A new measure for Percentile precalculation
Introduction
Since Apache Kylin 2.0, there’s a new measure for percentile precalculation, which aims at (sub-)second latency for approximate percentile analytics SQL queries. The implementation is based on t-digest library under Apachee 2.0 license, which provides a high-effecient data structure to save aggregation counters and algorithm to calculate approximate result of percentile.
Percentile
From wikipedia: A percentile (or a centile) is a measure used in statistics indicating the value below which a given percentage of observations in a group of observations fall. For example, the 20th percentile is the value (or score) below which 20% of the observations may be found.
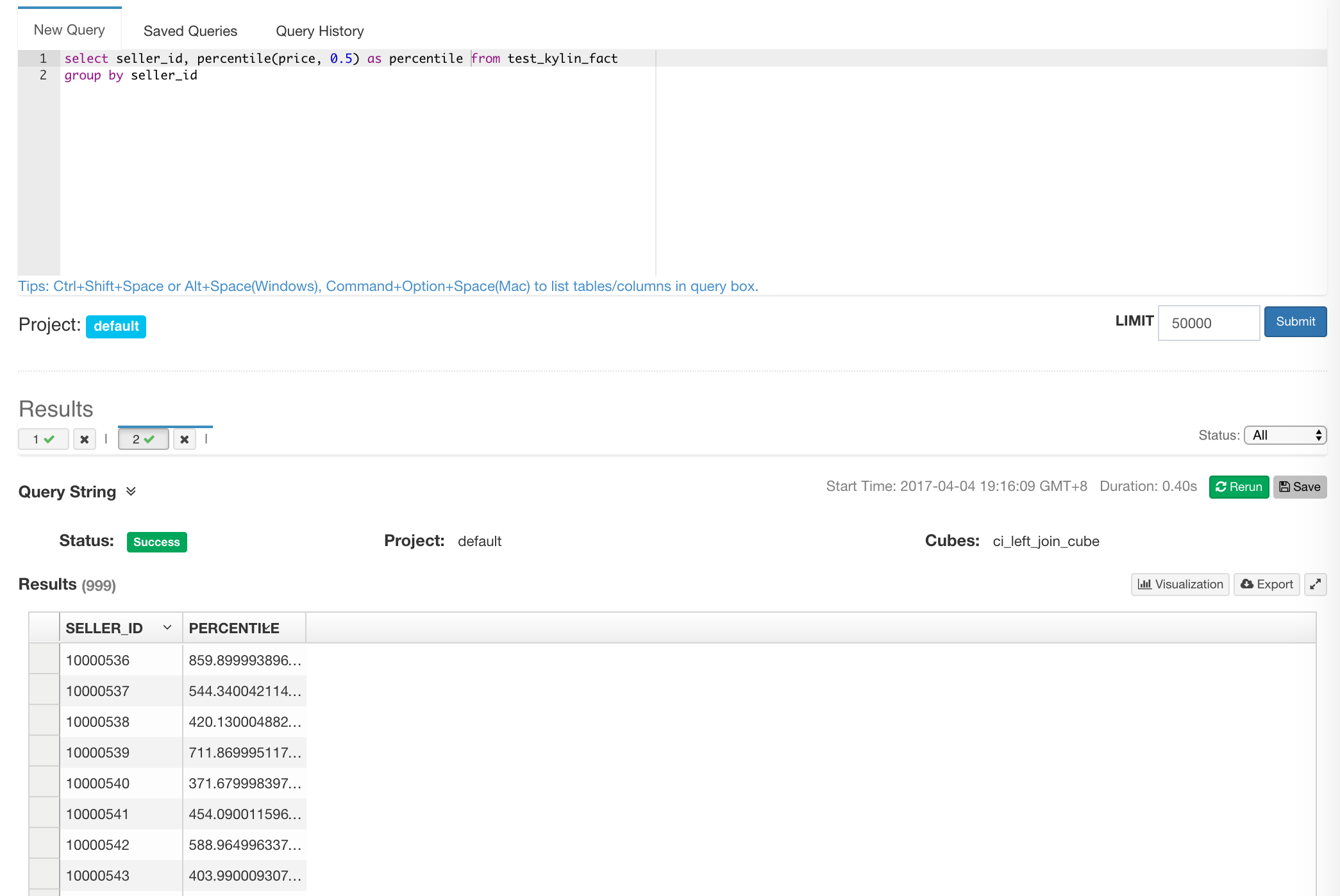
In Apache Kylin, we support the similar SQL sytanx like Apache Hive, with a aggregation function called percentile(<Number Column>, <Double>):
SELECT seller_id, percentile(price, 0.5)
FROM test_kylin_fact
GROUP BY seller_id
How to use
If you know little about Cubes, please go to QuickStart first to learn basic knowledge.
