
Cube migration is used to migrate cube from QA env to PROD env, Kylin v3.1.0 enhances this feature, the list of enhanced functions is showed as below:
- Use some internal rules to check the quality and compatibility of cube by Kylin before migration, instead of checking manually;
- Use email to send cube migration request and result notification;
- Support to migrate across two Hadoop cluster;
I. Migrate on the same Hadoop cluster
There are two ways to migrate cube from QA env to PROD env on the same Hadoop cluster:
- Use the Kylin portal;
- Use ‘CubeMigrationCLI.java’ CLI;
1. Pre-requisitions to use cube migration
- Only cube admin can migrate the cubes as the “migrate” button is ONLY visible to cube admin.
- The cube status must be READY before migration which you have built the segment and confirmed the performance.
- The Property ‘kylin.cube.migration.enabled’ must be true.
- The target project must exist on Kylin PROD env before migration.
- The QA env and PROD env must share the same Hadoop cluster, including HDFS, HBase and HIVE.
2. Steps to migrate a cube through the Kylin portal
First of all, make sure that you have authority of the cube you want to migrate.
Step 1
In ‘Model’ page, click the ‘Action’ drop down button in the ‘Actions’ column and select operation ‘Migrate’:
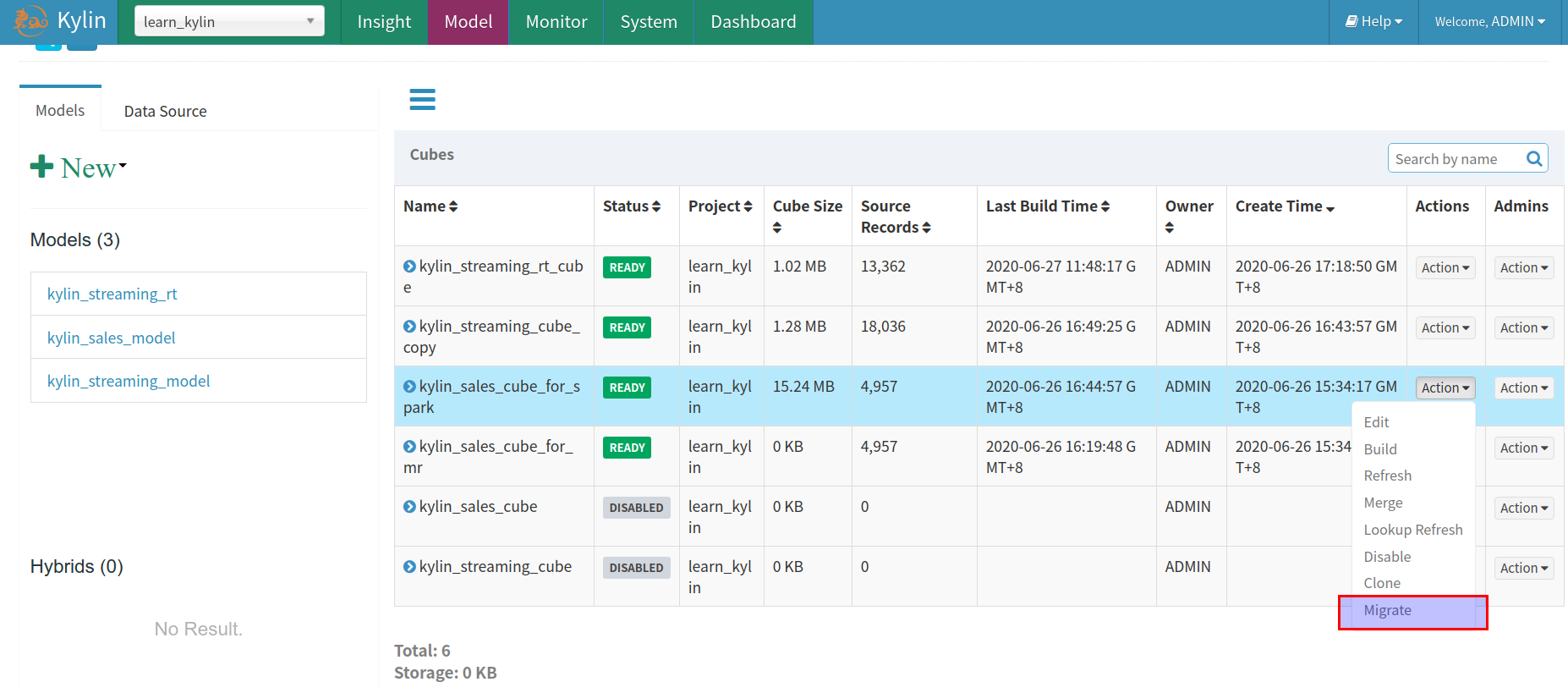
Step 2
After you click ‘Migrate’ button, you will see a pop-up window:
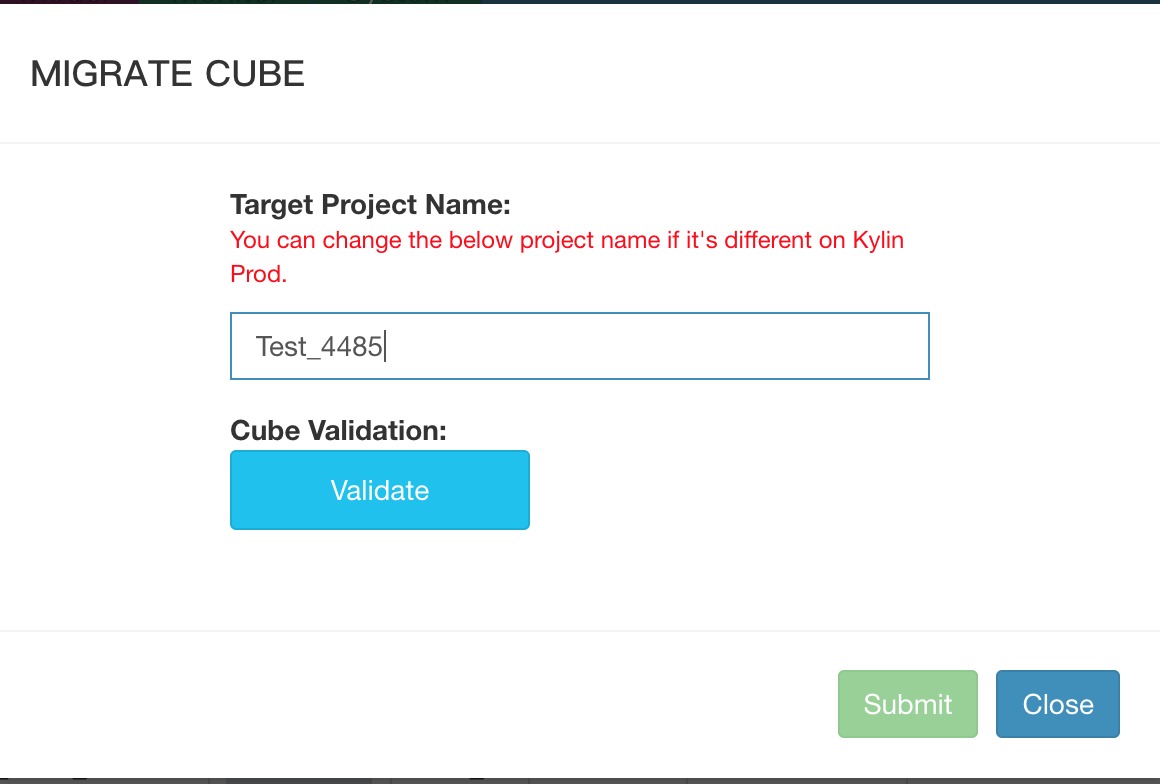
Step 3
Check if the target project name is what you want. It uses the same project name on QA env as default target project name. If the target project name is different on PROD env, please replace with the correct one.
