
Why did Meituan develop Kylin On Druid (part 1 of 2)?
Preface
In the Big Data field, Apache Kylin and Apache Druid(incubating) are two commonly adopted OLAP engines, both of which enable fast querying on huge datasets. In the enterprises that heavily rely on big data analytics, they often run both for different use cases.
During the Apache Kylin Meetup in August 2018, the Meituan team shared their Kylin on Druid (KoD) solution. Why did they develop this hybrid system? What’s the rationale behind it? This article will answer these questions and help you to understand the differences and the pros and cons of each OLAP engine.
01 Introduction to Apache Kylin
Apache Kylin is an open source distributed big data analytics engine. It constructs data models on top of huge datasets, builds pre-calculated Cubes to support multi-dimensional analysis, and provides a SQL query interface and multi-dimensional analysis on top of Hadoop, with general ODBC, JDBC, and RESTful API interfaces. Apache Kylin’s unique pre-calculation ability enables it to handle extremely large datasets with sub-second query response times.
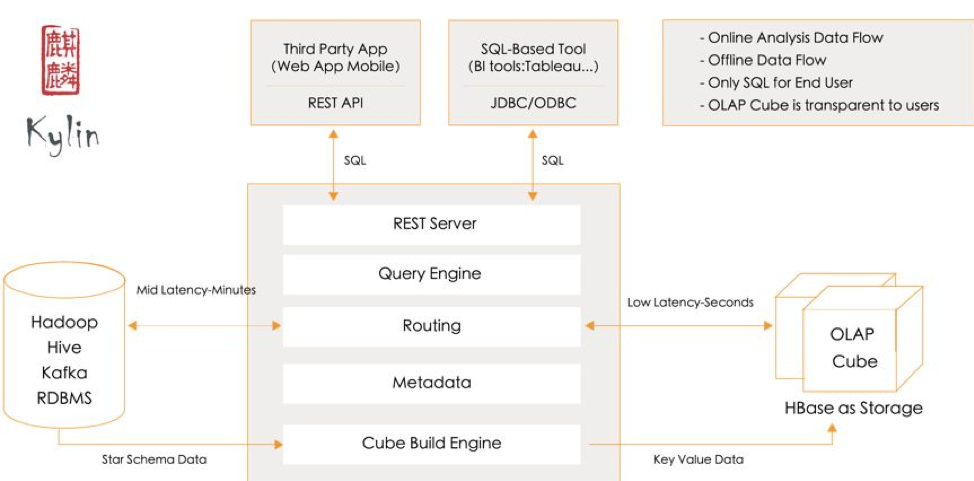
Graphic 1 Kylin Architecture
02 Apache Kylin’s Advantage
- The mature, Hadoop-based computing engines (MapReduce and Spark) that provide strong capability of pre-calculation on super large datasets, which can be deployed out-of-the-box on any mainstream Hadoop platform.
- Support of ANSI SQL that allows users to do data analysis with SQL directly.
- Sub-second, low-latency query response times.
- Common OLAP Star/Snowflake Schema data modeling.
- A rich OLAP function set including Sum, Count Distinct, Top N, Percentile, etc.
- Intelligent trimming of Cuboids that reduces consumption of storage and computing power.
- Direct integration with mainstream BI tools and rich interfaces.
- Support of both batch loading of super large historical datasets and micro-batches of data streams.
03 Introduction to Apache Druid (incubating)
Druid was created in 2012. It’s an open source distributed data store. Its core design combines the concept of analytical databases, time-series databases, and search systems, and it can support data collection and analytics on fairly large datasets. Druid uses an Apache V2 license and is an Apache incubator project.
Druid Architecture
From the perspective of deployment architectures, Druid’s processes mostly fall into 3 categories based on their roles.
• Data Node (Slave node for data ingestion and calculation)
The Historical node is in charge of loading segments (committed immutable data) and receiving queries on historical data.
