
By-layer Spark Cubing
Before v2.0, Apache Kylin uses Hadoop MapReduce as the framework to build Cubes over huge dataset. The MapReduce framework is simple, stable and can fulfill Kylin’s need very well except the performance. In order to get better performance, we introduced the “fast cubing” algorithm in Kylin v1.5, tries to do as much as possible aggregations at map side within memory, so to avoid the disk and network I/O; but not all data models can benefit from it, and it still runs on MR which means on-disk sorting and shuffling.
Now Spark comes; Apache Spark is an open-source cluster-computing framework, which provides programmers with an application programming interface centered on a data structure called RDD; it runs in-memory on the cluster, this makes repeated access to the same data much faster. Spark provides flexible and fancy APIs. You are not tied to Hadoop’s MapReduce two-stage paradigm.
Before introducing how calculate Cube with Spark, let’s see how Kylin do that with MR; Figure 1 illustrates how a 4-dimension Cube get calculated with the classic “by-layer” algorithm: the first round MR aggregates the base (4-D) cuboid from source data; the second MR aggregates on the base cuboid to get the 3-D cuboids; With N+1 round MR all layers’ cuboids get calculated.
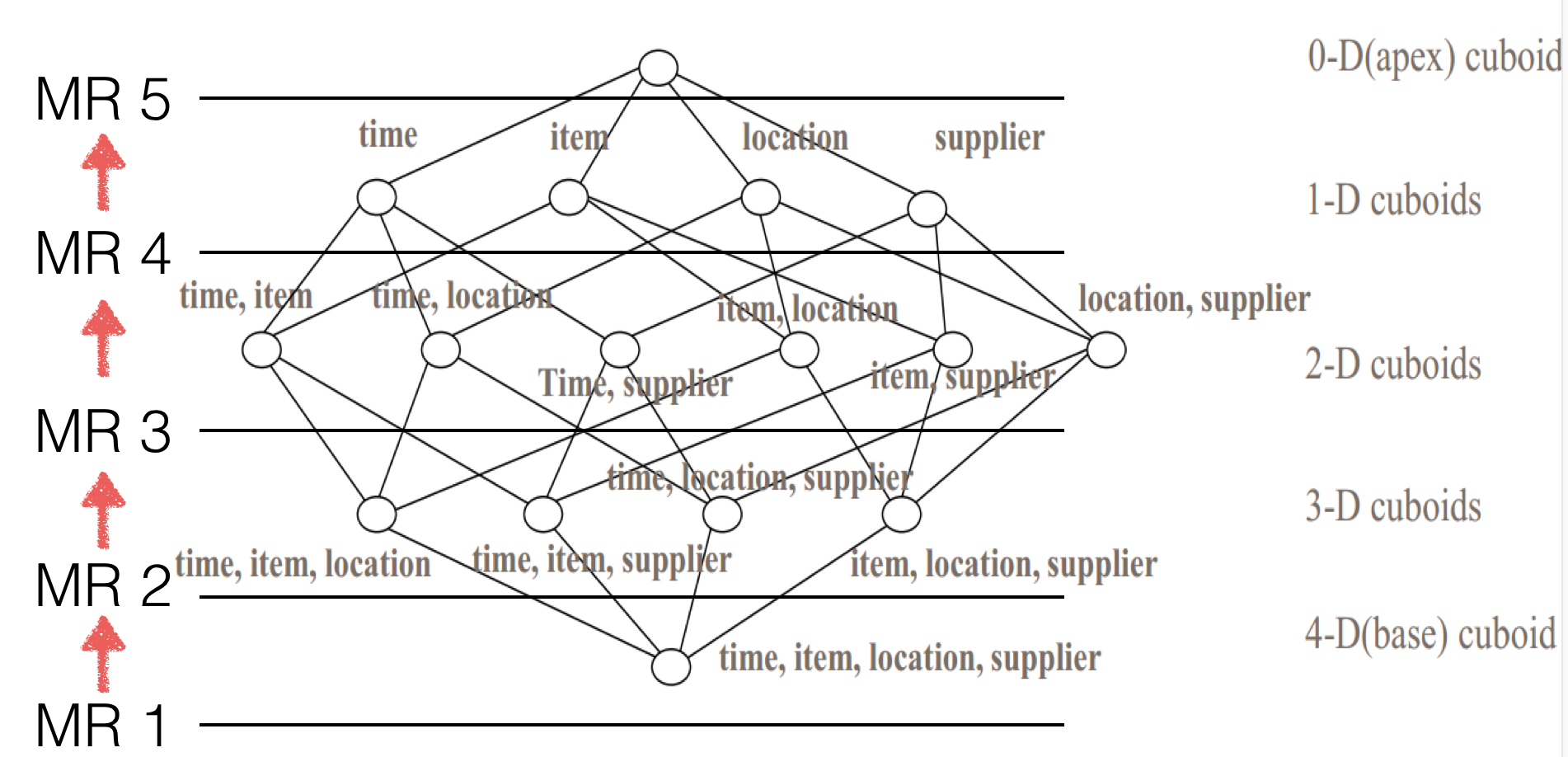
The “by-layer” Cubing divides a big task into a couple steps, and each step bases on the previous step’s output, so it can reuse the previous calculation and also avoid calculating from very beginning when there is a failure in between. These makes it as a reliable algorithm. When moving to Spark, we decide to keep this algorithm, that’s why we call this feature as “By layer Spark Cubing”.