Step 4
Click ‘Validate’ button to verify the cube validity. It may take couple of minutes to validate the cube on the backend and show the validity results on a pop-up window.
Common exceptions and suggested solutions
-
The target project XXX does not exist on PROD-KYLIN-INSTANCE:7070: please enter the correct project name or create the expected project on the PROD env. -
Cube email notification list is not set or empty: please add notification email in the Notification List of cube;
Some suggestive messages
Auto merge time range for cube XXXX is not set: if ‘Auto Merge Threshold’ is not set, this message will be shown. You can ignore it or set ‘Auto Merge Threshold’ in ‘Refresh Setting’ section of cube.ExpansionRateRule: failed on expansion rate check with exceeding 5: it means the expansion rate of the cube you want to migrate exceed 5, which is the value of property ‘kylin.cube.migration.expansion-rate’, you can set the proper value for the cube.Failed on query latency check with average cost 5617 exceeding 2000ms: if property ‘kylin.cube.migration.rule-query-latency-enabled’ is set to true, it will generate some test sql to test the average query latency for the cube you want to migrate. You can set the proper value for property ‘kylin.cube.migration.query-latency-seconds’.
Step 5
If validations are ok, click ‘Submit’ button to send the migration request email to cubes administrator, if send email successfully, it will show the message like this:
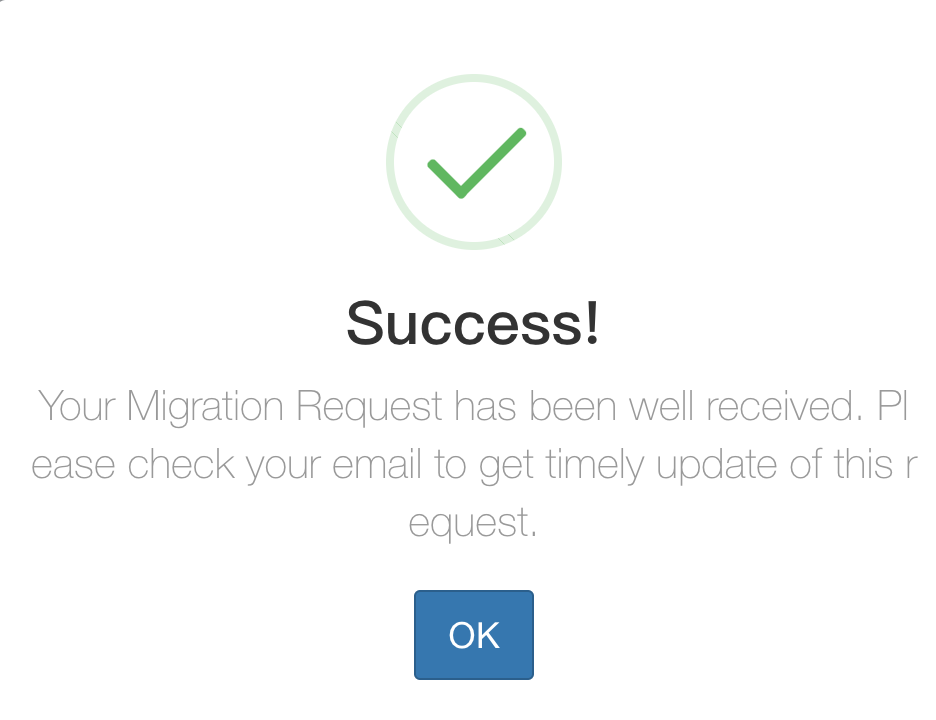
Step 6
Cubes administrator will receive a migration request email, and can click the ‘Action’ drop down button in the ‘Admins’ column and select operation ‘Approve Migration’ button to migrate cube or select ‘Reject Migration’ button to reject request. It also will send a notification email to the migration requester:

