
Hybrid Model in Apache Kylin 1.0
Apache Kylin v1.0 introduces a new realization “hybrid model” (also called “dynamic model”); This post introduces the concept and how to create a hybrid instance.
Problem
For incoming SQL queries, Kylin picks one (and only one) realization to serve the query; Before the “hybrid”, there is only one type of realization open for user: Cube. That to say, only 1 Cube would be selected to answer a query;
Now let’s start with a sample case; Assume user has a Cube called “Cube_V1”, it has been built for a couple of months; Now the user wants to add new dimension or metrics to fulfill their business need; So he created a new Cube named “Cube_V2”;
Due to some reason user wants to keep “Cube_V1”, and expects to build “Cube_V2” from the end date of “Cube_V1”; Possible reasons include:
- History source data has been dropped from Hadoop, not possible to build “Cube_V2” from the very beginning;
- The cube is large, rebuilding takes very long time;
- New dimension/metrics is only available or applied since some day;
- User feels okay that the result is empty for old days when the query uses new dimensions/metrics.
For the queries against the common dimensions/metrics, user expects both “Cube_V1” and “Cube_V2” be scanned to get a full result set; Under such a background, the “hybrid model” is introduced to solve this problem.
Hybrid Model
Hybrid model is a new realization which is a composite of one or multiple other realizations (cubes); See the figure below.
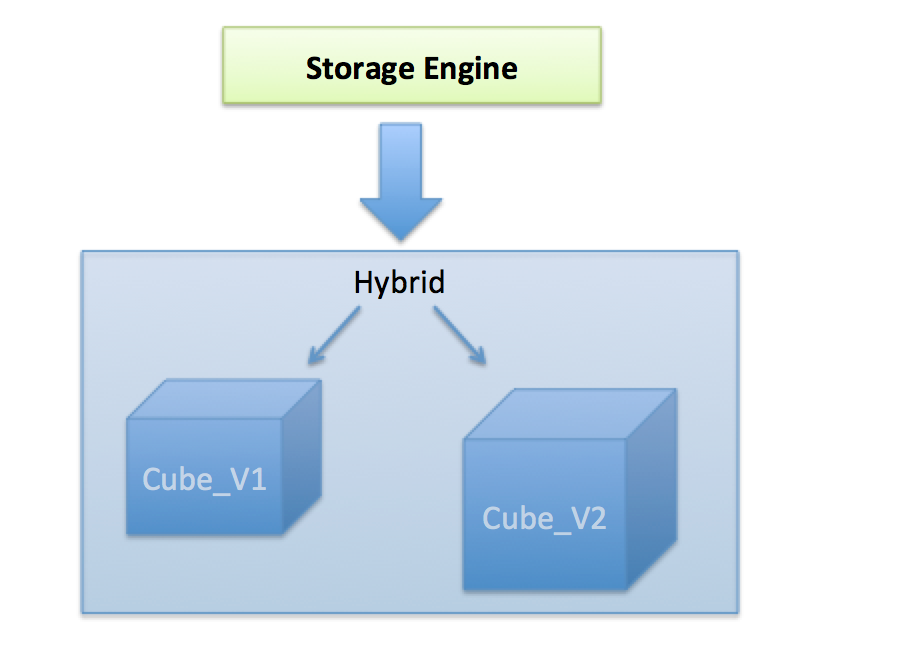
Hybrid doesn’t have its real storage; It is like a virtual database view over the tables; A hybrid instance acts as a delegator who forward the requests to its children realizations and then union the results when gets back from them.
How to add a hybrid instance
So far there is no UI for creating/editing hybrid; if have the need, you need manually edit Kylin metadata;
Step 1: Take a backup of kylin metadata store
export KYLIN_HOME="/path/to/kylin"
$KYLIN_HOME/bin/metastore.sh backup
A backup folder will be created, assume it is $KYLIN_HOME/metadata_backup/2015-09-25/
Step 2: Create sub-folder “hybrid”
mkdir -p $KYLIN_HOME/metadata_backup/2015-09-25/hybrid
Step 3: Create a hybrid instance json file:
vi $KYLIN_HOME/metadata_backup/2015-09-25/hybrid/my_hybrid.json
Input content like below, the “name” and “uuid” need be unique:
{
"uuid": "9iiu8590-64b6-4367-8fb5-7500eb95fd9c",
"name": "my_hybrid",
"realizations": [
{
"type": "CUBE",
"realization": "Cube_V1"
},
{
"type": "CUBE",
"realization": "Cube_V2"
}
]
}
Here “Cube_V1” and “Cube_V2” are the cubes that you want to combine.
Step 4: Add hybrid instance to project
Open project json file (for example project “default”) with text editor:
vi $KYLIN_HOME/metadata_backup/2015-09-25/project/default.json
In the “realizations” array, add one entry like below, the type need be “HYBRID”, “realization” is the name of the hybrid instance:
{
"name": "my_hybrid",
"type": "HYBRID",
"realization": "my_hybrid"
}
Step 5: Upload the metadata:
$KYLIN_HOME/bin/metastore.sh restore $KYLIN_HOME/metadata_backup/2015-09-25/
Please note, the “restore” action will upload the metadata from local to remote hbase store, which may overwrite the changes in remote; So please do this when there is no metadata change from Kylin server during this period (no building job, no cube creation/update, etc), or only pickup the changed files to an empty local folder before run “restore”;
Step 6: Reload metadata
Restart Kylin server, or click “Reload metadata” in the “Admin” tab on Kylin web UI to load the changes; Ideally the hybrid will start to work; You can do some verifications by writing some SQLs.
FAQ:
Question 1: When will hybrid be selected to answer a SQL query?
If one of its underlying cube can answer the query, the hybrid will be selected;
Question 2: How hybrid to answer the query?
Hybrid will delegate the query to each of its children realizations; If a child cube is capable for this query (match all dimensions/metrics), it will return the results to the hybrid, otherwise it will be skipped; Finally query engine will aggregate the data from hybrid before return to user;
Question 3: Will hybrid check the date/time duplication?
No; it depends on user to ensure the cubes in a hybrid don’t have date/time range duplication; For example, the “Cube_V1” is ended at 2015-9-20 (excluding), the “Cube_V2” should start from 2015-9-20 (including);
Question 4: Will hybrid restrict the children cubes having the same data model?
No; To provide as much as flexibility, hybrid doesn’t check whether the children cubes’ fact/lookup tables and join conditions are the same; But user should understand what they’re doing to avoid unexpected behavior.
Question 5: Can hybrid have another hybrid as child?
No; we don’t see the need; so far it assumes all children are Cubes;
Question 6: Can I use hybrid to join multiple cubes?
No; the purpose of hybrid is to consolidate history cube and new cube, something like a “union”, not “join”;
Question 7: If a child cube is disabled, will it be scanned via the hybrid?
No; hybrid instance will check the child realization’s status before sending query to it; so if the cube is disabled, it will not be scanned.