre-calculate the top records. In Apache Superset, you may use both “Sort By” and “Row Limit” feature to make sure your query can utilize the Top N pre-calculation from Kylin Cube.
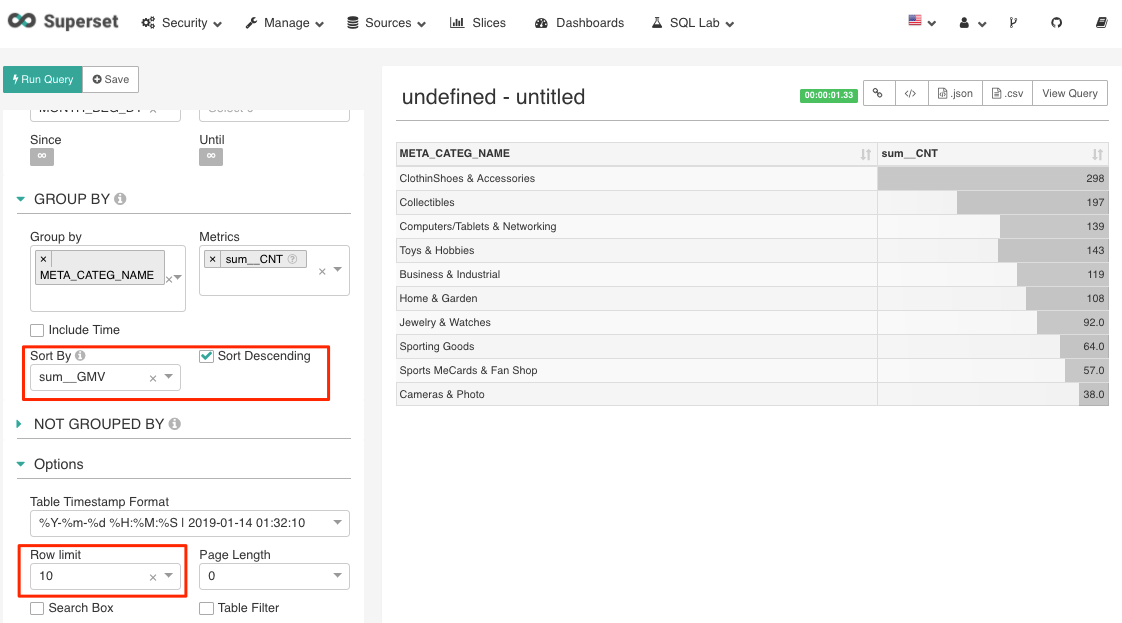
Figure 19 use both “Sort By” and “Row Limit” to get Top 10
Page Length
Apache Kylin users usually need to deal with high cardinality dimension. When displaying a high cardinality dimension, the visualization will display too many distinct values, taking a long time to render. In that case, it is nice that Apache Superset provides