Step 7
If cubes administrator selects ‘Approve Migration’ button to migrate cube, it will show a pop-up window:
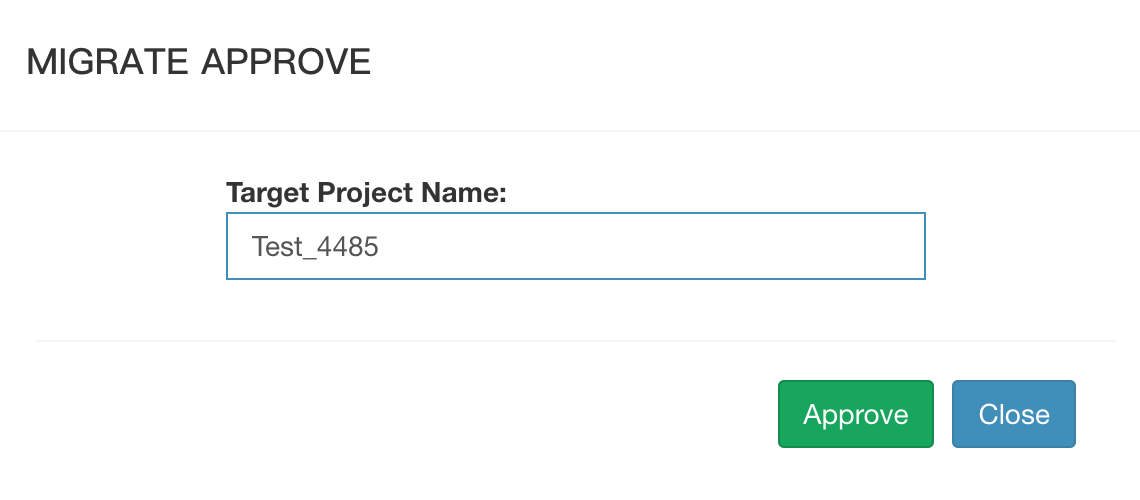
After enter the target project name, and click ‘Approve’ button, it will start to migrate cube.
Step 8
If migrate successfully, it will show the message below:
Step 9
Finally, go to Kylin portal on PROD env, and refresh the ‘Model’ page, you will see the cube you migrated from QA env and the status of this cube is DISABLED.
3. Use ‘CubeMigrationCLI.java’ CLI to migrate cube
Function
CubeMigrationCLI.java can migrate a cube from a Kylin environment to another, for example, promote a well tested cube from the testing env to production env. Note that the different Kylin environments should share the same Hadoop cluster, including HDFS, HBase and HIVE.
Please note, this tool will migrate the Kylin metadata, rename the Kylin HDFS folders and update HBase table’s metadata. It doesn’t migrate data across Hadoop clusters.
How to use
./bin/kylin.sh org.apache.kylin.tool.CubeMigrationCLI <srcKylinConfigUri> <dstKylinConfigUri> <cubeName> <projectName> <copyAclOrNot> <purgeOrNot> <overwriteIfExists> <realExecute> <migrateSegmentOrNot>For example:
./bin/kylin.sh org.apache.kylin.tool.CubeMigrationCLI ADMIN:KYLIN@kylin-qa:7070 ADMIN:KYLIN@kylin-prod:7070 kylin_sales_cube learn_kylin true false false true falseAfter the command is successfully executed, please reload Kylin metadata, the cube you want to migrate will appear in the target environment.
All supported parameters are listed below:
- If the data model of the cube you want to migrate does not exist in the target environment, this tool will also migrate the model.
