
Dictionary in Kylin
Purpose of Dictionary
Dictionary is a classic compression technique that can greatly reduce the size of data. Kylin apply dictionary to all dimension values stored in cube.
Kylin’s requirement to dictionary:
- Compress cube size by storing IDs instead of real values
- Bi-way mapping of dimension values from/to IDs
- Preserving order to facilitate range query
- Minimal memory & storage footprint
Dictionary Design
Dictionary is implemented as a trie data structure. Dictionary ID (or “seq. no” below) is chosen in a way to preserve value order. Then at query time, predicate filters can be pushed down to storage and be evaluated on the IDs.
- Trie node are labeled by 1) number of values underneath; 2) is end of value or not
- Bi-way lookup between “value” <==> “seq. no” by top-down navigate
- The “seq. no” preserves value order and is a minimal integer for space advantage
- O(L) lookup time, where L=max(value length)
An example of a trie dictionary.

Memory structure
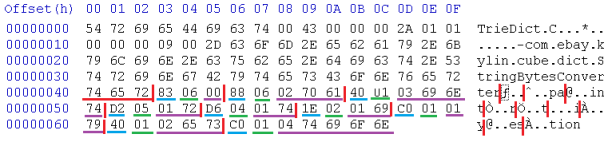
Once built, the dictionary is serialized into a chunk of bytes. This is how it stays in memory and also in file.
- Head
- magic, head len, body len, child_offset size, seq_no size, base ID, max value len, bytes converter
- Body
- a flattened trie, where each node is
- child offset (size specified in head)
- 1st MSB: isLastChild
- 2nd MSB: isEndOfValue
- no. values beneath (size specified in head)
- value len (1 byte unsigned)
- value bytes
- child offset (size specified in head)
- a flattened trie, where each node is
Benchmark result
We compared dictionary’s size and performance with HashMap and ID Based Array. It’s memory footprint is an order less and the throughput is very stable accross scales.
| HashMap (value=>id) | Dictionary (value=>id) | IdArray (id=>value) | Dictionary (id=>value) | ||
|---|---|---|---|---|---|
| 150K eng words footprint (bytes) | 18.8M | 1.7M | 11.1M | 1.7M | 1.4M raw size |
| 150K eng words throughput (acc/s) | 13M | 1.9M | 150M | 1.96M | 31 max value len |
| 6.6K categories footprint (bytes) | 0.94M | 0.13M | 0.58M | 0.12M | 0.1M raw size |
| 6.6K categories throughput (acc/s) | 26M | 2.0M | 98M | 2.0M | 30 max value len |
| 6 words footprint (bytes) | 792B | 168B | 416B | 168B | 33B raw size |
| 6 works throughput (acc/s) | 68.5M | 14.7M | 714M | 11.1M | 9 max value len |
Cache layer
To achieve maximum lookup throughput, a cache layer (HashMap or IdArray) sits on top of dictionary using weak reference. The cache could be gone when memory runs short, then dictionary will be hit directly.