Middle Manager is in charge of data ingestion and commit segments. Each task is done by a separate JVM.
Peon is in charge of completing a single task, which is managed and monitored by the Middle Manager.
• Query Node
Broker receives query requests, determines on which segment the data resides, and distributes sub-queries and merges query results.
• Master Node (Task Coordinator and Cluster Manager)
Coordinator monitors Historical nodes, dispatches segments and monitor workload.
Overlord monitors Middle Manager, dispatches tasks to Middle Manager, and assists releasing of segments.
External Dependency
At the same time, Druid has 3 replaceable external dependencies.
• Deep Storage (distributed storage)
Druid uses Deep storage to transfer data files between nodes.
• Metadata Storage
Metadata Storage stores the metadata about segment positions and task output.
• Zookeeper (cluster management and task coordination)
Druid uses Zookeeper (ZK) to ensure consistency of the cluster status.
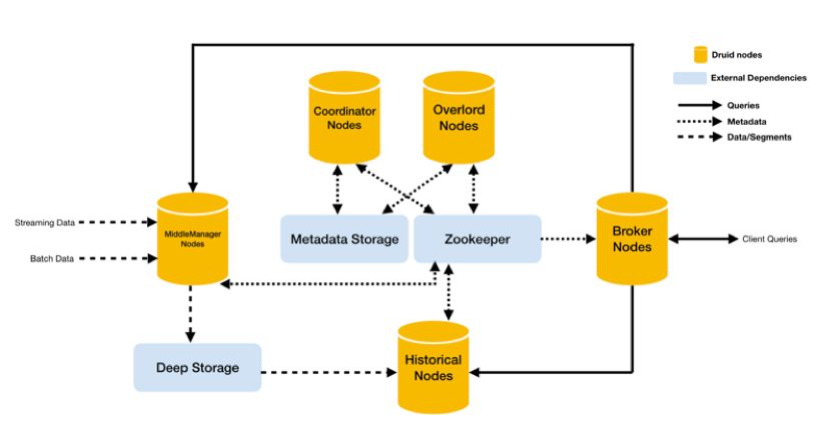
Graphic 2 Druid Architecture
Data Source and Segment
Druid stores data in Data Source. Data Source is equivalent to Table in RDBMS. Data Source is divided into multiple Chunks based on timestamps, and data within the same time range will be organized into the same Chunk. Each Chunk consists of multiple Segments, and each Segment is a physical data file and an atomic storage unit. Due to performance consideration, size of a Segment file is recommended to be 500MB.
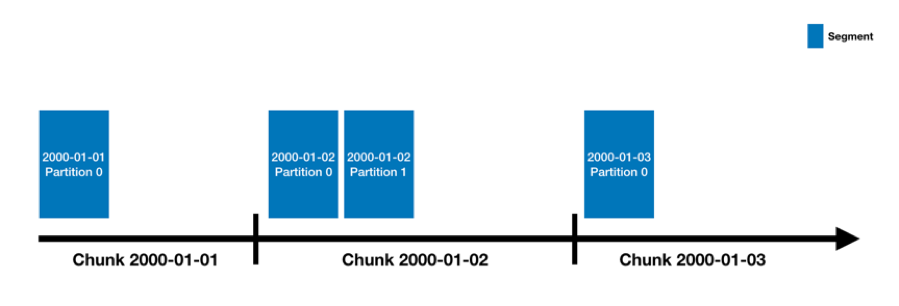
Graphic 3 Data Source & Segment
As Druid has features of both OLAP and Time-series database, its schema includes 3 types of columns: Timestamp, Dimension and Measures (Metrics). Timestamp column can be used for trimming Segments, and Dimension/Measures are similar to Kylin’s.

Graphic 4 Druid Schema
Druid’s Advantage
- Real-time data ingestion: data can be instantly queried within sub-seconds after ingested, which is Druid’s most unique feature.
- Support of detail and aggregate queries.
