
Redash-Kylin plugin from Strikingly
At strikingly, we are using Apache Kylin as our OLAP engine. Kylin is very powerful and it supports our big data business well. We’ve chosen Apache Kylin because it fits our demand: it handles a huge amount of data, undertakes multiple concurrent queries and has sub-second response time.
Although we are mainly using Kylin to provide service to our customers, we’ve decided to reuse the built result for internal purposes too. Kylin supports Business Intelligence tools like Apache Zeppelin and Tableau. With these BI tools we can provide insight and visualization about our data which will help making business decisions.
Other than those BI tools mentioned above, we’re using another similar application named Redash because:
-
We’ve already had a deployment of redash for data analyzing upon traditional databases like PostgreSQL, etc
-
Redash is open source and easy to deploy, rich in visualization functions and has good integrations with other productivity tools we are using (like Slack).
Unfortunately, redash doesn’t officially support Kylin as a data source for now. Thus we wrote a simple one to include it. The plugin has already been open sourced under BSD-2 license as a GitHub repository.
The redash-kylin plugin is just a single piece of python file which implements redash’s data source protocol. To install, retrieve the kylin.py file inside redash/query_runner folder of the plugin’s repository and place it under corresponding folder of redash.
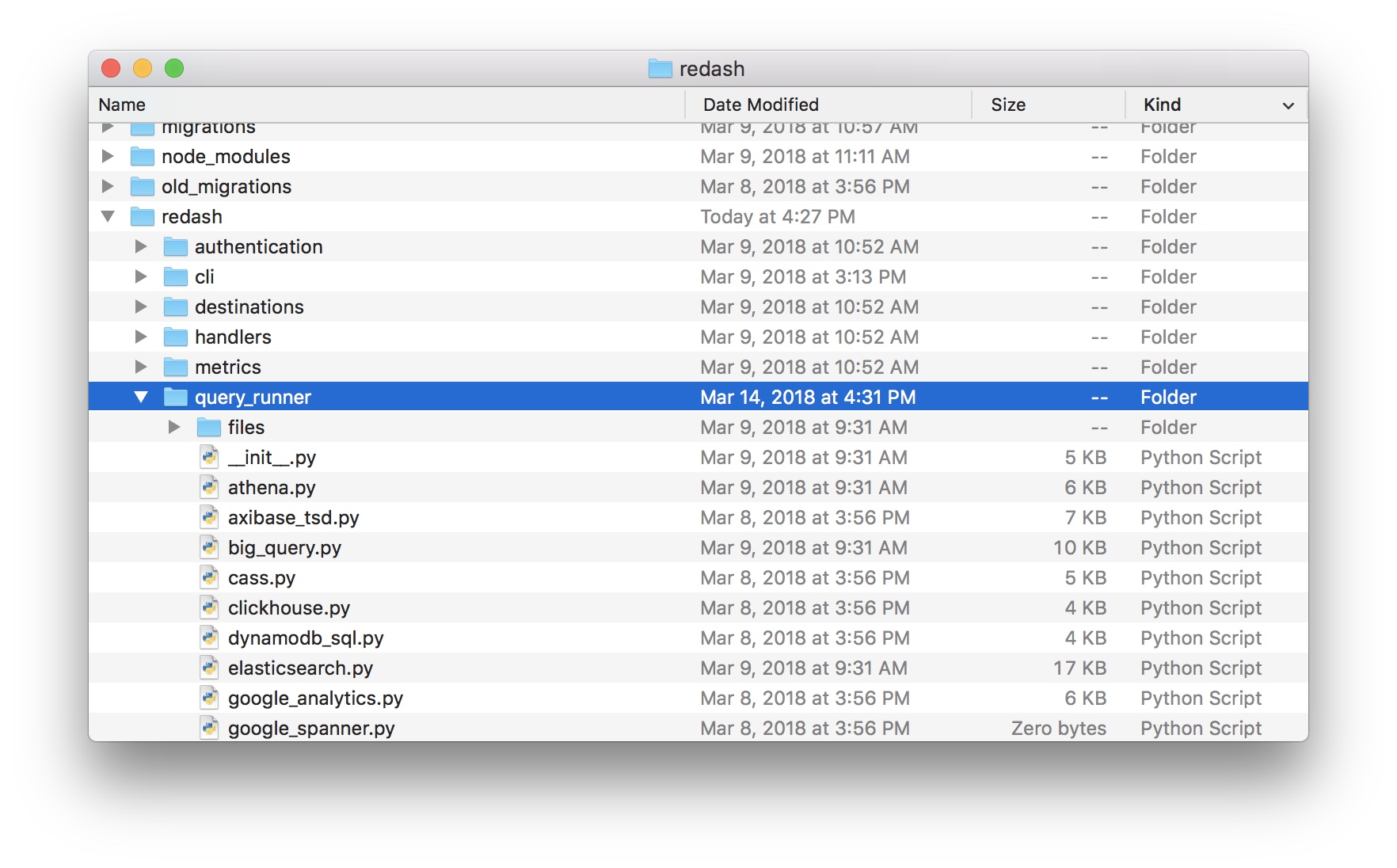
Before you can use the plugin, you need to enable it first. Please modify the default enabled plugin list defined in redash/settings.py:
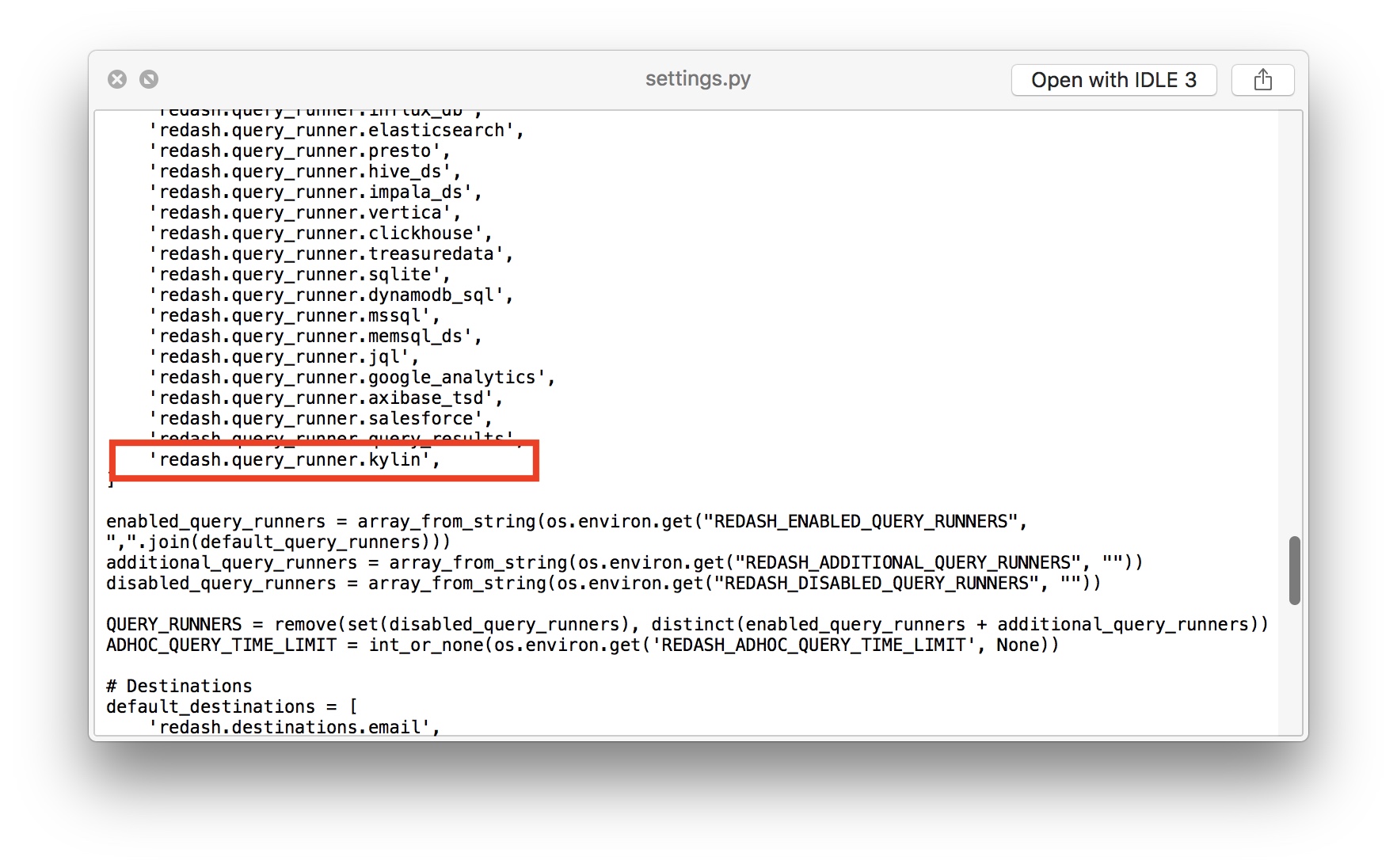
At last you have to rebuild the docker image (if you are using docker deployment) of redash and restart both server and worker of it. Currently, the redash-kylin plugin only supports the current stable version of redash (3.0.0) and 2.x version of Apache Kylin.
