Prerequisite
To ensure system performance and stability, we recommend you run Kylin on a dedicated Hadoop cluster.
Prior to installing Kylin, please check the following prerequisites are met.
- Environment
- Recommended Resource and Configuration
Supported Hadoop Distributions
The following Hadoop distributions are verified to run on Kylin.
Kylin requires some components, please make sure each server has the following components.
- Hive
- HDFS
- Yarn
- ZooKeeper
Note: Spark is shipped in the binary package, so you don't need to install it in advance. If for security and compliance reasons, you want to replace the shipped Spark and Hadoop dependency with existing ones in your environment, please contact Kylin Community.
Java Environment
Kylin requires:
- Requires your environment's default JDK version is 8 (JDK 1.8_162 or above small version)
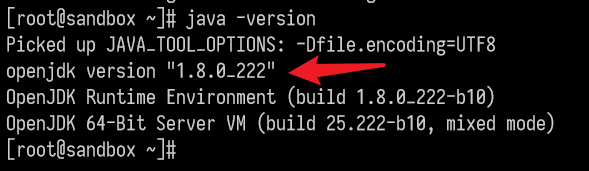
java -version
You can use the following command to check the JDK version of your existing environment, for example, the following figure shows JDK 8
Account Authority
The Linux account running Kylin must have the required access permissions to the cluster. These permissions include:
- Read/Write permission of HDFS
- Create/Read/Write permission of Hive table
Verify the user has access to the Hadoop cluster with account KyAdmin. Test using the steps below:
Verify the user has HDFS read and write permissions
Assuming the HDFS storage path for model data is
/kylin, set it inconf/kylin.propertiesas:kylin.env.hdfs-working-dir=/kylinThe storage folder must be created and granted with permissions. You may have to switch to HDFS administrator (usually the
hdfsuser), to do this:su hdfs
hdfs dfs -mkdir /kylin
hdfs dfs -chown KyAdmin /kylin
hdfs dfs -mkdir /user/KyAdmin
hdfs dfs -chown KyAdmin /user/KyAdminVerify the
KyAdminuser has read and write permissionshdfs dfs -put <any_file> /kylin
hdfs dfs -put <any_file> /user/KyAdminVerify the
KyAdminuser has Hive read and write permissionsLet's say you want to store a Hive table
t1in Hive databasekylinDB, Thet1table contains two fieldsid, name.Then verify the Hive permissions:
#hive
hive> show databases;
hive> use kylinDB;
hive> show tables;
hive> insert into t1 values(1, "kylin");
hive> select * from t1;
Metastore Configuration
A configured metastore is required for this product.
We recommend using PostgreSQL 10.7 as the metastore, which is provided in our package. Please refer to Use PostgreSQL as Metastore (Default) for installation steps and details.
If you want to use your own PostgreSQL database, the supported versions are below:
- PostgreSQL 9.1 or above
You can also choose to use MySQL but we currently don't provide a MySQL installation package or JDBC driver. Therefore, you need to finish all the prerequisites before setting up. Please refer to Use MySQL as Metastore for installation steps and details. The supported MySQL database versions are below:
- MySQL 5.1-5.7
- MySQL 5.7 (recommended)
Check Zookeeper
The following steps can be used to quickly verify the connectivity between ZooKeeper and Kylin after Kerberos is enabled.
Find the ZooKeeper working directory on the node where the ZooKeeper Client is deployed
Add or modify the Client section to the
conf/jaas.conffile:Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/path/to/keytab_assigned_to_kylin"
storeKey=true
useTicketCache=false
principal="principal_assigned_to_kylin";
};export JVMFLAGS="-Djava.security.auth.login.config=/path/to/jaas.conf"bin/zkCli.sh -server ${kylin.env.zookeeper-connect-string}Verify that the ZooKeeper node can be viewed normally, for example:
ls /Clean up the new Client section in step 2 and the environment variables
unset JVMFLAGSdeclared in step 3
If you download ZooKeeper from the non-official website, you can consult the operation and maintenance personnel before performing the above operations.
Hadoop Cluster Resource Allocation
To ensure Kylin works efficiently, please ensure the Hadoop cluster configurations satisfy the following conditions:
yarn.nodemanager.resource.memory-mbconfiguration item bigger than 8192 MByarn.scheduler.maximum-allocation-mbconfiguration item bigger than 4096 MByarn.scheduler.maximum-allocation-vcoresconfiguration item bigger than 5
If you need to run Kylin in a sandbox or other virtual machine environment, please make sure the virtual machine environment has the following resources:
No less than 4 processors
Memory is no less than 10 GB
The value of the configuration item
yarn.nodemanager.resource.cpu-vcoresis no less than 8
Recommended Hardware Configuration
We recommend the following hardware configuration to install Kylin:
- 16 vCore, 64 GB memory
- At least 500GB disk
- For network port requirements, please refer to the Network Port Requirements chapter.
Recommended Linux Distribution
We recommend using the following version of the Linux operating system:
- Ubuntu 18.04 and above (recommend LTS version)
- Red Hat Enterprise Linux 6.4+ and above
- CentOS 6.4+ and above
Recommended Client Configuration
- Operating System: macOS / Windows 7 and above
- RAM: 8G or above
- Browser version:
- Chrome 45 or above
- Internet Explorer 11 or above