
New NRT Streaming in Apache Kylin
In 1.5.0 Apache Kylin introduces the Streaming Cubing feature, which can consume data from Kafka topic directly. This blog introduces how that be implemented, and this tutorial introduces how to use it.
While, that implementation was marked as “experimental” because it has the following limitations:
-
Not scalable: it starts a Java process for a micro-batch cube building, instead of leveraging any computing framework; If too many messages arrive at one time, the build may fail with OutOfMemory error;
-
May loss data: it uses a time window to seek the approximate start/end offsets on Kafka topic, which means too late/early arrived messages will be skipped; Then the query couldn’t ensure 100% accuracy.
-
Difficult to monitor: the streaming cubing is out of the Job engine’s scope, user can not monitor the jobs with Web GUI or REST API.
-
Others: hard to recover from accident, difficult to maintain the code, etc.
To overcome these limitations, the Apache Kylin team developed the new streaming (KYLIN-1726) with Kafka 0.10, it has been tested internally for some time, will release to public soon.
The new design is a perfect implementation under Kylin 1.5’s “plug-in” architecture: treat Kafka topic as a “Data Source” like Hive table, using an adapter to extract the data to HDFS; the next steps are almost the same as other cubes. Figure 1 is a high level architecture of the new design.
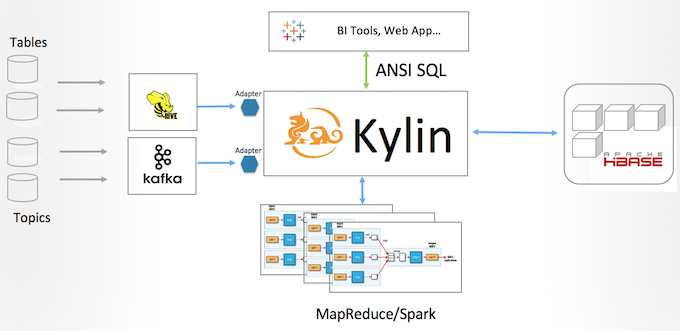
The adapter to read Kafka messages is modified from kafka-hadoop-loader, the author Michal Harish open sourced it under Apache License V2.0; it starts a mapper for each Kafka partition, reading and then saving the messages to HDFS; so Kylin will be able to leverage existing framework like MR to do the processing, this makes the solution scalable and fault-tolerant.
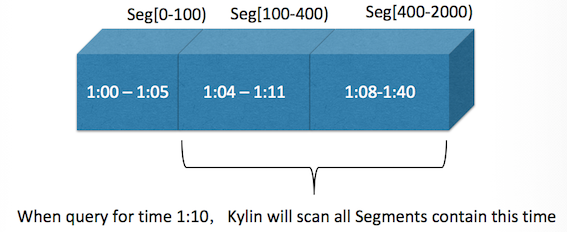
To overcome the “data loss” limitation, Kylin adds the start/end offset information on each Cube segment, and then use the offsets as the partition value (no overlap allowed); this ensures no data be lost and 1 message be consumed at most once. To let the late/early message can be queried, Cube segments allow overlap for the partition time dimension: each segment has a “min” date/time and a “max” date/time; Kylin will scan all segments which matched with the queried time scope. Figure 2 illurates this.