the page length feature to limit the number of rows per page. This way the up-front rendering effort can be reduced.
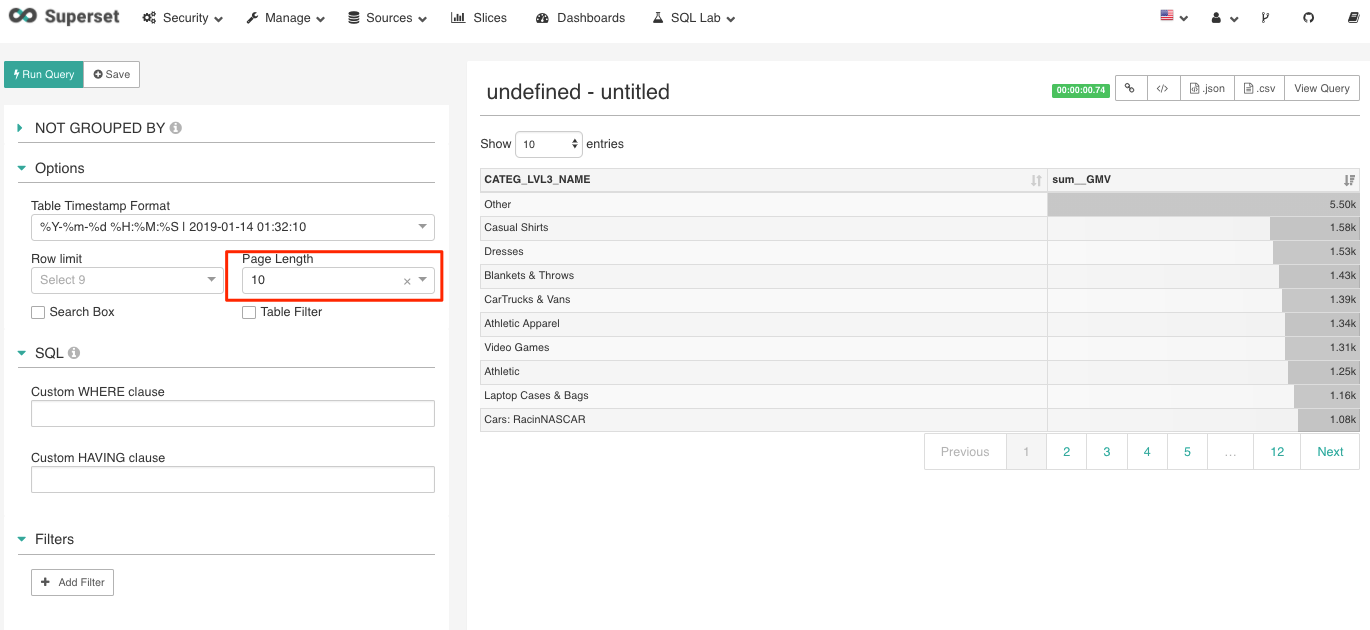
Figure 20 Limit page length
Visualizations
Apache Superset provides a rich and extensive set of visualizations. From basic charts like a pie chart, bar chart, line chart to advanced visualizations, like a sunburst, heatmap, world map, Sankey diagram.
Figure 21
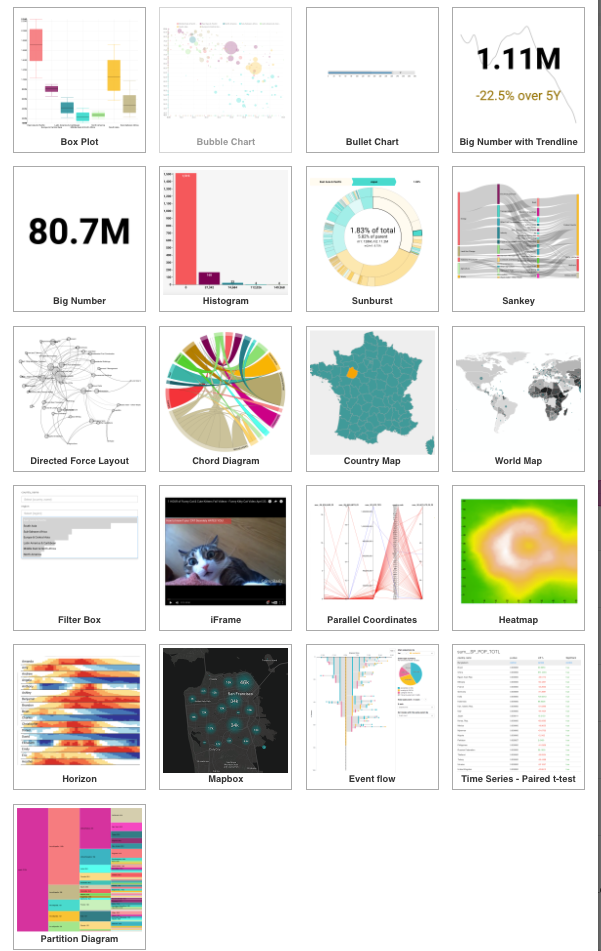
Figure 22
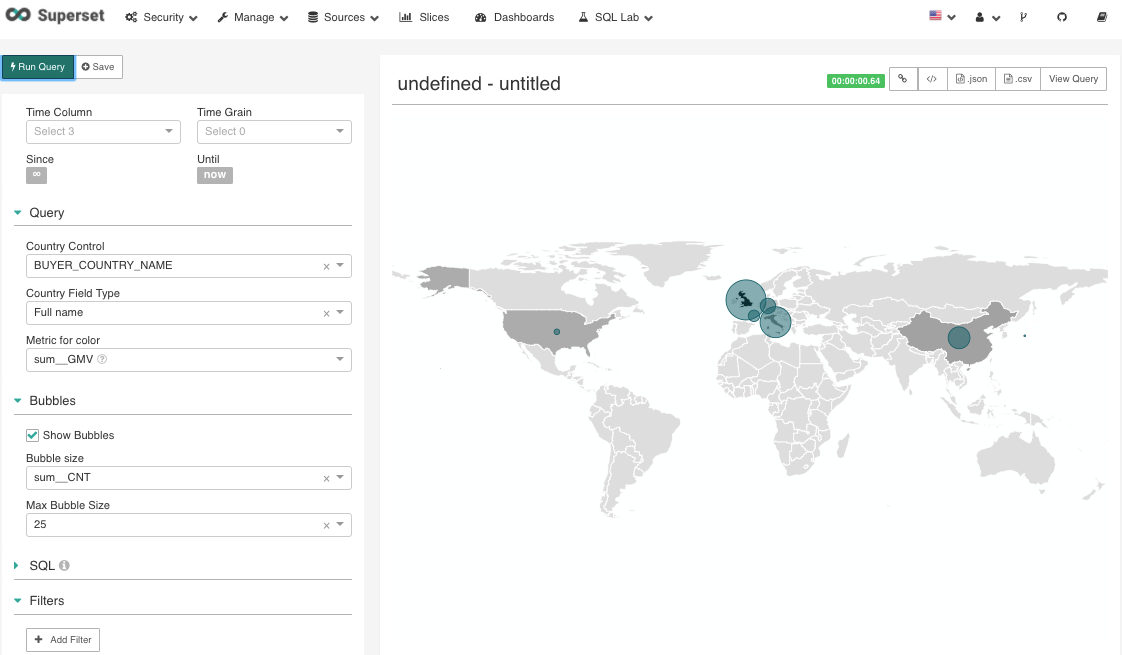
Figure 23 World map visualization