As we know, RDD (Resilient Distributed Dataset) is a basic concept in Spark. A collection of N-Dimension cuboids can be well described as an RDD, a N-Dimension Cube will have N+1 RDD. These RDDs have the parent/child relationship as the parent can be used to generate the children. With the parent RDD cached in memory, the child RDD’s generation can be much efficient than reading from disk. Figure 2 describes this process.
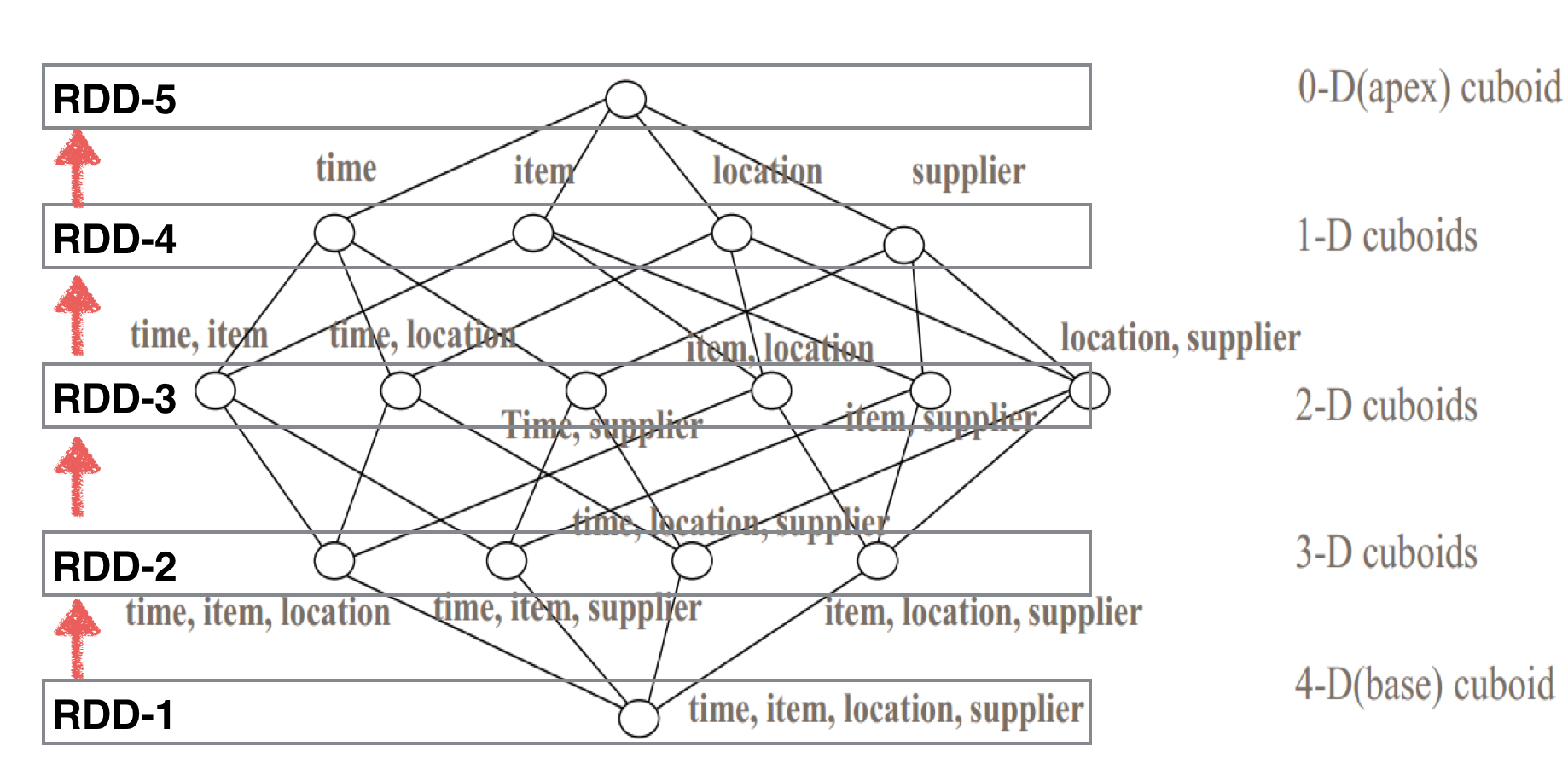
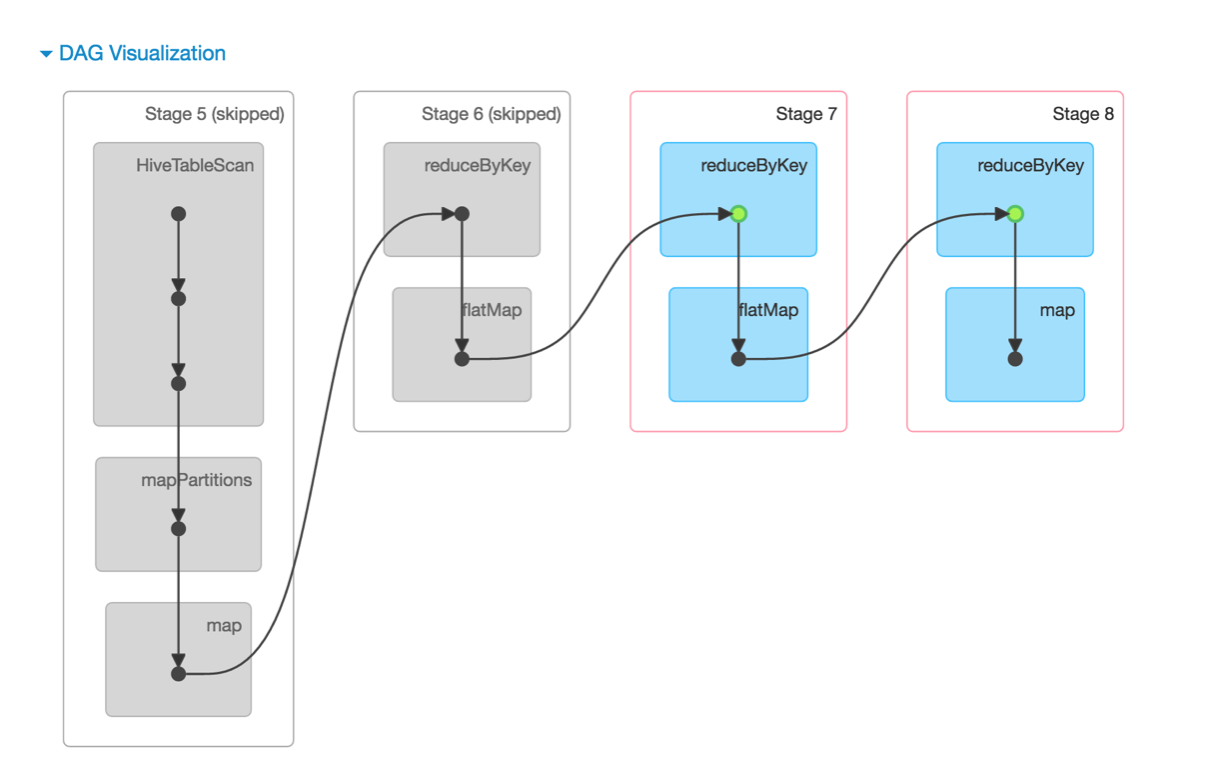
Figure 3 is the DAG of Cubing in Spark, it illustrates the process in detail: In “Stage 5”, Kylin uses a HiveContext to read the intermediate Hive table, and then do a “map” operation, which is an one to one map, to encode the origin values into K-V bytes. On complete Kylin gets an intermediate encoded RDD. In “Stage 6”, the intermediate RDD is aggregated with a “reduceByKey” operation to get RDD-1, which is the base cuboid. Nextly, do an “flatMap” (one to many map) on RDD-1, because the base cuboid has N children cuboids. And so on, all levels’ RDDs get calculated. These RDDs will be persisted to distributed file system on complete, but be cached in memory for next level’s calculation. When child be generated, it will be removed from cache.
We did a test to see how much performance improvement can gain from Spark:
Environment
- 4 nodes Hadoop cluster; each node has 28 GB RAM and 12 cores;
- YRAN has 48GB RAM and 30 cores in total;
- CDH 5.8, Apache Kylin 2.0 beta.