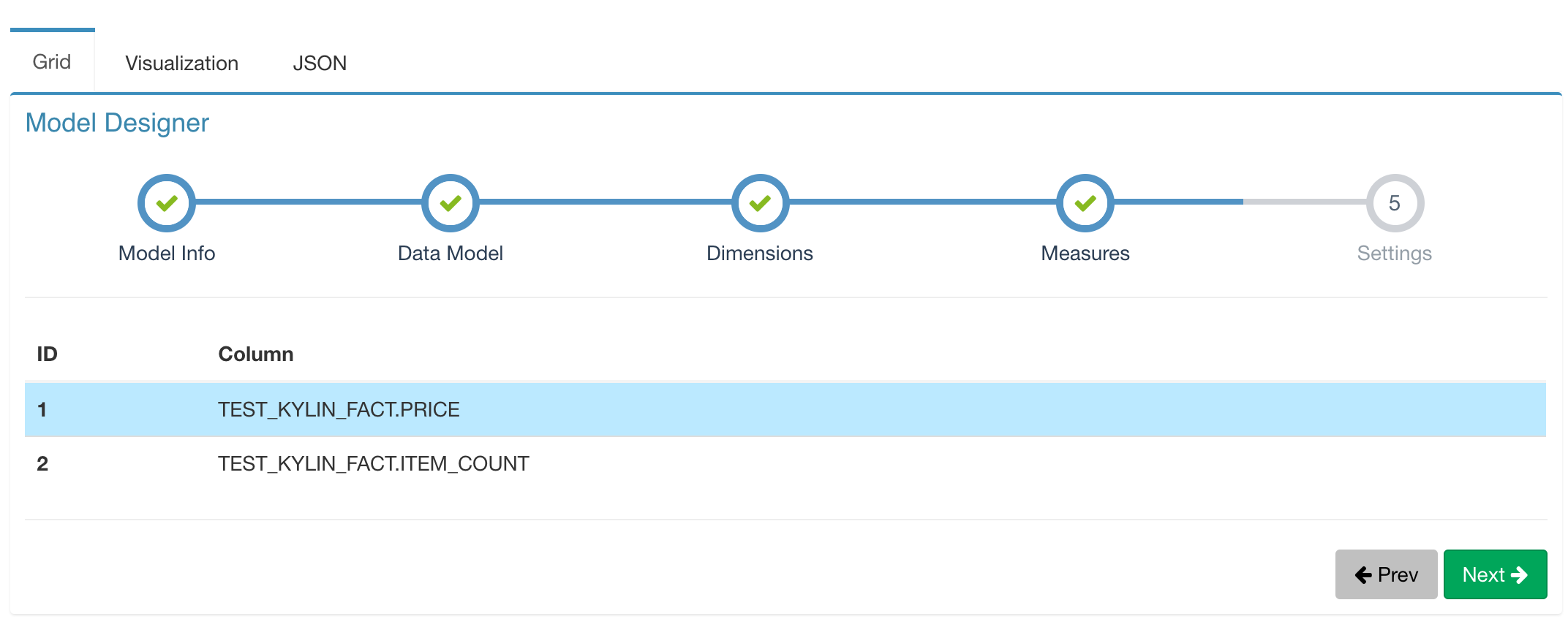
Firstly, you need to add this column as measure in data model.