Other changes/enhancements are made in the new streaming:
- Allow multiple segments being built/merged concurrently
- Automatically seek start/end offsets (if user doesn’t specify) from previous segment or Kafka
- Support embeded properties in JSON message
- Add REST API to trigger streaming cube’s building
- Add REST API to check and fill the segment holes
The integration test result is promising:
- Scalability: it can easily process up to hundreds of million records in one build;
- Flexibility: you can trigger the build at any time, with the frequency you want; for example: every 5 minutes in day time but every hour in night time, and even pause when you need do a maintenance; Kylin manages the offsets so it can automatically continue from the last position;
- Stability: pretty stable, no OutOfMemoryError;
- Management: user can check all jobs’ status through Kylin’s “Monitor” page or REST API;
- Build Performance: in a testing cluster (8 AWS instances to consume Twitter streams), 10 thousands arrives per second, define a 9-dimension cube with 3 measures; when build interval is 2 mintues, the job finishes in around 3 minutes; if change interval to 5 mintues, build finishes in around 4 minutes;
Here are a couple of screenshots in this test, we may compose it as a step-by-step tutorial in the future:
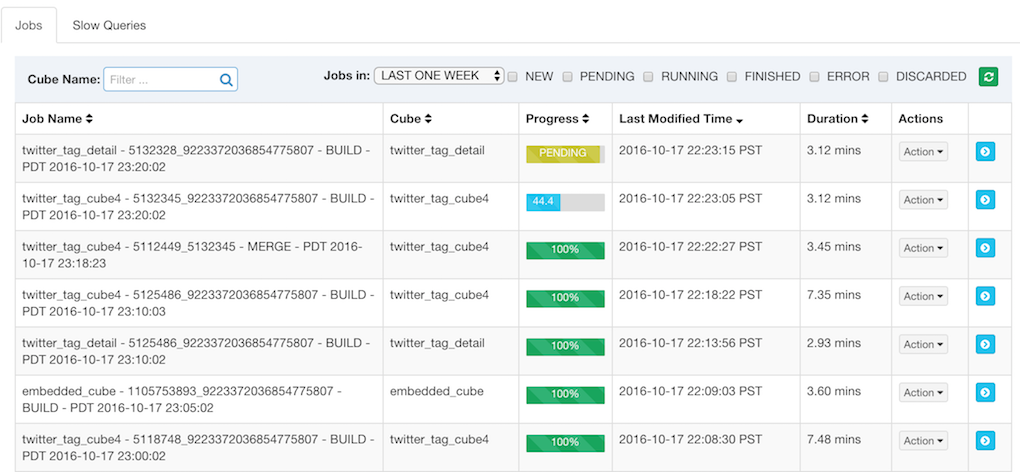
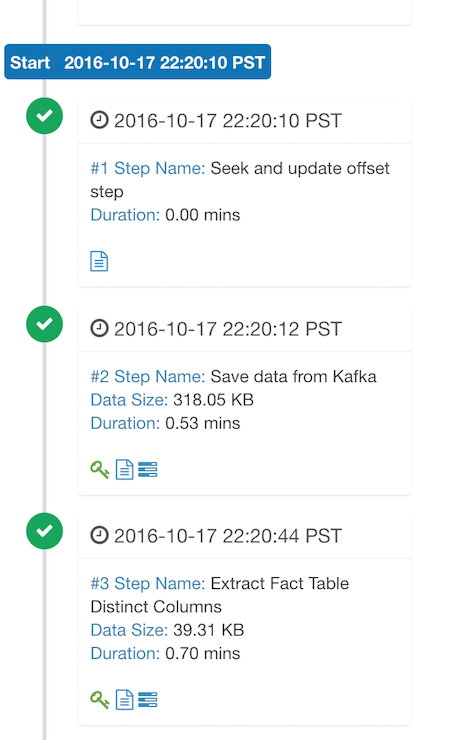
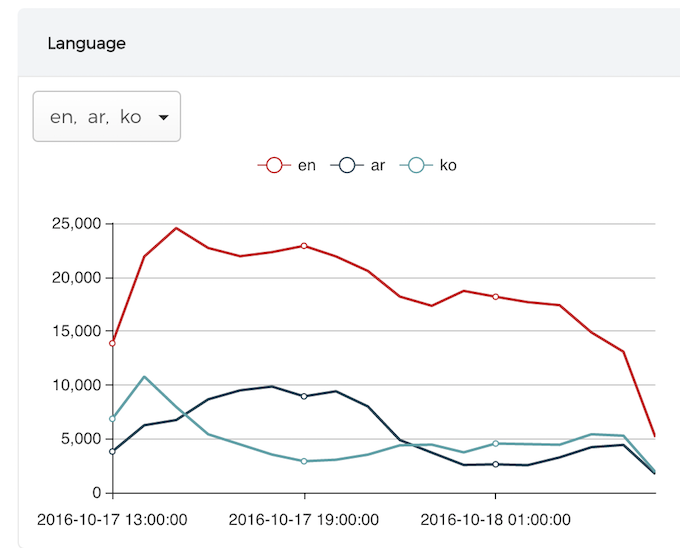
In short, this is a more robust Near Real Time Streaming OLAP solution compared with the previous version.
Now you can download a 1.6.0-SNAPSHOT build from Kylin’s download page, and then follow this tutorial to build a sample streaming cube.