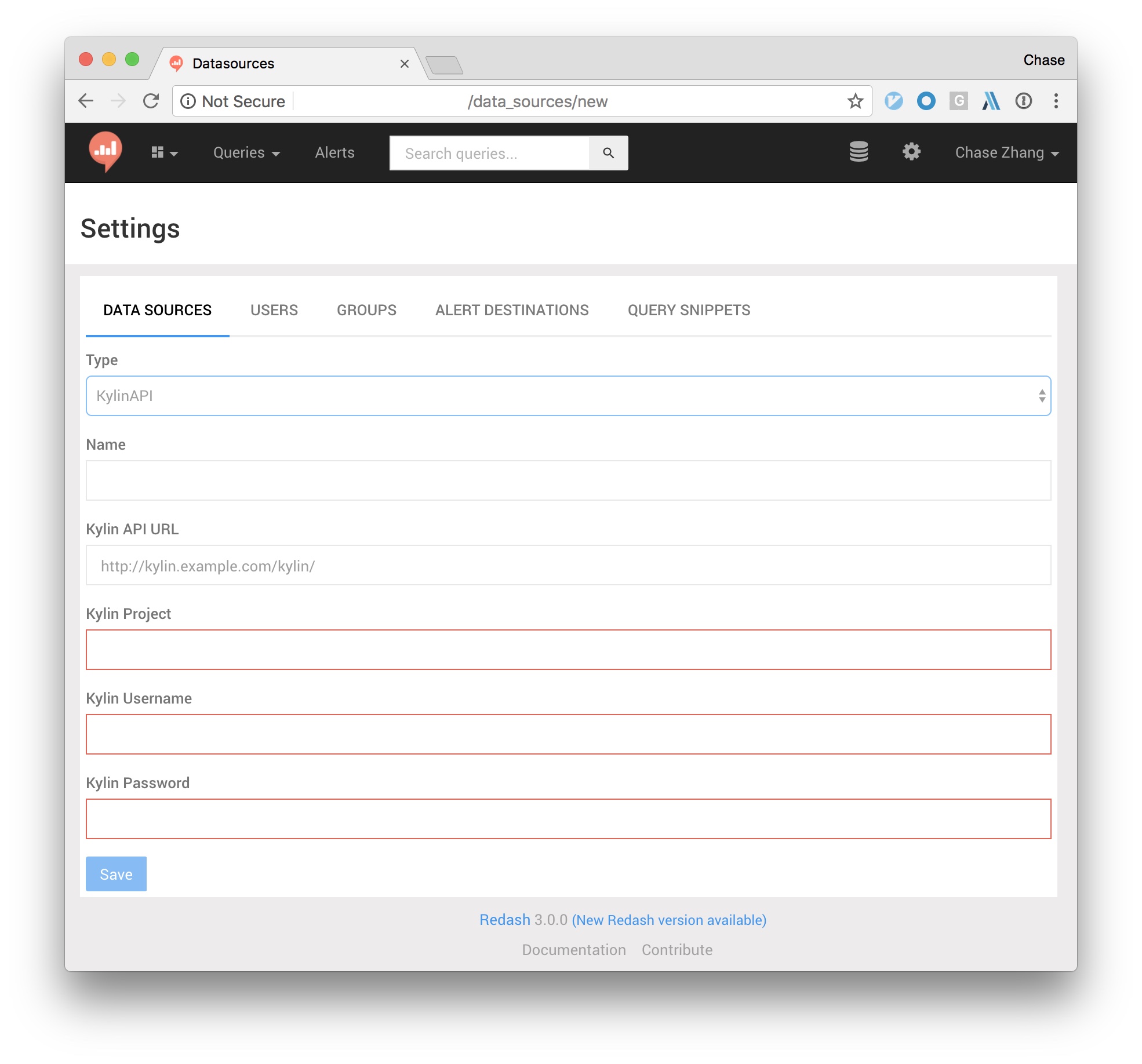
Once installed successfully, you’ll be able to find a KylinAPI data source type at the New Data Source page. To use it, just select that source type and fill in required fields. The redash-kylin plugin works by calling Kylin’s HTTP RESTful API, thus you should make sure your redash deployment has an access to your Kylin cluster (either job mode or query mode).