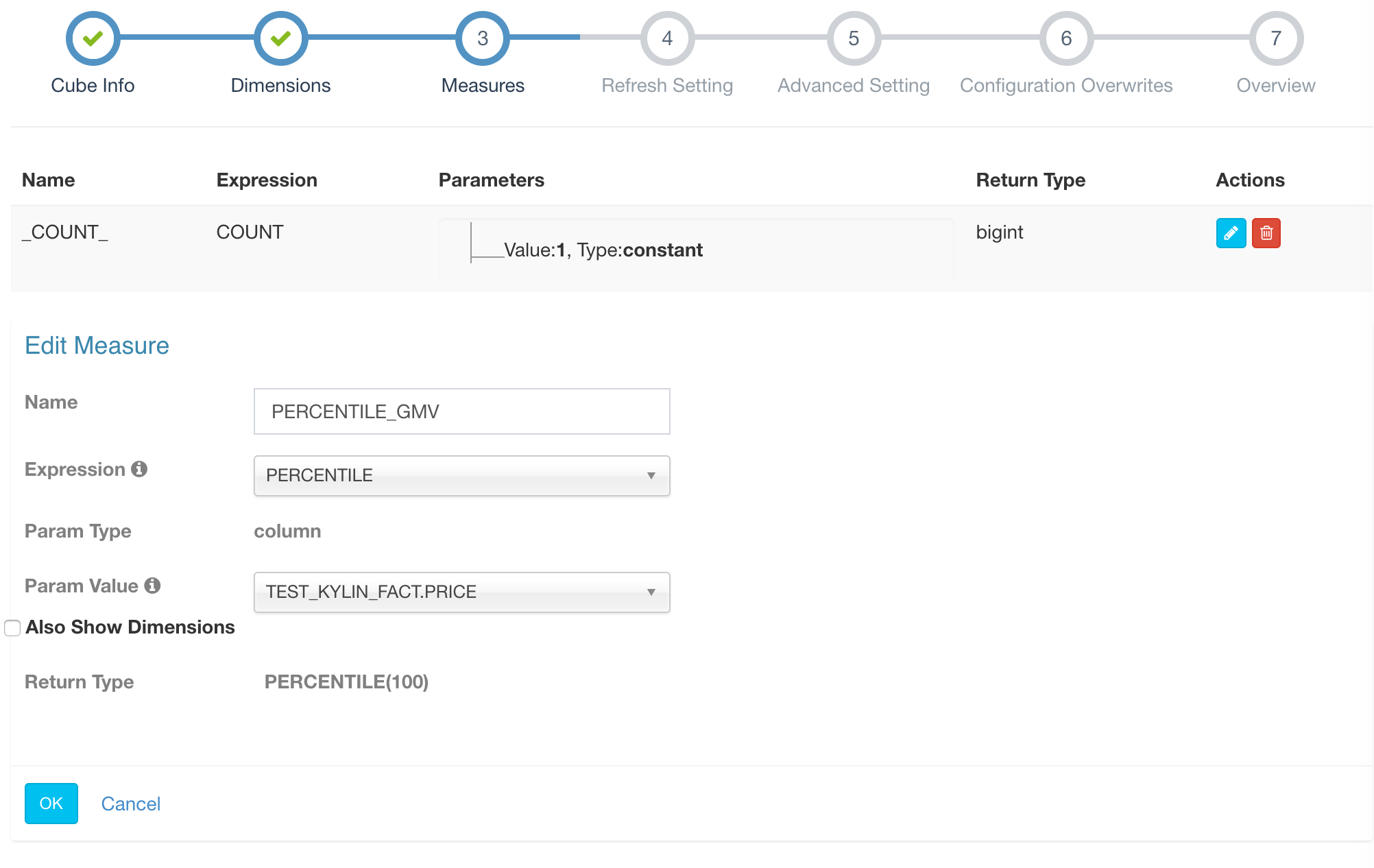
Secondly, create a cube and add a PERCENTILE measure.
Finally, build the cube and try some query.