- Columnar storage that avoids unnecessary IO.
- Support of inverted-order index with good filtering performance.
- Separation of cold/hot data.
04 Why did Meituan develop Kylin on Druid?
Meituan deployed into production an offline OLAP platform with Apache Kylin as its core component in 2015. Since then the platform has served almost all business lines with fast growing data volume and query executions, and the stress on the cluster has increased accordingly. Throughout the time, the tech team in Meituan keeps exploring better solutions for some of Kylin’s challenges. The major one is Apache HBase, the storage that Kylin relies on.
Kylin stores its data in HBase by converting the Dimensions and Measures into HBase Keys and Values, respectively. As HBase doesn’t support secondary index and only has one RowKey index, Kylin’s Dimension values will be combined into a fixed sequence to store as RowKey. In this way, filtering on a Dimension in the front of the sequence will perform better than those at the back. Here’s an example:
In the testing environment, there are two almost identical Cubes (Cube1 and Cube2). They both have the same data source and the same Dimensions/Measures. The only difference is the order of the Dimensions in the RowKey: Cube1 puts P_LINEORDER.LO_ORDERKEY at the first while Cube2 the last.
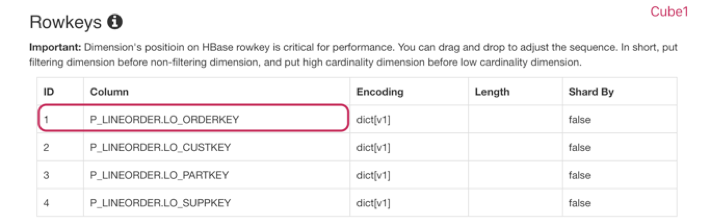
Graphic 5 Cube1 RowKey Sequence

Graphic 6 Cube2 RowKey Sequence
Now let’s query each Cube with the same SQL and compare the response time.
select S_SUPPKEY, C_CUSTKEY, sum(LO_EXTENDEDPRICE) as m1
from P_LINEORDER
left join SUPPLIER on P_LINEORDER.LO_SUPPKEY = SUPPLIER.S_SUPPKEY
left join CUSTOMER on P_LINEORDER.LO_CUSTKEY = CUSTOMER.C_CUSTKEY
WHERE (LO_ORDERKEY > 1799905 and LO_ORDERKEY < 1799915) or (LO_ORDERKEY > 1999905 and LO_ORDERKEY < 1999935)
GROUP BY S_SUPPKEY, C_CUSTKEY;
Below shows the time consumed and data scanned:
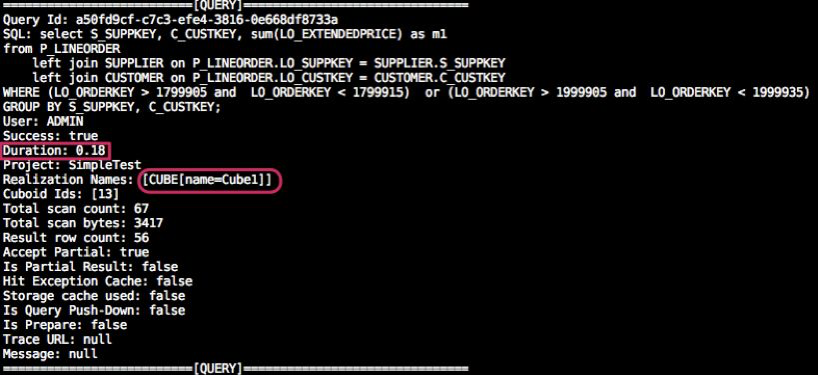
Graphic 7 Cube1 Query Log
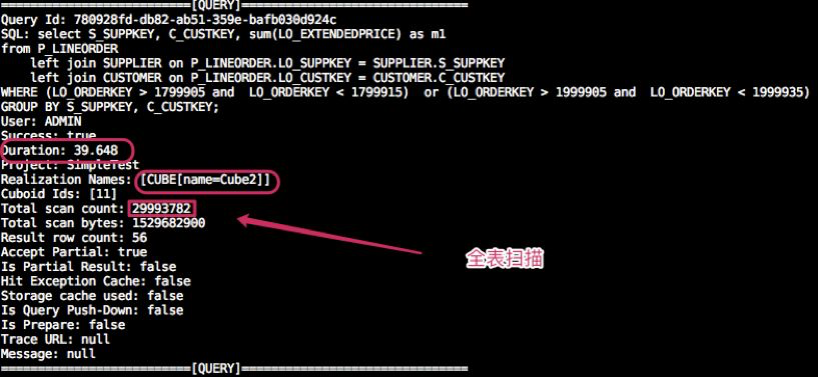
Graphic 8 Cube1 Query Log
The test result shows that the same SQL query can perform 200x time differently. The primary reason for the difference is that the query has to scan a larger range of data in the HTable of Cube2.