After a data source is setup and the connection is tested ok. You should be able to view schemas, run queries and make visualizations from tables in Kylin. Just type the SQL query in and get the result out. For more details about redash’s usage, please refer to redash’s documentation.
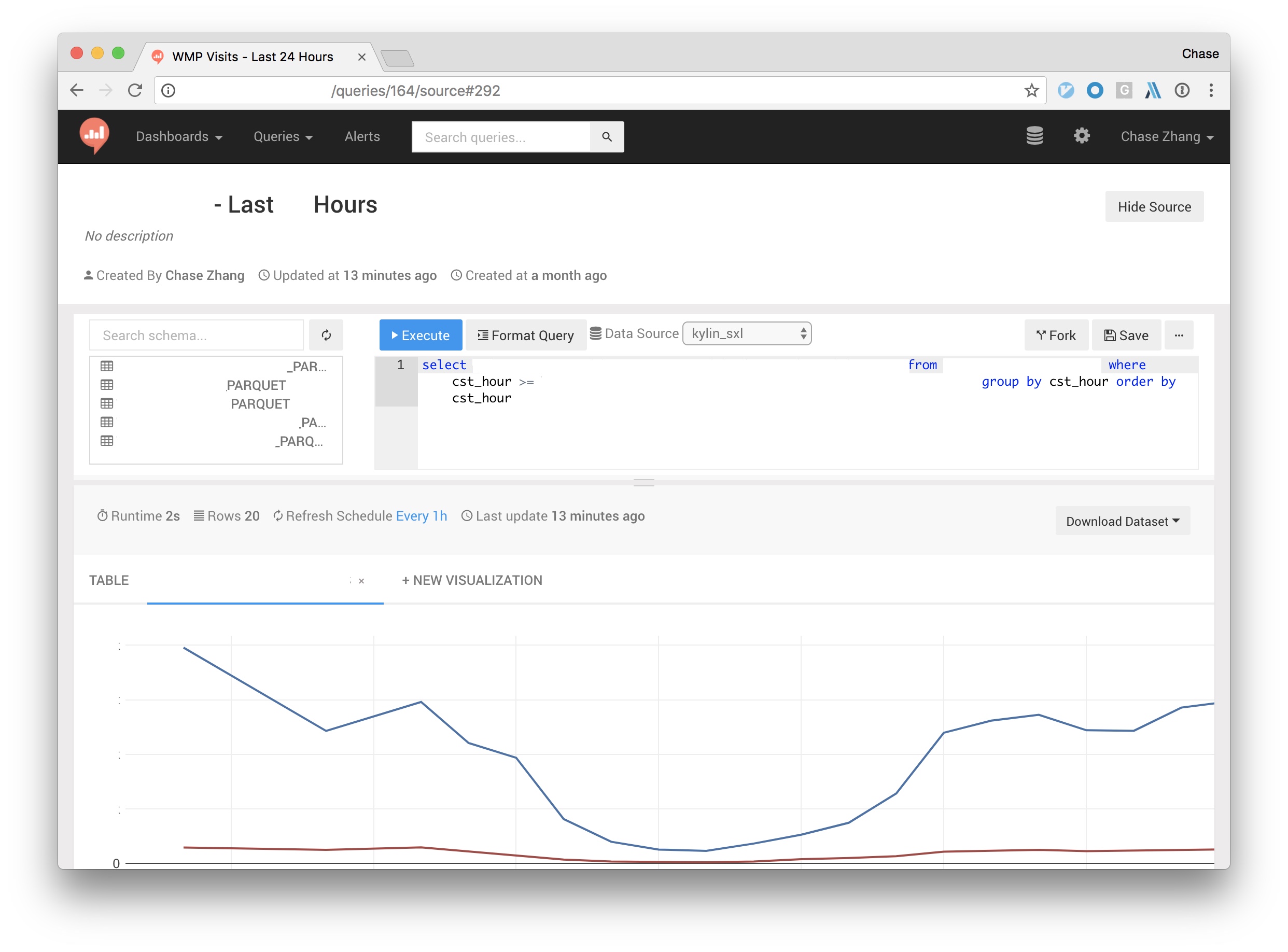
You can also add multiple data sources by setting different project names or different API URLs. It’s worth to mention that redash has an experiment function which supports making a query from former cached query results. Thus, once query results from different Kylin cluster has been imported, you’ll be able to join them together for richer data processing.
Wish you have a good time with Redash-Kylin!