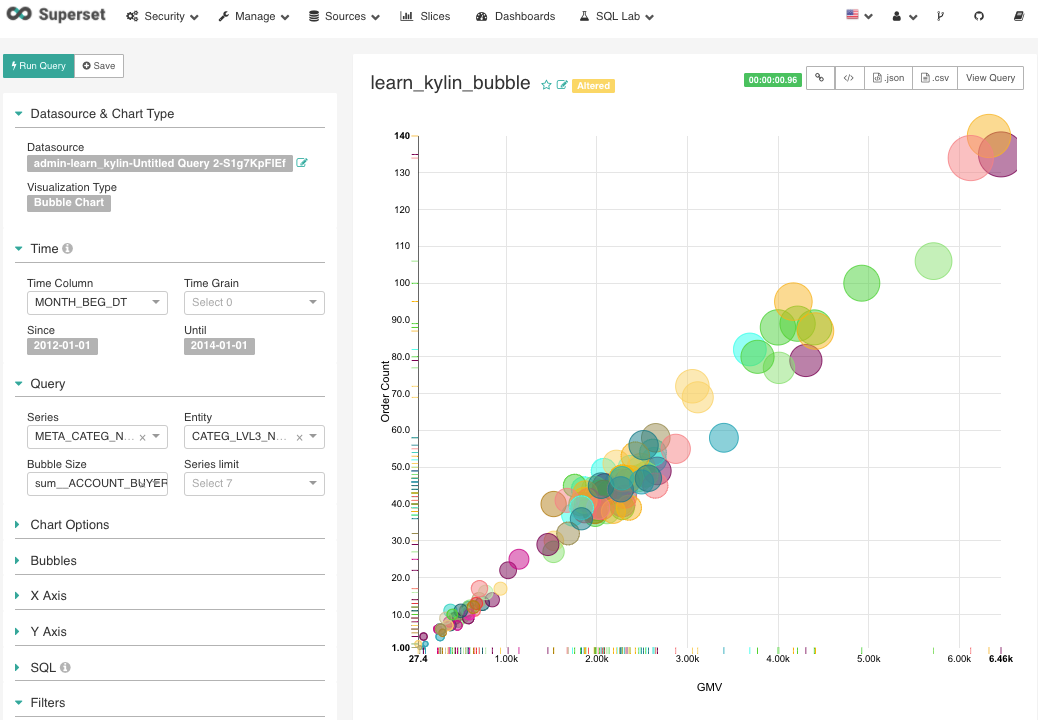
Figure 24 bubble chart
Other functionalities
Apache Superset also supports exporting to CSV, sharing, and viewing SQL query.
Summary
With the right technical synergy of open source projects, you can achieve amazing results, more than the sum of its parts. The pre-calculation technology of Apache Kylin accelerates visualization performance. The rich functionality of Apache Superset enables all Kylin Cube features to be fully utilized. When you marry the two, you get the superpower of accelerated interactive analytics.