In addition, Kylin’s multiple Dimension values are stored in a Key’s corresponding Value, so when querying on a single Dimension, unnecessary Dimensions are read as well, generating unnecessary IO.
To summarize, the limitation of HBase impacts the user’s experience, especially among business groups.
Kylin’s query performance and user experience can be greatly improved with pure columnar storage and multiple indexes on Dimensions. As analyzed above, Druid happens to meet the requirements of columnar + multi-index. So the Meituan Kylin team decided to try replacing HBase with Druid.
Why not just use Druid then? Meituan’s engineers shared their thoughts:
1. Druid’s native query language is in its own specific JSON format, which is not as easy to pick up as SQL. Although the Druid community added SQL support later on, the support is not complete and does not meet the data analysts’ requirement of complex SQL queries. On the contrary, Kylin natively supports ANSI SQL, uses Apache Calcite for semantic parsing, and supports SQL features such as join, sub query, window functions, etc. In addition, it provides standard interfaces including ODBC/JDBC, and can directly connect with BI tools such as Tableau, Power BI, Superset, and Redash.
-
Druid can support only single-table query. Multi-table joins are very common in practice, but they cannot be supported by Druid. Kylin, however, supports Star Schema and Snowflake Schema, satisfying multi-table join requirements.
-
Druid cannot support exact distinct count, but Kylin can support approximation, based upon HyperLogLog, and exact deduplication, based upon Bitmap. For scenarios that require exact values, Kylin is almost the only option.
-
Druid rollup can only pre-calculate Base Cuboids. Kylin can specify richer combinations of Dimensions to match query patterns, reducing calculation at query time.
From the experiences of utilizing Druid and Kylin, we recognize the management and operational challenges in using Druid as the OLAP engine:
-
Druid doesn’t provide Web GUI for business users. Users have to use a less-friendly API to construct a new model in Druid. Kylin, on the other hand, provides an easy-to-use Web GUI. Business users can simply create a new model with a few mouse clicks, and then query it with SQL. After a brief training, business users can then use self-service.
-
Druid doesn’t provide an ops-friendly console for cluster monitoring and management, so workload increases. Kylin is based on a Hadoop platform, which has complete monitoring and management capabilities with tools like Ambari or Cloudera Manager.
-
Druid has to be set up on a dedicated cluster and cannot utilize an existing Hadoop cluster’s computing resources. Nowadays, an enterprise has typically deployed a Hadoop cluster and is using standard resource management tools (YARN/Mesos/Kubernets) to unify management of computing resources. Alternatively, Druid would need separate deployment and operations. Kylin’s data processing is based on MapReduce or Spark, which can share a resource on the Hadoop cluster and allow dynamic resource allocations. This maximizes resource efficiency without extra operational effort.