Spark
- Spark 1.6.3 on YARN
- 6 executors, each has 4 cores, 4GB +1GB (overhead) memory
Test Data
- Airline data, total 160 million rows
- Cube: 10 dimensions, 5 measures (SUM)
Test Scenarios
- Build the cube at different source data level: 3 million, 50 million and 160 million source rows; Compare the build time with MapReduce (by layer) and Spark. No compression enabled.
The time only cover the building cube step, not including data preparations and subsequent steps.
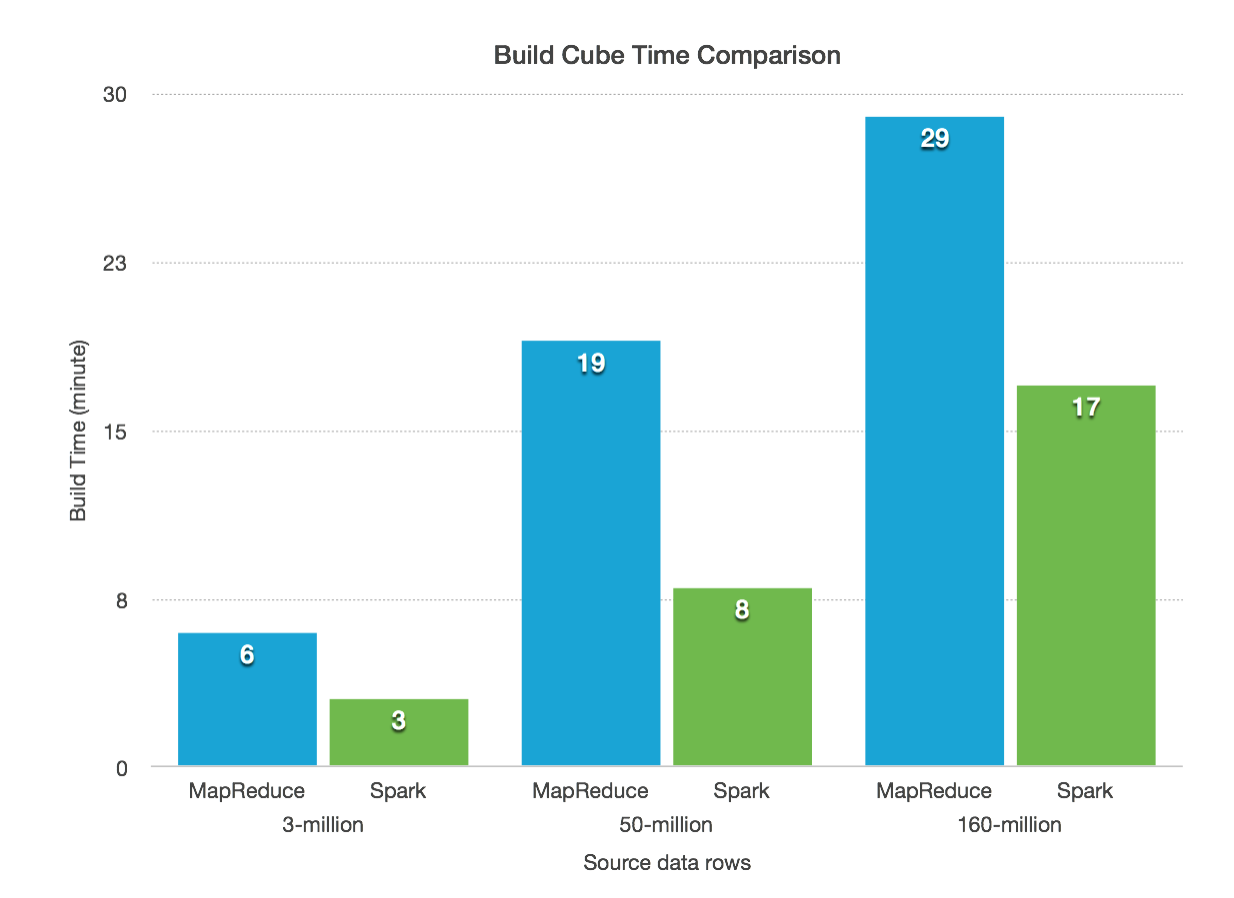
Spark is faster than MR in all the 3 scenarios, and overall it can reduce about half time in the cubing.
Now you can download a 2.0.0 beta build from Kylin’s download page, and then follow this post to build a cube with Spark engine. If you have any comments or inputs, please discuss in the community.