- If you set
overwriteIfExiststofalse, and the cube exists in the target environment, the tool will stop to proceed. - If you set
migrateSegmentOrNottotrue, please make sure the cube hasREADYsegments, they will be migrated to target environment together.
| Parameter | Description |
|---|---|
| srcKylinConfigUri | The URL of the source environment’s Kylin configuration. It can be username:password@host:port, or an absolute file path to the kylin.properties. If you use the URL method, you need to change the ADMIN user name and password to username:password@hostname:port format is placed in the URL, because there is a API needs to be called with admin permission during the migration process. |
| dstKylinConfigUri | The URL of the target environment’s Kylin configuration. |
| cubeName | the name of cube to be migrated. |
| projectName | The target project in the target environment. If it doesn’t exist, create it before run this command. |
| copyAclOrNot | true or false: whether copy the cube ACL to target environment. |
| purgeOrNot | true or false: whether to purge the cube from source environment after it be migrated to target environment. |
| overwriteIfExists | true or false: whether to overwrite if it already exists in the target environment. |
| realExecute | true or false: If false, just print the operations to take (dry-run mode); if true, do the real migration. |
| migrateSegmentOrNot | (Optional) true or false: whether copy segment info to the target environment. Default true. |
II. Migrate across two Hadoop clusters
Note:
- Currently it only supports to use ‘CubeMigrationCrossClusterCLI.java’ CLI to migrate cube across two Hadoop clusters.
- Support to migrate cube data (segments data on HBase) from QA env to PROD env.
1. Pre-requisitions to use cube migration
- The cube status must be READY before migration which you have built the segment and confirmed the performance.
- The target project name of PROD env must be the same as the one on QA env.
2. How to use ‘CubeMigrationCrossClusterCLI.java’ CLI to migrate cube
./bin/kylin.sh org.apache.kylin.tool.migration.CubeMigrationCrossClusterCLI <kylinUriSrc> <kylinUriDst> <updateMappingPath> <cube> <hybrid> <project> <all> <dstHiveCheck> <overwrite> <schemaOnly> <execute> <coprocessorPath> <codeOfFSHAEnabled> <distCpJobQueue> <distCpJobMemory> <nThread>For example:
./bin/kylin.sh org.apache.kylin.tool.migration.CubeMigrationCrossClusterCLI -kylinUriSrc ADMIN:KYLIN@QA.env:17070 -kylinUriDst ADMIN:KYLIN@PROD.env:17777 -cube kylin_sales_cube -updateMappingPath $KYLIN_HOME/updateTableMapping.json -execute true -schemaOnly false -overwrite trueAfter the command is successfully executed, please go to Kylin PROD portal and find the cube you migrated from ‘Model’ page, the status of the cube is READY.
All supported parameters are listed below:
| Parameter | Description |
|---|---|
| kylinUriSrc | (Required) The source kylin uri with format user:pwd@host:port. |
| kylinUriDst | (Required) The target kylin uri with format user:pwd@host:port. |
| updateMappingPath | (Optional) The path for the update Hive table mapping file, the format is json. |
| cube | The cubes which you want to migrate, separated by ‘,’. |
| hybrid | The hybrids which you want to migrate, separated by ‘,’. |
| project | The projects which you want to migrate, separated by ‘,’. |
| all | Migrate all projects. Note: You must add only one of above four parameters: ‘cube’, ‘hybrid’, ‘project’ or ‘all’. |
| dstHiveCheck | (Optional) Whether to check target hive tables, the default value is true. |
| overwrite | (Optional) Whether to overwrite existing cubes, the default value is false. |
| schemaOnly | (Optional) Whether only migrate cube related schema, the default value is true. Note: If set to false, it will migrate cube data too. |
| execute | (Optional) Whether it’s to execute the migration, the default value is false. |
| coprocessorPath | (Optional) The path of coprocessor to be deployed, the default value is get from KylinConfigBase.getCoprocessorLocalJar(). |
| codeOfFSHAEnabled | (Optional) Whether to enable the namenode ha of clusters. |
| distCpJobQueue | (Optional) The mapreduce.job.queuename for DistCp job. |
| distCpJobMemory | (Optional) The mapreduce.map.memory.mb for DistCp job. |
| nThread | (Optional) The number of threads for migrating cube data in parallel. |