Therefore, it appears to be a promising OLAP solution to combine Druid’s excellent columnar storage with Kylin’s usability, compatibility, and completeness. Druid has columnar storage, inverted index, better filtering performance than HBase, native OLAP features, and good secondary aggregation capabilities. Meituan’s tech team decided to try replacing HBase with Druid as the storage for Kylin.
05
### Kylin on Druid Design
At v1.5, Apache Kylin introduced plugable architecture and de-coupled computing and storage components, which makes the replacement of HBase possible. Here is a brief introduction to the main design concept of Kylin on Druid based on Meituan engineer Kaisen Kang’s design doc. (Graphics 9 and 10 are from reference[1], and text are from reference[1] and [3])
Process of Building Cube
- Add steps of counting Druid Segments and updating Druid Rules before generating Cuiboid data files.
- Generate Cuboid files with MapReduce, using the same building process used previously.
- Replace the original step, “convert to HFile”, with the step called “convert to Druid Segment”, which converts Cuboid files to the Druid columnar format and outputs to a specific HDFS path (line 1 in Graphic 9) .
- Publish the metadata of the Druid Segment to the Druid metadata store (line 2 in Graphic 9).
- Druid Coordinator periodically checks new Segments in the metadata store (line 3), and if it finds a new Segment, it’ll notify the Historical node (line 4). Upon notification, Historical node will pull Segment data files from HDFS to local and load (line 5).
- Once all Druid Segments are loaded, Cube building is done.
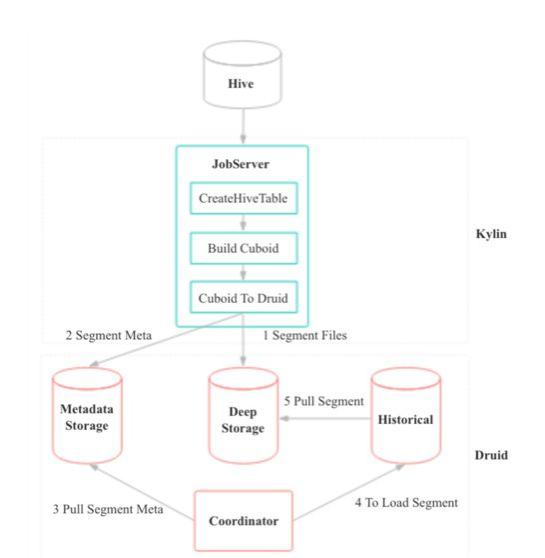
Graphic 9 Process of Building Cube
Process of Querying Cube
- When Kylin Query Server initiates a query, Calcite parses the query as Druid query plan (scan or groupby) and sends the request to Druid Broker.
- Druid Broker parses the request, finds the corresponding Historical nodes, dispatches the request to the nodes, and aggregates the returned results.
- Kylin Query Server obtains the return from Druid Broker via HTTP and converts it to Tuple and hands over to Calcite for traversing.

Graphic 10 Process of Querying Cube
Schema Mapping
- One Kylin Cube maps to one Druid Data Source.
- One Kylin Segment maps to one or more Druid Segments.
- The Kylin time partition column maps to the Druid timestamp column.
- One Kylin Cuboid maps to one Druid dimension column.
- Kylin dimension columns map to Druid dimension columns.
- Kylin measure columns map to Druid measure columns.
06 Summary
In this article, we first analyzed features and pros/cons of both Kylin and Druid, and the reasons for poor performance of Hbase in Kylin in some cases. Then we searched solutions and found the feasible option of using Druid as the Kylin storage engine. At last, we illustrated the Kylin-on-Druid architecture and the processes developed by Meituan.
Stay tuned for our next article about how to use Kylin on Druid, how it performs, and how it can be improved.
07 Reference
-
https://issues.apache.org/jira/projects/KYLIN/issues/KYLIN-3694
-
https://github.com/apache/kylin/tree/kylin-on-druid
-
https://blog.bcmeng.com/post/kylin-on-druid.html
-
http://druid.io/docs/latest/design